

Fala galera do mundo dos dados, hoje é dia de preparar ambiente PySpark. No universo da análise de dados e processamento em larga escala, o Apache Spark se destaca como uma ferramenta importante. A capacidade de processar grandes volumes de dados de maneira distribuída e eficiente faz do Spark uma escolha interessante.
Precisamos preparar um ambiente PySpark robusto e funcional. Na série Fluxo de Dados com Spark, exploraremos passo a passo como configurar o ambiente PySpark, fornecendo exemplos práticos ao longo do caminho. Se você está iniciando sua jornada com o Spark ou busca aprimorar suas habilidades existentes, este guia é o ponto de partida ideal.
Por que PySpark?
PySpark é a interface Python para o Apache Spark, oferecendo a flexibilidade e a simplicidade do Python combinadas com o poder do Spark. Essa combinação única atrai desde iniciantes entusiastas até especialistas em ciência de dados e engenheiros de big data.
O que Você Aprenderá sobre Spark
- Instalação do Apache Spark e PySpark: Abordaremos a instalação do Apache Spark e a configuração do PySpark no seu ambiente. Este é o primeiro passo crucial para começar a trabalhar com o Spark.
- Configuração do Ambiente de Desenvolvimento: Exploraremos as configurações essenciais do ambiente de desenvolvimento para garantir uma experiência suave ao usar PySpark.
- Primeiros Passos com Exemplos Práticos: Você será guiado através de exemplos práticos que abrangem desde a leitura de dados até operações avançadas de transformação e análise.
- Integração com Jupyter Notebooks: Descubra como integrar PySpark com Jupyter Notebooks para uma análise interativa e eficiente.
Configurar o Ambiente PySpark
Primeiramente iremos configurar o ambiente de desenvolviemnto, preparamos um passo a passo para garantir que esteja tudo instalado e funcionando para criar os códigs Python utilizando o PySpark.
- Instalar o Python, você pode verificar a versão instalada com o código
python – version - Instalar o Java, para verificar a versão instalada utilize
java – version - Instalar o VSCode, é possível utilizar outras IDEs, mas o VSCode é bem utilizado pela comunidade e ajuda bastante no desenvolvimento com as suas extenssoes.
- Criar ambiente virtual utilizando o comando
python -m venv .venv, a criação de ambiente virtual é opcional, ma ajuda bastante no desenvolvimento separando aplicações com versoes de bibliotecas e do própio Pyhon. - Para ativar ambiente virtual utilize o camando
source .venv/bin/activate - Instalar o PySpark através do gerenciador de pacoste pip com o código
pip install pyspark - Executar o PySpark com o comando
pyspark, e então será apresentado alguma coisa semelhante a imagem abaixo.
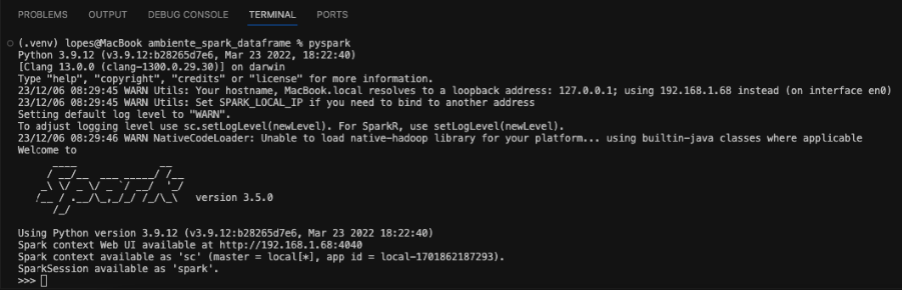
Agora sabemos que temos o ambiente configurado e pronto para execução!!! Então, partiu criar o seu primeiro dataframe.
Spark Dataframe
Chegou a hora de criar o dataframe no mesmo diretório do ambiente virtual iremos criar um arquivo com o nome main.py. Observe a imagem abaixo com o arquivo já criado no VSCode.
Dessa forma, podemos escrever o nosso código Python dentro deste arquivo. agora faremos a criação do dataframe Spark com o código abaixo.
