

Estamos quase concluindo o Business Intelligence – Do Problema Ao Dashboard. Sendo assim, hoje, entenderemos qual o mecanismo por trás do ETL, utilizando a ferramenta Pentaho. Então, se faltou ver alguma etapa anterior, pode conferir nos links abaixo o caminho que percorremos até chegar aqui:
- Introdução ao Business Intelligence – Do Problema Ao Dashboard
- Ambiente de Desenvolvimento para Business Intelligence
- Definições para Projetos de Business Intelligence
- Linguagem SQL e os Bancos de Dados Relacionais
- Modelagem de Dados para Business Intelligence
Veremos agora o que nos aguarda neste artigo. Primeiramente veremos alguns conceitos de ETL, conhecer um pouco mais a ferramenta Pentaho, aprender a criar as transformações de dimensões e fatos com os componentes do Pentaho e por fim, construiremos a ETL do projeto de BI do Dados ao Cubo.
1. O que é ETL?
O ETL (Extract, Transform e Load), em tradução livre Extração, Transformação e Carga, são três atividades básicas. A primeira atividade é extrair os dados da origem (banco de dados, planilhas, arquivos de texto entre outros). A segunda atividade é transformar os dados de acordo com a necessidade e especificações (por exemplo, no banco de dados está salvo sexo como M e F e vamos transformar para Masculino e Feminino). E por fim, a terceira atividade é carregar os dados no destino (por exemplo, carga no data warehouse). Abaixo a ilustração desse processo.
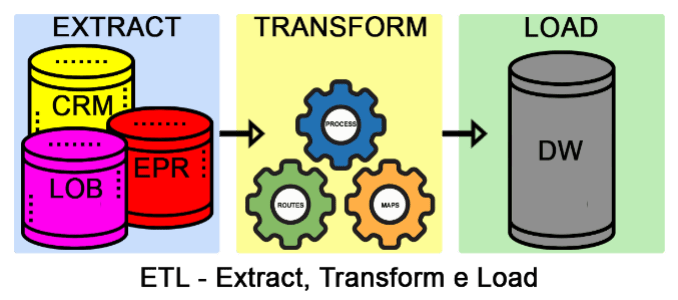
Para dar agilidade nesse processo e facilitar a manutenção, surgem as ferramentas de ETL. Com as ferramentas de ETL, podemos construir pipelines de uma ponta a outra de uma forma mais simples. O Pentaho é uma das ferramentas que fazem esse processo. Assim poderemos criar um modelo de ETL e executar sempre que for preciso carregar novos dados ou atualizar os dados já carregados.
2. O que é o Pentaho?
O Pentaho é uma suíte de soluções para BI open source. Uma dessas soluções é o Pentaho Data Integration ou PDI (para os mais íntimos), também conhecido pelo codinome Kettle. Com o PDI é possível criar soluções completas de ETL.
Dessa forma, poderemos extrair os dados do banco relacional. Em seguida, transformar conforme a necessidade do negócio. E por fim, carregar os dados no modelo multidimensional. Dessa forma, será possível gerar as dimensões e fatos. Agora, veremos na prática os componentes do Pentaho.
3. Componentes do Pentaho
Para construir o ETL do projeto de BI do Dados ao Cubo, precisaremos de componentes do Pentaho. Isso é só uma pontinha do que o Pentaho faz.
3.1. Repository Manager
O primeiro componente que veremosé a configuração do repositório do pentaho. É neste repositório que ficarão salvos todos os arquivos criados pelo pentaho. Então vejamos como realizar esta configuração.
