

Você já parou para pensar na quantidade de dados que são processados a cada minuto por organizações, sejam elas pequenas, médias ou grandes; por bancos, públicos ou privados; e pelos órgãos públicos? E o que essas instituições fazem com esses dados? Ou como você poderia colaborar analisando estes dados para com o seu país? Já pensou em aplicar Python no Portal Brasileiro de Dados Abertos?
Este artigo marcará o início dos trabalhos voltados à análise e predição de dados utilizando Python no Portal Brasileiro de Dados Abertos do Governo Federal como background e direcionador de nossos trabalhos. Entretanto, informo aos leitores deste artigo que o mesmo não será focado em muita teoria, pois já existem milhares de artigos voltados para diversos assuntos, mas sim baseados em hands on, ou seja, prática, mão na massa e muitos questionamentos porque um bom cientista de dados precisa pensar, pensar e pensar.
Portal Brasileiro de Dados Abertos
Inicialmente, devemos compreender o que é o Portal Brasileiro de Dados Abertos e quais seriam suas verdadeiras intenções para que os dados pudessem ser disponibilizadas de forma transparente para a sociedade. Portanto, conforme transcrito do próprio site, o Portal é a ferramenta disponibilizada pelo governo para que todos possam encontrar e utilizar os dados e as informações públicas, promovendo impactos positivos sob os pontos de vista social e econômico (guardem estas palavras negritas, pois boa parte das nossas atividades estará focada nessas perspectivas).
Ademais, o acesso à informação está previsto na Constituição Federal e na Declaração Universal dos Direitos Humanos, como um instrumento para proporcionar ao cidadão um melhor entendimento do governo, no acesso aos serviços públicos, no controle das contas públicas e na participação no planejamento e desenvolvimento das políticas públicas.
Por fim, se quisermos ajudar o governo e principalmente a sociedade aqui apresentaremos um excelente caminho para dedicarmos pouco tempo de nossas vidas para prover resultados que poderão colaborar com outros estudos e com o crescimento de nosso país.
Dados são abertos quando qualquer pessoa pode livremente acessá-los, utilizá-los, modificá-los e compartilhá-los para qualquer finalidade, estando sujeito a, no máximo, a exigências que visem preservar sua proveniência e sua abertura. (OPEN KNOWLEDGE INTERNACIONAL apud BRASIL)
Selecionando nossa Primeira Experiência
Para aqueles que já visitaram o Portal já perceberam que temos quase 10 mil bases de dados disponíveis, umas com uma grande massa de dados e outras nem tanto. Mas, são bases de dados reais que se corretamente exploradas poderão gerar os resultados tão esperados. Sendo assim, para o nosso primeiro artigo iremos buscar nossa base dentro do dataset disponibilizado pelo Ministério da Saúde sobre a distribuição de respiradores aos Estados e Municípios. O conjunto de dados e o seu dicionário poderá ser visualizado e baixado no link. Agora que já introduzimos sobre o que é o Portal de Dados e onde obter nossa base é hora de partirmos para a prática.
Hands on com Python no Portal Brasileiro de Dados Abertos
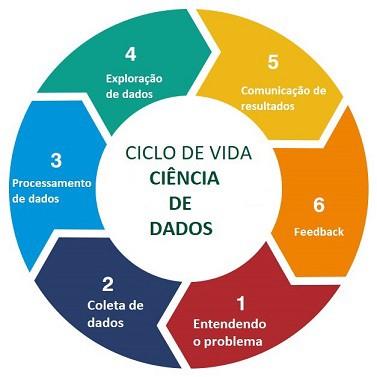
Como retratado no início do artigo, iremos trabalhar com muita mão na massa e pouca teoria, portanto é hora de arregaçar as mangas e codar! Vale ressaltar que iremos seguir o ciclo de vida de um projeto de ciência de dados para massificar como produzir excelentes resultados.
Só mais um lembrete: todo o estudo que será realizado foi feito utilizando o Google Colab, uma vez que é gratuito (para usuários do Google), além de não ser preciso fazer nenhuma instalação na sua máquina local.
