

Fala galera do mundo dos dados, hoje é dia de aprender as funções Spark joins, withColumn e concat_ws com Python. Continuando a série Fluxo de Dados com Spark! Hoje é dia de aprender mais algumas funções do Spark para aumentar a caixa de ferramentas. Ainda pensando em manipulação de dados para manipular as bases de dados.
Sendo assim, iremos apresentar como realizar joins e criar colunas com Spark. Para começar vamos criar os DataFrames. Sem mais enrolações, partiu prática com Dados ao Cubo.
Criar Dataframes com Spark
Primeiramente, iremos criar dois Dataframes como Spark. Para esta criação vamos utilizar os dois arquivos csv da imagem abaixo.
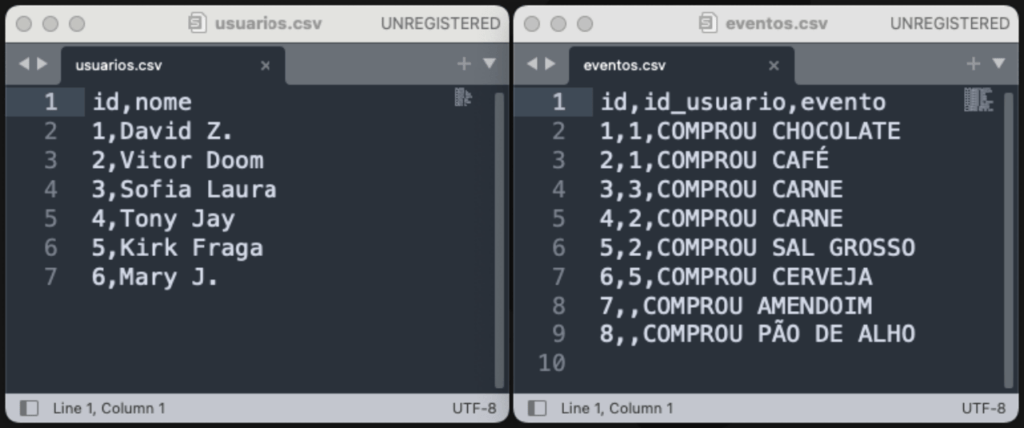
Com o código Python abaixo, será feita a leitura dos arquivos usuarios.csv e eventos.csv e criado os DataFrames df_usuarios e df_eventos.
from pyspark.sql import SparkSession, functions as f if __name__ == __main__: spark = SparkSession.builder.getOrCreate() df_usuarios = spark.read.option(header,True).csv(usuarios.csv) df_eventos = spark.read.option(header,True).csv(eventos.csv)
Com DataFrames criados, podemos partir para os Jones.
Juntar Dataframes com Spark
Utilizaremos dois DataFrames para exemplificar os joins df_usuarios: Este é um DataFrame representando dados de usuários e df_eventos: Este é um DataFrame representando dados de eventos dos usuário.
Com os joins é possível juntar várias tabelas a partir de uma coluna em comum entre elas. Aqui que vamos entender e praticar os famosos joins (left, right, inner e outer) que estão exemplificados na imagem abaixo.
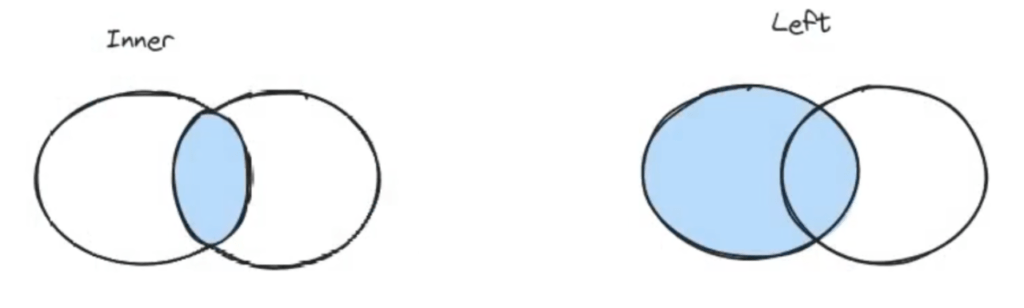

O método join realiza uma operação de junção (join) entre os DataFrames. Precisamos especificar a condição de junção, indicando qual a coluna são correspondentes nos DataFrames. Finalizando com o tipo do join, Então, vamos aos detalhes de cada um deles.
Left join com Spark
Utilizamos o Left join com Spark quando queremos todas as informações da tabela da esquerda e as correspondentes da tabela da direita, mesmo que não haja correspondência.