Configurando o repositório: Connect > Repository Manager > Add > Other Repositories > File Repository
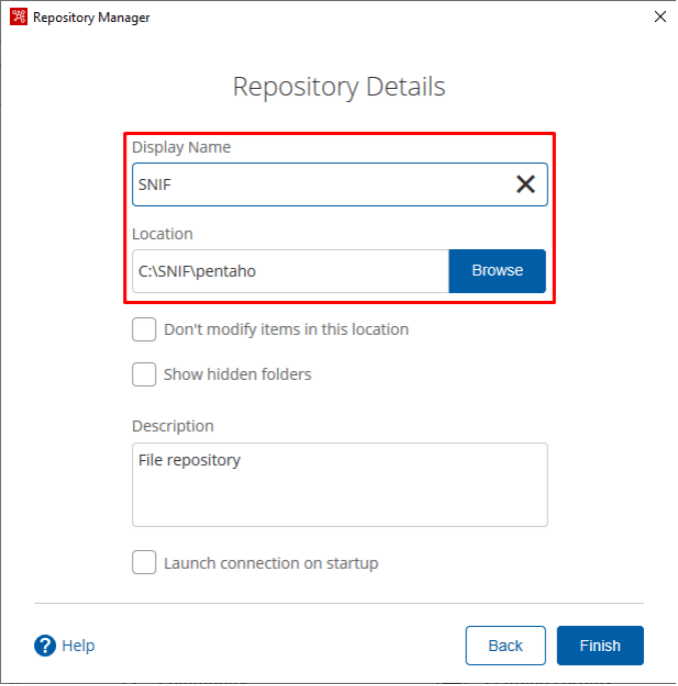
No pop-up acima, se faz necessário informar o nome que será apresentado para conexão e o caminho onde os arquivos do pentaho serão salvos. Quando acessar novamente, basta se conectar ao repositório já criado. Finalizada a configuração do repositório, já podemos criar uma transformação.
3.2. Transformation
As transformações, são o coração do ETL. Após sua criação, adicionaremos os steps (componentes do Pentaho) e cada um tem a sua função na transformação dos dados. Para criar uma transformação: File > Novo > Tranformação
Após criada a transformação poderemos inserir os steps (componentes) que realizam as transformações. Veremos a seguir os detalhes de alguns componentes. Mas antes, vamos configurar a conexão com o banco de dados, pois precisaremos deles mais à frente nas transformações.
3.3. Database Connection
A conexão é responsável por fazer a comunicação com o banco de dados, tornando possível fazer as operações de inserção, atualização, delete e muitas outras. Criando uma conexão com banco de dados: File > Novo > Database Connection
Em seguida, as configurações de acordo com o tipo de banco de dados:
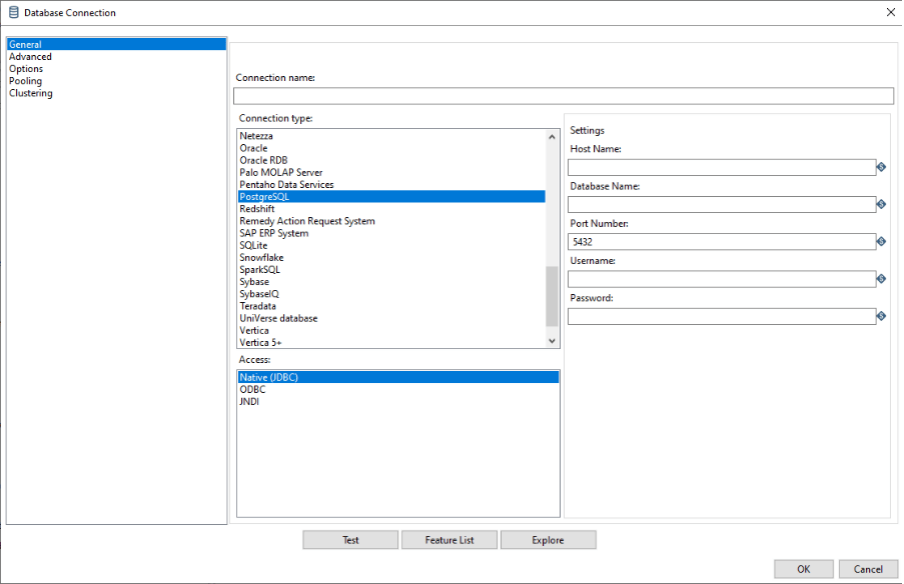
Após selecionar o tipo do banco de dados e a forma de acesso, será preciso informar alguns detalhes importantes: o nome da conexão, do host, do banco de dados, a porta de conexão, além de usuário e senha.
Resumindo o que fizemos até aqui, configuramos o repositório do Pentaho, criamos uma transformação e configuramos a conexão com o banco de dados, podemos seguir então para os componentes.
3.4. CSV File Input
Pode ser preciso inserir dados de arquivos de texto, como o conhecido .csv. Para isso o Pentaho tem um componente de nome CSV File Input para essa operação. Vejamos os detalhes.