Data Science (DS) ou Ciência de Dados é a arte de extrair conhecimento por meio dos dados para se tomar melhores decisões, realizar previsões e entender o passado.
Entendendo o Problema
Para resolver qualquer tipo de problema, primeiramente temos que entendê-lo. Assim, precisamos entender os gastos realizados com esses equipamentos para tomar medidas mais eficientes e, com isso, tentarmos elucidar alguns questionamentos ou propor linhas de ação para melhorar o controle e a gestão na aquisição destes respiradores.
Vamos levantar algumas questões relevantes acerca dessa problemática:
- Quanto tempo demorou para que o governo comprasse os primeiros respiradores?
- Qual foi o número de respiradores adquiridos para cada estado?
- Locais com maior número de populacional receberam mais respiradores?
Será que é possível responder esses questionamentos por meio da análise de dados utilizando a Python? É o que aprenderemos na continuidade deste e dos próximos artigos.
Coleta de Dados
Definido o problema, iremos até o Portal de Dados do Governo para buscar nosso conjunto de dados, neste caso, dados estruturados.
Importando as bibliotecas a serem utilizadas
# biblioteca Python que é usada principalmente para realizar cálculos em Arrays Multidimensionais import numpy as np # biblioteca Python que fornece ferramentas de análise de dados e estruturas de dados de alta performance import pandas as pd # biblioteca Python com fuso horário expandido e suporte à análise import datetime # biblioteca Python para geração de gráficos 2D from matplotlib import pyplot as plt # Para mostrar os gráficos no notebook %matplotlib inline
Com as bibliotecas importadas, podemos carregar os dados.
Obtenção do dataset (conjunto de dados)

df = pd.read_csv("http://sage.saude.gov.br/dados/repositorio/distribuicao_respiradores.csv")Processamento de Dados
Após a coleta dos dados e carregamento em um DataFrame, necessitaremos tratá-los antes de começar nossas análises. Portanto, é necessário estar atento a registros duplicados, faltantes, formatados de forma não convencional (ex.: campos de data), inválidos (ex.: idade negativa), inconsistências de cadastros.
Então, antes de continuarmos esta etapa, precisamos relembrar o nosso dicionário de dados.
- DATA: Data de solicitação de entrega à distribuidora
- FORNECEDOR: Nome da empresa fornecedora dos equipamentos;
- DESTINO: Estado de destino do respirador;
- ESTADO/MUNICIPIO: Tipo de unidade da federação que será o destino da entrega;
- TIPO: Tipo do equipamento;
- QUANTIDADE: Unidades entregues;
- VALOR: Valor total da entrega, em reais;
- DESTINATARIO: Entidade que recebeu o bem;
- UF: UF de entrega; e
- DATA DE ENTREGA: Data de entrega no destinatário.
Sendo assim, depois deste pequeno intervalo, vamos voltar a codar para concluirmos esta etapa.
# carregando uma amostra de 5 registros df.head()
Verificando uma amostra dos dados carregados
Análise: Os dados foram carregados dentro do DataFrame sem problemas.
Quantidade de registros
# quantidade de registros df.shape[0] > 1442
Análise: Temos uma base de dados com poucos registros. Existem vantagens e desvantagens como veremos nos próximos artigos.
Atributos do Dataframe
# enumerando os atributos constantes no dataframe df.columns > Index(['DATA', 'FORNECEDOR', 'DESTINO', 'ESTADO/MUNICIPIO', 'TIPO', 'QUANTIDADE', 'VALOR', 'DESTINATARIO', 'UF', 'DATA DE ENTREGA'], dtype='object')
Análise: Temos uma base de dados com poucos atributos o que facilitará correções e análises.
Verificando a existência ou não de campos com registros faltantes
# verificando existência de campos nulos df.isnull().sum()
Análise: A princípio não teremos muitos problemas com a nossa base de dados, uma vez que não há registros faltantes.