Faremos o join entre com df_usuarios e df_eventos. A condição de junção, será a coluna id em df_usuarios deve ser igual à coluna id_usuario em df_eventos. Finalizando com o left, indicando que é uma junção à esquerda, mantendo todas as linhas de df_usuarios e as correspondentes linhas de df_eventos, se houver.
df_usuarios.join(df_eventos,df_usuarios.id == df_eventos.id_usuario,left).show()
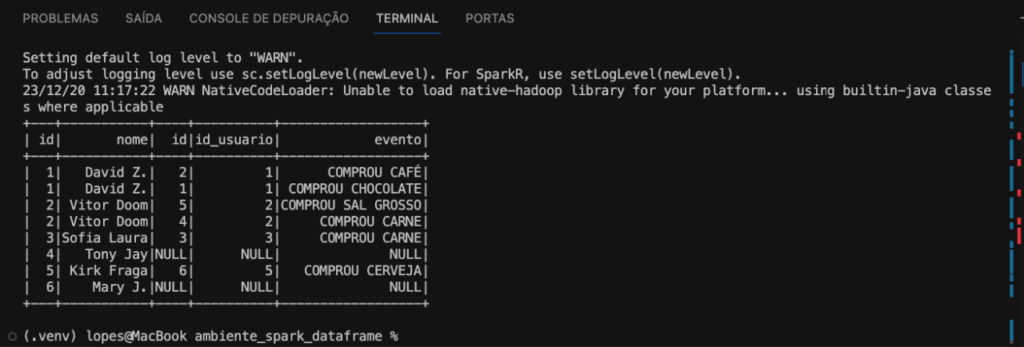
Portanto, esse código está realizando uma junção à esquerda entre os DataFrames com base na condição especificada, como podemos ver na imagem abaixo.
O próximo join será a junção a direita.
Right join com Spark
Utilizamos o Right join com Spark quando queremos todas as informações da tabela da direita e as correspondentes da tabela da esquerda, mesmo que não haja correspondência.
Faremos o join entre com df_usuarios e df_eventos. A condição de junção, será a coluna id em df_usuarios deve ser igual à coluna id_usuario em df_eventos. Finalizando com o right, indicando que é uma junção à direita, mantendo todas as linhas de df_eventos e as correspondentes linhas de df_usuarios, se houver.
df_usuarios.join(df_eventos,df_usuarios.id == df_eventos.id_usuario,right).show()
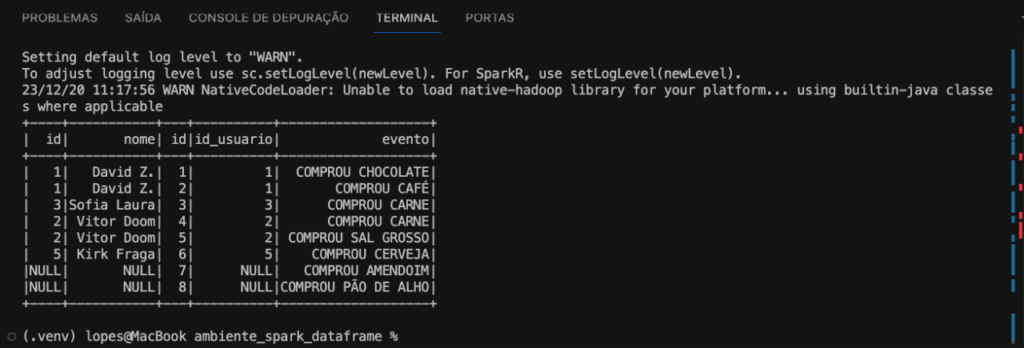
Portanto, esse código está realizando uma junção à direita entre os DataFrames com base na condição especificada, como podemos ver na imagem abaixo.
O próximo join será a junção onde há correspondência apenas.
Inner join com Spark
Utilizamos o Inner join com Spark quando queremos as informações da tabela da esquerda e as correspondentes da tabela da direita, somente quando houver correspondência.
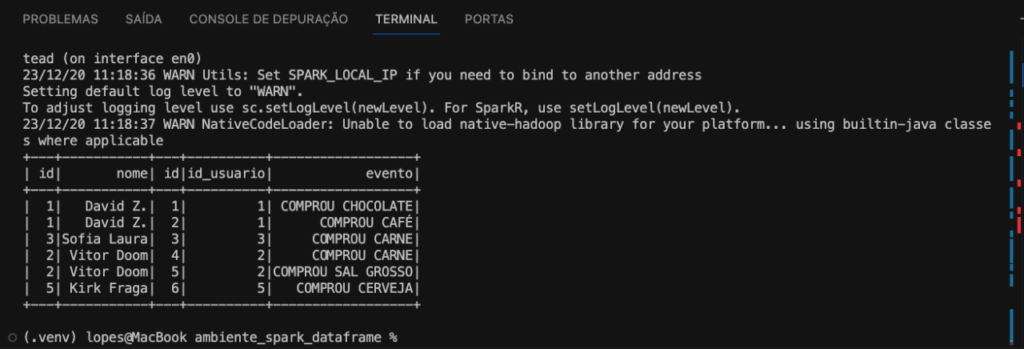
Faremos o join entre com df_usuarios e df_eventos. A condição de junção, será a coluna id em df_usuarios deve ser igual à coluna id_usuario em df_eventos. Finalizando com o inner, indicando que é uma junção onde há correspondência apenas, mantendo as linhas de df_usuarios e as correspondentes linhas de df_eventos, somente se houver correspondência.
df_usuarios.join(df_eventos,df_usuarios.id == df_eventos.id_usuario,inner).show()
Portanto, esse código está realizando uma junção onde há correspondência apenas entre os DataFrames com base na condição especificada, como podemos ver na imagem abaixo.