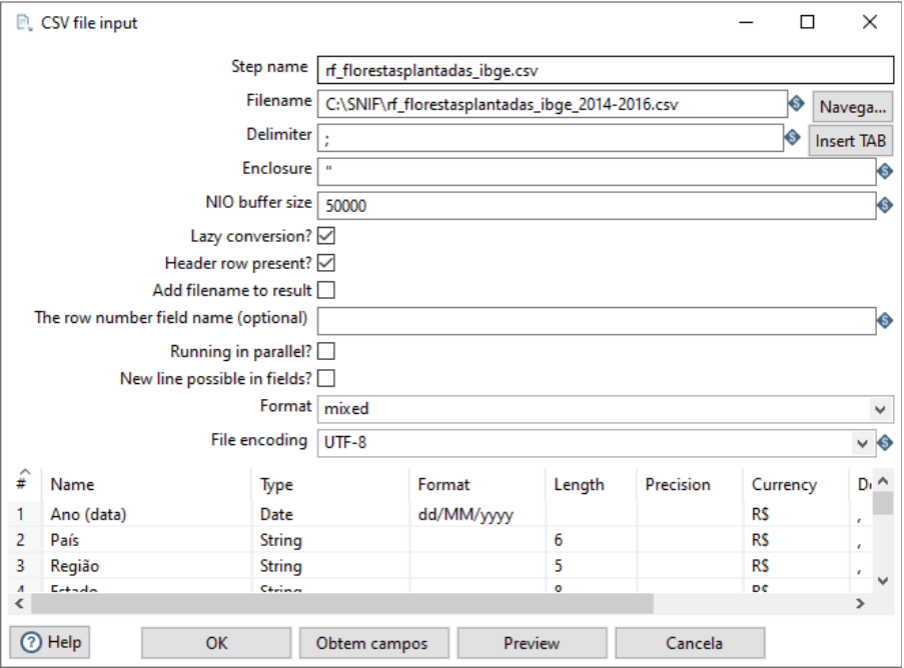
Para este caso acima, inserimos algumas informações necessárias para extração dos dados. Step name, aqui informamos o nome a ser exibido como identificação do step na transformação que estamos criando. No campo Filename, iremos informar o caminho completo do arquivo, inclusive a sua extensão. O Delimiter, vai identificar os delimitadores das colunas do arquivo. Um outro campo importante é o File encoding, onde informamos a codificação do texto.
Para finalizar, o botão Obtém campos, vai buscar as colunas com os tipos de dados e mais algumas configurações dos dados. Pode ser necessário utilizar outras opções da configuração, conforme os dados para extração.
3.5. Microsoft Excel Input
As planilhas de Excel são muito comuns nas empresas. Sempre que houver necessidade de input de dados que estão em planilhas, para esse problema vamos usar o step Microsoft Excel Input. Vejamos os detalhes do componente.
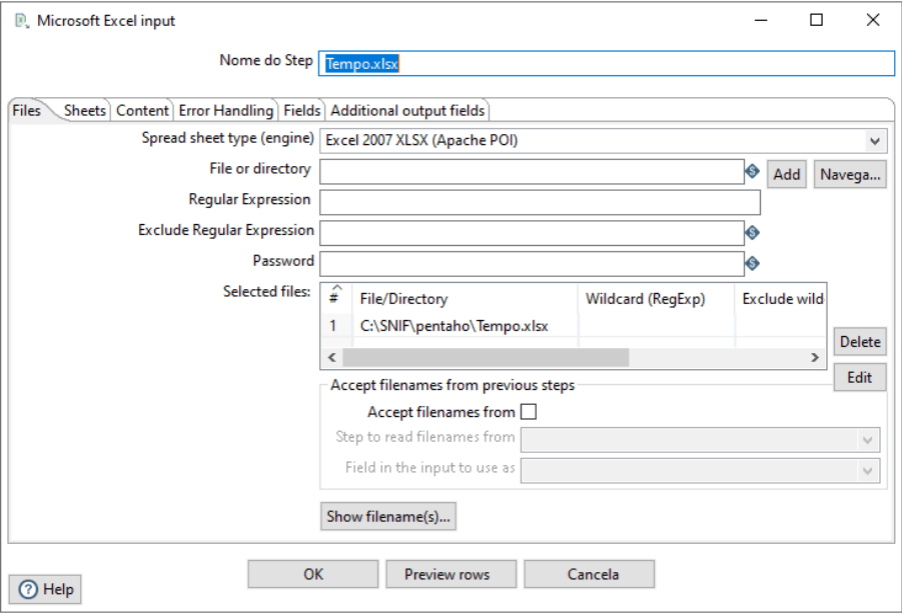
Mais uma vez, o Step name leva o nome a ser exibido como identificação do step na transformação. Para localizar o arquivo, vamos informar o File or directory em seguida, utilizar o botão Add e o arquivo vai aparecer em Selected Files. Na aba Sheets vamos informar o nome da planilha dentro do arquivo. Para finalizar, em Fields, vamos informar as colunas da planilha.