Verificando os Estados que receberiam os respiradores com o atributo “UF”
#verificando os estados atendidos len(df["UF"].unique())
Análise: Podemos verificar que há itens repetidos e temos um caractere que não representa um estado da nossa federação (“-“).
Verificando a quantidade de Estados que receberam os respiradores com o atributo “UF”
#verificando quantidade de estados atendidos len(df["UF"].unique()) > 31
Análise: Opa, 31 estados? O Brasil tem 26 estados mais o Distrito Federal, portanto vamos precisar corrigir as instâncias deste atributo. Só que as correções ficarão para o próximo artigo.
Verificando os Estados que receberiam os respiradores com o atributo “DESTINO”.
# verificando quantidade de estados atendidos df["DESTINO"].unique()
Análise: Mais um problema, desde quando o Líbano é um estado brasileiro? Esse dataset vai dar trabalho, mas o que seria a vida de um Cientista de Dados se não fossem os problemas a serem resolvidos?
Verificando a quantidade de Estados que receberam os respiradores com o atributo “DESTINO”
#verificando quantidade de estados atendidos len(df["DESTINO"].nunique()) > 28
Análise: Apesar de termos 27 estados e o resultado apresentado é de 28, o erro está na existência do “Líbano”.
Verificando os tipos de respiradores que foram adquiridos e entregues aos estados/munícipios
#verificando os tipos de respiradores adquiridos df["TIPO"].unique()
Análise: Apesar de termos apenas 4 tipos, deveremos entender o que cada um significa.
Verificando a quantidade de respiradores adquiridos por tipo
#verificando a quantidade de respiradores adquiridos por tipo df.groupby(['TIPO'])['QUANTIDADE'].sum()
Análise: Será que o quantitativo adquirido seria suficiente? Será que o tipo UTI seria mais importante do que o tipo TRANSPORTE ?
Verificando os fornecedores que receberam recursos
#verificando os fornecedores que receberam recursos df["TIPO"].unique()
Análise: Será que todos os fornecedores estão aptos a fornecerem tais equipamentos? O fornecedor é fabricante ou apenas um intermediário?
Quantitativo que cada fornecedor entregou
# quantitativo que cada fornecedor entregou df.groupby(['FORNECEDOR'])['QUANTIDADE'].sum()
Análise: Por que fornecedores que possuem o mesmo “nome” foram contabilizados separadamente? Foi erro na padronização dos campos?
Verificando a data de recebimento do primeiro e último pedido
# verificando a data de recebimento do primeiro pedido df["DATA"].sort_values()[0] > '19/04/2020' # verificando a data de recebimento do último pedido df["DATA"].sort_values(ascending=False)[0] > '07/08/2020'
Análise: As datas têm coerência, porém será que existiu demora em comprar os respiradores?
Verificando a primeira e última data de entrega dos equipamentos adquiridos
# verificando a primeira data de entrega df["DATA DE ENTREGA"].sort_values()[0] > '19/04/2020' # verificando a última data de entrega df["DATA DE ENTREGA"].iloc[[-1]].sort_values() > '08/08/2020'
Análise: As datas retornadas possui coerência (DD/MM/AAAA), porém será que existiu demora na entrega dos equipamentos pelos fornecedores?
Verificando o range dos quantitativos de equipamentos entregues e o total de equipamentos adquiridos
# verificando o range dos quantitativos de equipamentos entregues df["QUANTIDADE"].unique()
Análise: Temos um range de distribuição variando de 1 até 300.
# verificando a quantidade total de equipamentos comprados pelo Governo df["QUANTIDADE"].sum() > 10913
Análise: Será que este quantitativo é o suficiente para as necessidades do país?
Verificando o tipo de dado de cada atributo
#verificando o tipo de dados de cada atributo df.info()
Análise: Como podemos atestar há vários campos com tipos errados, como por exemplo o atributo VALOR que recebe a característica OBJECT e não FLOAT, portanto teremos que corrigir os tipos de vários atributos.