O próximo join será a junção completa de ambos os DataFrames.
Outer join com Spark
Utilizamos o Outer join com Spark quando queremos todas as informações da tabela da esquerda e todas da tabela da direita, mesmo que não haja correspondência.
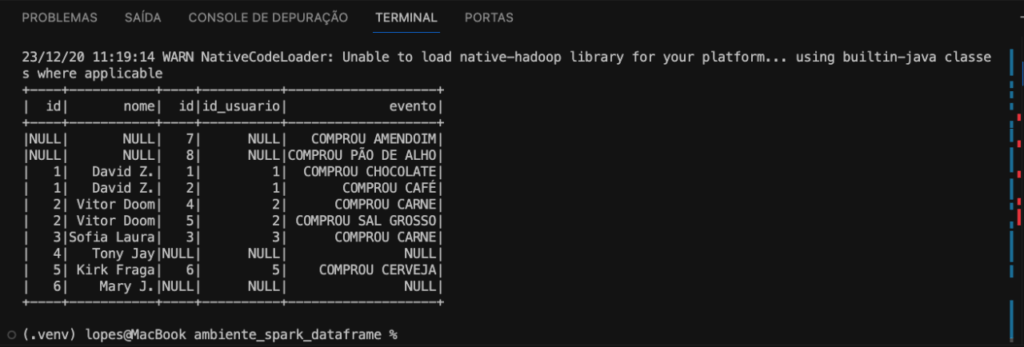
Faremos o join entre com df_usuarios e df_eventos. A condição de junção, será a coluna id em df_usuarios deve ser igual à coluna id_usuario em df_eventos. Finalizando com o outer, indicando que é uma junção completa, mantendo todas as linhas de df_usuarios e todas as linhas de df_eventos.
df_usuarios.join(df_eventos,df_usuarios.id == df_eventos.id_usuario,outer).show()
Portanto, esse código está realizando uma junção completa entre os DataFrames com base na condição especificada, como podemos ver na imagem abaixo.
Agora vamos criar novas colunas com o Spark.
Criar Colunas com Spark
Como Spark, podemos criar colunas simples com uma variável ou uma constante ou até mesmo colunas mais complexas utilizando funções e cálculos derivados do dataframe. Para criação de novas colunas utilizamos a função WithColumn do Spark.
WithColumn com Spark
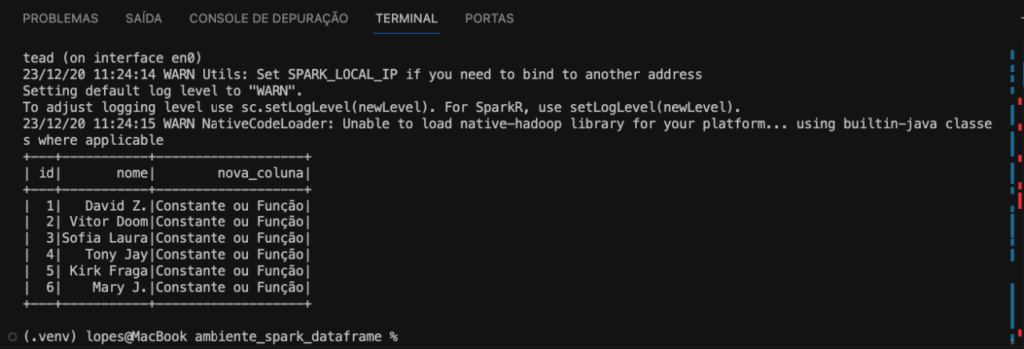
O método withColumn é usado para adicionar ou substituir uma coluna no DataFrame, no exemplo do código Python a seguir temos o df_usuarios e criamos a nova_coluna, este é o nome da nova coluna que será adicionada ou substituída. Estamos usando a função lit para adicionar uma coluna constante ao DataFrame. Pode ser uma constante específica, como uma string (no exemplo usamos o texto “Constante ou Função”), ou o resultado de uma função.
df_usuarios\ .withColumn(nova_coluna, f.lit(Constante ou Função))\ .show()
Portanto, esse código está adicionando uma nova coluna chamada nova_coluna ao df_usuarios, e todos os valores nessa coluna serão constantes ou o resultado de uma função, dependendo do que você passar para lit, conforme a imagem abaixo.