3.6. Table Input
Os bancos de dados são as maiores fontes de dados para projetos de BI. Dessa forma, podemos extrair informações de diversos sistemas das empresas, por exemplo: ERP, CRM ou qualquer outro sistema que tenha um banco de dados. Temos no Pentaho o componente Table Input para auxiliar nessa tarefa. Vamos aos detalhes.
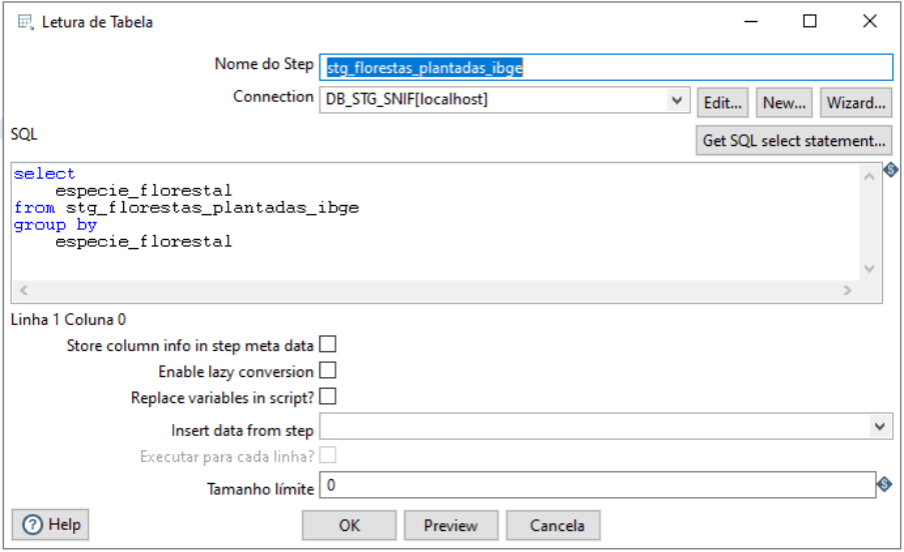
Começamos com o Step name informando o nome a ser exibido como identificação do step. Lembra da conexão com o banco de dados que mostramos no item 6.3.3.? Agora podemos selecioná-la no campo Connection. Com a conexão informada, podemos informar o código SQL que vai extrair do banco de dados as informações que precisamos. Podemos utilizar o botão Preview para visualizar uma prévia dos dados, é também uma forma de validar se a consulta SQL está com algum erro.
3.7. Select Values
Ao extrair dados, seja com o Microsoft Excel Input, Table Input ou qualquer outro componente de input de dados, pode ser necessário selecionar apenas alguns valores, ou simplesmente renomear algum campo. Para isso utilizamos o Select Values, vejamos os detalhes do componente.
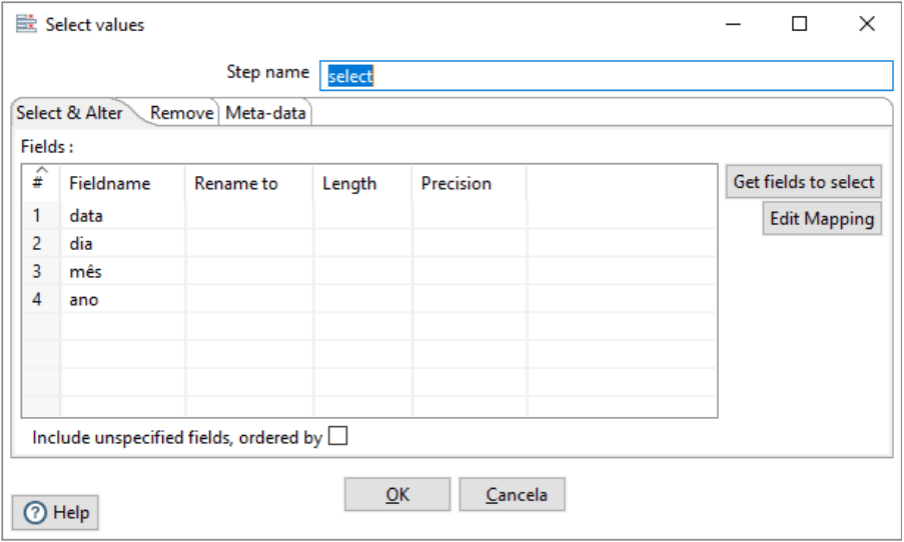
Como sempre, o Step name para o nome a ser exibido como identificação. O botão Get fields to select, exibe todos os Fields que estão ligados ao componente. Então, é possível fazer a seleção necessária, ou os ajustes que forem precisos (Renomear, tamanho do campo e precisão).