Sei que a vontade para continuarmos é grande, mas para que o conteúdo não fique muito extenso iremos dar uma break neste ponto e no próximo artigo daremos continuidade nas correções dos dados para avançarmos para a etapa de Exploração de Dados.
Python no Portal Brasileiro de Dados Abertos ao Cubo
Então, neste primeiro artigo conhecemos o Portal Brasileiro de Dados que é o ponto central para a busca e o acesso aos dados públicos no Brasil. Além disso, é uma grande oportunidade para evoluirmos como Cientista de Dados e como cidadão, uma vez que podemos esclarecer questões sociais e econômicas para propormos linhas de ação para ajudar o crescimento de nosso país.
Cumprimos até agora apenas 3 etapas das 6 etapas existentes para produção de um projeto de Ciência de Dados e já deu para notar que o trabalho é hercúleo, mas são ações necessárias para a entrega de um resultado coerente.
Muitos questionamentos foram levantados durante a fase de processamento de dados, bem como necessidade de correções no dataset, tudo com o propósito de avançarmos para a fase de exploração de dados, fase esta que se intensifica a necessidade de habilidades analíticas e criativas para pensar em ideias e hipóteses a serem validadas.
Portanto, nos próximos artigos, iremos aprofundar mais a análise desta base, utilizando o pandas, até a apresentação de nossos resultados em um dashboard.
Por fim, agradeço a oportunidade ofertada pela Dados ao Cubo e aguardo todos no próximo artigo.
Referências
- BRASIL. Controladoria-Geral da União. Portal da Transparência. Brasília: CGU, c2020. Disponível em: http://portaltransparencia.gov.br/. Acesso em: 25 ago. 2020.
- BRASIL. Ministério do Planejamento, Desenvolvimento e Gestão. Secretaria de Tecnologia da Informação. O que são dados abertos? Brasília: MPDG, [2020]. Disponível em: http://dados.gov.br/pagina/dados-abertos. Acesso em: 25 ago. 2020.
- BRASIL. Ministério do Planejamento, Desenvolvimento e Gestão. Secretaria de Tecnologia da Informação. Portal Brasileiro de Dados Abertos. Brasília: MPDG, [2020]. Disponível em: dados.gov.br. Acesso em: 25 ago. 2020.
- SEMINÁRIO INTERNACIONAL SOBRE ANÁLISE DE DADOS NA ADMINISTRAÇÃO PÚBLICA, 5., 2019, Brasília. Programa […]. Brasília: TCU: Enap, 2019. Disponível em: http://www.brasildigital.gov.br/brasil-digital/programa/. Acesso em: 25 ago. 2020.
- FUENTES, A. Hands-On Predictive Analytics with Python. Birmingham: Packt Publishing, 2018.
- MCKINNET, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython 2nd Edition. O’Reilly, 2017.
Conteúdos ao Cubo
Se você curtiu o conteúdo, aqui no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar. Sempre falando sobre o mundo dos dados!
- Geometria Analítica com SymPy
- Estatística Descritiva Univariada
- Análise Exploratória de Dados com Python Parte I
- Análise Exploratória de Dados com Python Parte II
- Bem Vindos ao Dados ao Cubo: Uma Introdução a Ciência de Dados
- Loops em Python
- Análise de Dados Poderosa com Polars em Python
- Descubra Como Utilizar o DBSCAN em Python para Análise de Dados
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Oficial do Exército Brasileiro e um aficionado por Ciência de Dados. Mestrando em Governança, Tecnologia e Inovação pela UCB; Pós-graduado em Ciências Militares, Bases Geo-Históricas, Educação a Distância, Engenharia de Sistemas, Ciência de Dados e Inteligência Artificial; possui MBA Gestão de Projetos e MBA Gestão Imobiliária; possuidor das seguintes certificações SAAC™, Kanban-ASC™, SFPC™, SFC™, SMC™, DEPC, ISPA Netowork e ISPA Linux.