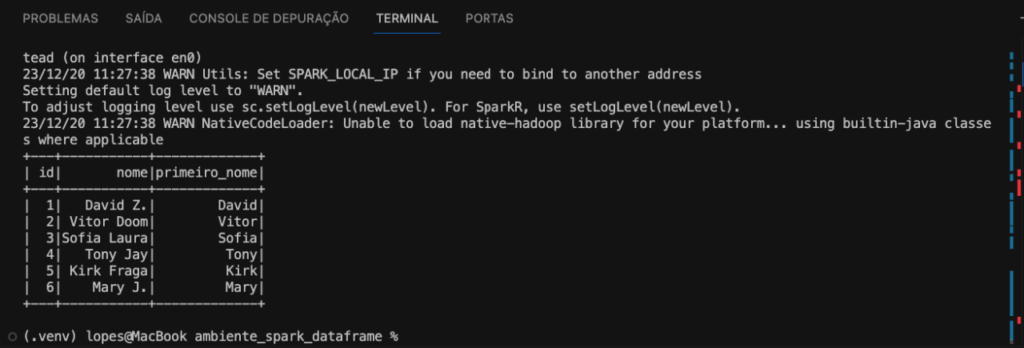
Agora podemos fazer um exemplo mais prático. Iremos extrair apenas o primeiro nome do usuário. Utilizamos a função split para separar os nomes pelo espaço e com a função getItem pegamos a primeira ocorrência, ou seja o primeiro nome.
df_usuarios\ .withColumn(primeiro_nome, f.split(f.col(nome), ).getItem(0))\ .show()
Confere o resultado na imagem abaixo.
Agora, vamos aprender a criar uma nova coluna utilizando a função de concatenação.
Concat_ws com Spark
Com a função Concat_ws é possível fazer a concatenação de colunas em apenas uma utilizando separador, confere o exemplo do código Python abaixo, onde criamos uma coluna com o nome e evento do usuário.
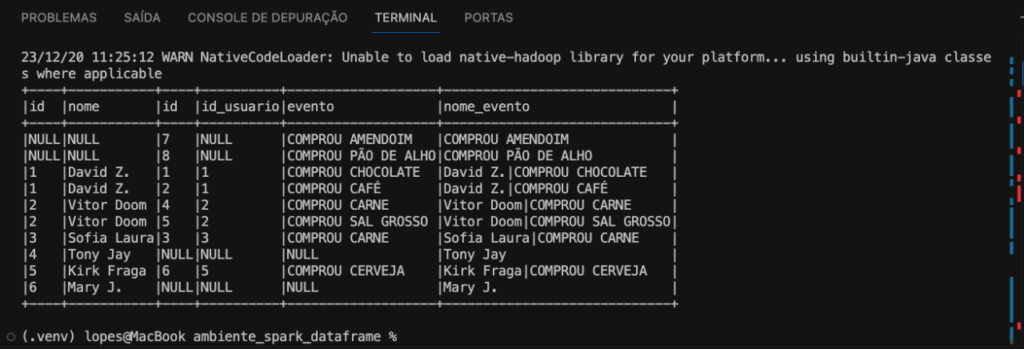
df_usuarios\ .join(df_eventos,df_usuarios.id == df_eventos.id_usuario,outer)\ .withColumn(nome_evento, f.concat_ws(|,nome,evento))\ .show(truncate=False)
E então temos a coluna nome_evento conforme imagem abaixo.
E assim finalizamos mais algumas funções Spark. Gostou? Quer mais? Confere todo esse passo a passo das funções Spark joins, withColumn e concat_ws com Spark em vídeo, no canal do Fluxo de Dados!
Funções Spark Joins, WithColumn e Concat_ws com o Fluxo de Dados
Esse conteúdo é uma parceria com o canal do Fluxo de Dados, lá você confere as funções Spark withColumn e concat_ws e muito mais.
E então seguimos a série Fluxo de Dados com Spark . Fica ligado nos próximos conteúdos sobre outros temas relacionados a big data. Agora você está pronto para embarcar em suas próprias jornadas analíticas usando PySpark. A capacidade de processar dados em escala e realizar análises complexas torna PySpark uma ferramenta valiosa para profissionais que buscam explorar o potencial máximo do big data.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Boas Práticas de Visualização de Dados Parte I
- Boas Práticas de Visualização de Dados Parte II
- Regressão com scikit-learn
- Engenharia de Atributos AKA Feature Engineering Parte I
- Engenharia de Atributos AKA Feature Engineering Parte II
- O Guia do XGBoost com Python
- Análise de Dados com Numpy Python
- Visualizar Dados do PostgreSQL no Metabase
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