3.8. Dimension Lookup/Update
Para as cargas das dimensões o Pentaho tem um componente específico para essa tarefa. O Dimension Lookup/Update, faz tanto a inserção de novos dados nas dimensões, quanto atualizações dos dados das dimensões já carregadas. Vejamos os detalhes da configuração do componente.
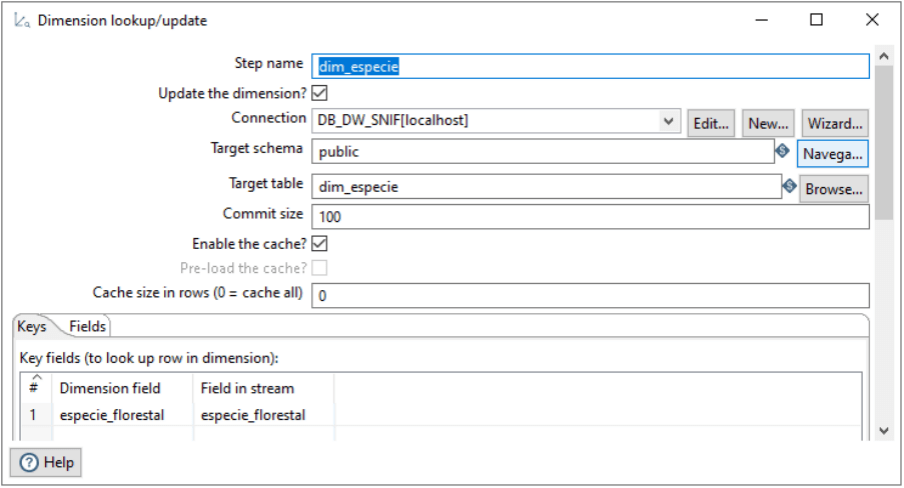
Sempre o Step name para configurar o nome a ser exibido como identificação. Depois, precisamos checar se o campo Update the dimension está marcado, informando que a dimensão vai ser atualizada. A Connection é para informar qual conexão com o banco de dados que vamos utilizar. Os campos Target schema e Target table, são as informações da identificação da tabela no banco de dados. Na aba Keys, vamos identificar a coluna chave da dimensão, já na aba Fields, temos a identificação das colunas que podem ser atualizadas. Ainda não acabamos com step da dimensão.
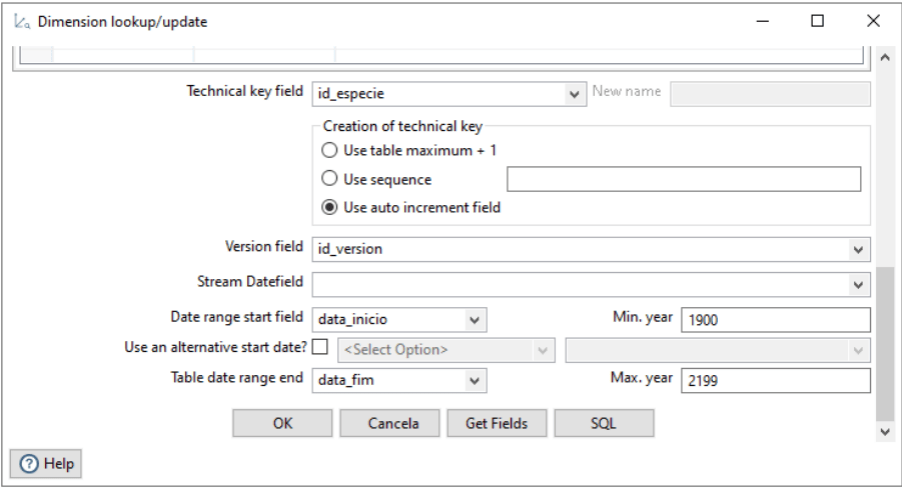
Agora precisamos definir uma chave para a tabela de dimensão, através do campo Technical key field. A forma como vamos preencher essa chave vai ser escolhida no campo Creation of technical key, selecionamos a forma auto incremental. Os campos, Version field, Date range start field e Table date range end são para controle de atualizações da dimensão.
3.9. Database Lookup
Quando vamos inserir dados nas tabelas fatos, precisamos identificar as dimensões presentes. Dessa forma, podemos inserir os dados da tabela fato e todas as relações com as dimensões. Para isso vamos utilizar o componente Database Lookup. Veremos como configurar.
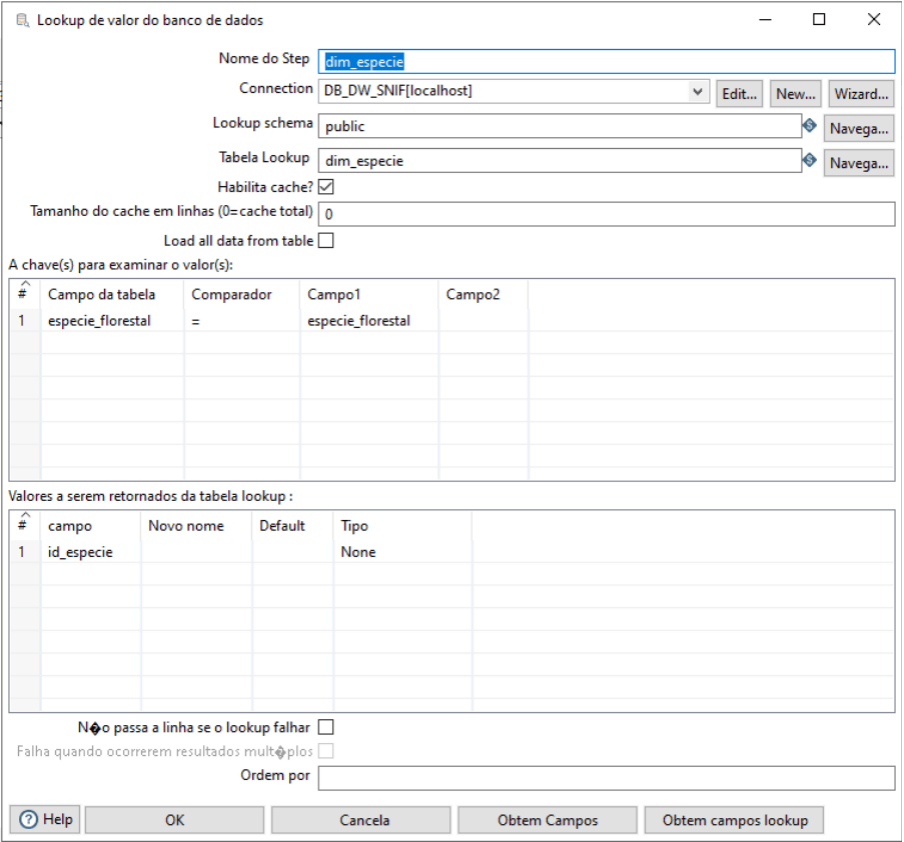
Identificamos o nome a ser exibido no Step name. Em seguida, a Connection é para informar qual conexão com o banco de dados que vamos utilizar. Os campos Target schema e Target table, são as informações da identificação da tabela no banco de dados. Observe que os campos Connection, Target schema e Target table já vimos em componentes anteriores e tem a mesma função. Em A chave(s) para examinar o valor(s): é onde vamos informar os campos a serem checados e em Valores a serem retornados da tabela lookup: vamos informar o valor que vai ser retornado.
Para o nosso exemplo acima, utilizamos a tabela dim_especie onde temos a coluna especie_florestal, é a mesma coluna que temos na consulta para gerar a tabela fato. Mas precisamos gravar na tabela fato a identificação da espécie (id_especie), então esse componente faz exatamente operação.
3.10. Table Output
Finalmente, o último componente que iremos utilizar. O Table Output insere os dados da transformação em um banco de dados. É o componente que será utilizado para inserir os dados em nossa tabela fato. Vamos às configurações.
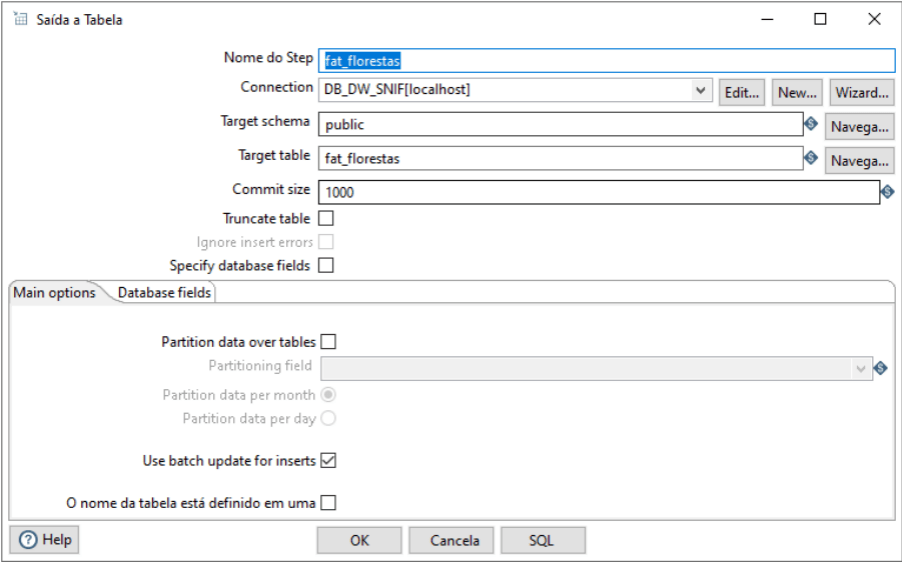
Configura o Step name informando o nome a ser exibido como identificação. Seguimos para a Connection, Target schema e Target table que já vimos em alguns componentes anteriores e tem exatamente a mesma função. A função Truncate table, pode ser útil caso seja necessário limpar a tabela antes de inserir novos dados.
Agora, já conhecemos todos os componentes que precisaremos. Vendo cada um de forma separada podem ter surgido algumas dúvidas, mas veremos que na prática são de fácil entendimento. Sendo assim, juntaremos todos eles na ETL do nosso projeto.
4. ETL na Prática no Projeto de Business Intelligence do Dados ao Cubo
O nosso projeto ficou estruturado em três etapas. Como pegamos os dados no portal de dados abertos em CSV. Primeiramente iremos carregar esses dados no postgreSQL. Em seguida, faremos a carga na staging area, seguindo as boas práticas de ETL. E por fim, carregaremos nossas dimensões e a fato. Vamos às transformações do projeto.
4.1. Carga CSV para Banco de Dados
Após o download do arquivo CSV no site dos dados abertos, utilizaremos os componentes: CSV File Input, para extrair os dados de um arquivo CSV; Select Values, para selecionar as colunas desejadas e Table Output, para carregar os dados em uma base de dados.

Dessa forma temos os dados carregados em um banco de dados. Já podemos seguir para o próximo passo.
4.2. Carga Banco de Dados Staging Area
Com os dados carregados no banco de dados, vamos usar os componentes: Table Input, para extrair os dados de um banco de dados; Select Values, para selecionar as colunas desejadas e Table Output, para carregar os dados em uma base de dados.

Usamos a seguinte consulta SQL no componente Table Input, para extrair os dados:
select * from rf_florestasplantadas_ibge
Dessa forma carregamos os dados em um banco de dados da staging area. Vamos para o próximo nível.
4.3. Carga Dimensão Espécie
Com a nossa staging area carregada, vamos usar os componentes: Table Input, para extrair os dados de um banco de dados; Select Values, para selecionar as colunas desejadas e Dimension Lookup/Update, para carregar os dados em uma dimensão.

Precisamos de uma consulta SQL no componente Table Input, para identificar os dados da nossa dimensão:
select especie_florestal from stg_florestas_plantadas_ibge group by especie_florestal
Então, já temos a nossa primeira dimensão carregada. Vamos a próxima.
4.4. Carga Dimensão Localização
Mais uma vez extraindo dados da staging area, vamos usar os componentes: Table Input, para extrair os dados de um banco de dados; Select Values, para selecionar as colunas desejadas e Dimension Lookup/Update, para carregar os dados em uma dimensão.

Mais uma consulta SQL no componente Table Input, agora para a dimensão de localização.
select municipio ,municipio_uf ,estado ,uf ,regiao ,pais ,latitude ,longitude from stg_florestas_plantadas_ibge group by municipio ,municipio_uf ,estado ,uf ,regiao ,pais ,latitude ,longitude
Estamos com quase todas as dimensões carregadas, vamos a última.
4.5. Carga Dimensão Tempo
Desta vez os dados não têm origem da staging area, vamos extrair de um arquivo excel, vamos usar os componentes: Microsoft Excel Input, para extrair os dados de um arquivo xlsx; Select Values, para selecionar as colunas desejadas e Dimension Lookup/Update, para carregar os dados em uma dimensão.
Abaixo temos uma amostra do que temos no arquivo excel, que vai gerar a dimensão de tempo.
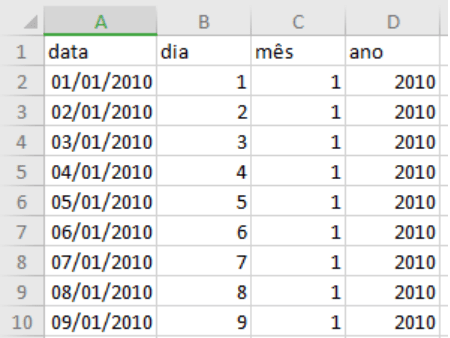
Finalizamos as cargas das nossas dimensões, então vamos carregar a fato.
4.6. Carga da Fato Florestas
Os dados também são de origem da staging area, vamos usar os componentes: Table Input, para extrair os dados de um banco de dados; Database Lookup, para trocar os dados da origem dos dados, pelas chaves das dimensões carregadas anteriormente; Select Values, para selecionar as colunas desejadas e Table Output, para carregar os dados em uma base de dados.
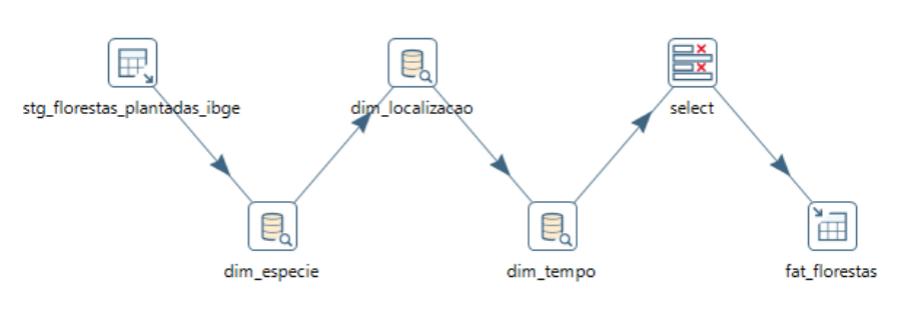
Então, essa é a consulta SQL no componente Table Input, para a fato:
select ano_data ,municipio_uf ,especie_florestal ,area_ha from stg_florestas_plantadas_ibge
Portanto, com todas as dimensões e fatos carregadas finalizamos a construção de ETL do projeto de BI do Dados ao Cubo. Além do que vimos por aqui, outras tarefas do processo de ETL, serão as cargas e monitoramento delas. Achou que só isso que fizemos e já estaria tudo resolvido? Não, aqui é só a criação do problema.
Brincadeiras à parte, todo esse processo que fizemos até aqui significa aproximadamente 80% do projeto de business intelligence. Então, cuide muito bem da modelagem, estruturação e transformação dos dados.
ETL com Pentaho ao Cubo
O nosso próximo passo e último da nossa série Business Intelligence – Do Problema Ao Dashboard será a cereja do bolo. A apresentação de tudo que construímos para o usuário final, então vamos caprichar. O DataViz ou visualização de dados é a beleza da coisa, é o que chama mais atenção, vamos com tudo.
Portanto, esse resumo de um projeto de BI que estamos construindo no Dados ao Cubo é para mostrar o potencial que o Business Intelligence pode gerar de resultado. Sendo assim, a ideia é sempre trazer de uma forma simplificada para facilitar a compreensão de todos. Espero que esses objetivos estejam sendo atingidos. Se está gostando do conteúdo, vamos levar para o maior número de pessoas possíveis que têm interesse na área de BI. Um grande abraço e até a próxima.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Agrupamento com scikit-learn
- Álgebra Linear com NumPy
- Geometria Analítica com SymPy
- Ciência de Dados para Mercado de Ações Parte I
- Ciência de Dados para Mercado de Ações Parte II
- Utilizando Python no Portal Brasileiro de Dados Abertos Parte I
- Criando Modelos de Machine Learning com Pipeline do Scikit-Learn
- Análise de Dados com Scikit Learn Python
Portanto, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