Este código Python utiliza o PySpark, que é uma biblioteca para processamento de dados distribuído, especialmente projetada para trabalhar com grandes conjuntos de dados. Vamos simplificar o código:
Importação da Biblioteca
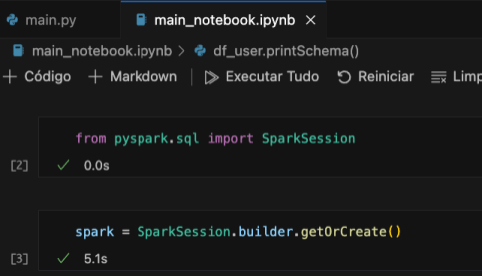
from pyspark.sql import SparkSession
Esse trecho de código importa a classe SparkSession do PySpark, que é essencial para interagir com o Spark.
Criação da Sessão Spark
if __name__ == '__main__': spark = SparkSession.builder.getOrCreate()
Aqui, verifica se o script está sendo executado como o programa principal. Se sim, criamos uma sessão Spark usando SparkSession.builder.getOrCreate(). A sessão Spark é o start para qualquer funcionalidade do Spark.
Criação de Dados e DataFrame
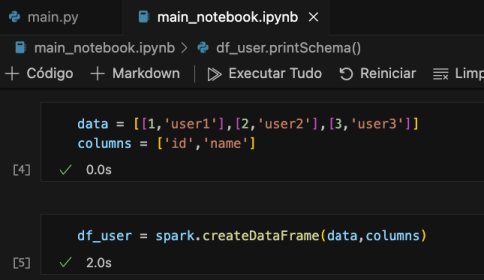
data = [[1, 'user1'], [2, 'user2'], [3, 'user3']] columns = ['id', 'name'] df_user = spark.createDataFrame(data, columns)
Agora criando uma lista de listas chamada data que contém informações sobre usuários. Uma outra lista columns que especifica os nomes das colunas. Em seguida, utilizamos spark.createDataFrame(data, columns) para criar um DataFrame Spark chamado df_user com base nesses dados.
Exibição do DataFrame
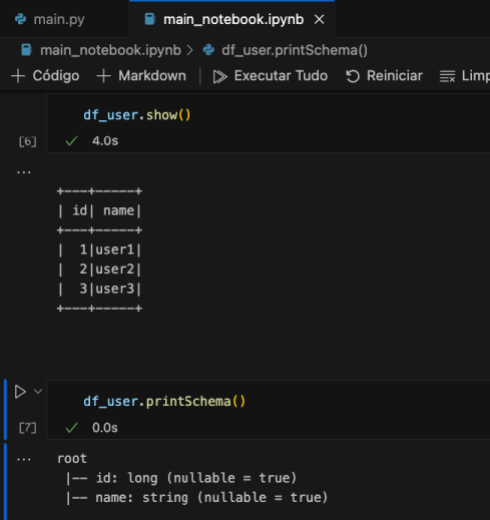
df_user.show()
Neste ponto, será exibido o conteúdo do DataFrame df_user com a função show. Isso é útil para verificar se os dados foram criados corretamente.
Parada da Sessão Spark
spark.stop()
Finalmente, encerramos a sessão Spark. Isso é importante para liberar recursos após a conclusão do trabalho.
Em resumo, este código cria uma sessão Spark, em seguida, cria um DataFrame com informações de usuários e exibe esses dados. A imagem a seguir é o resultado do código exemplificado anteriormente.
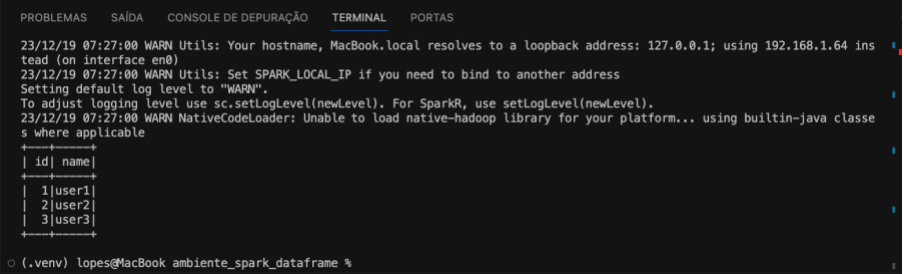
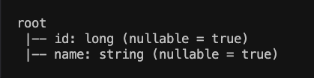
Podemos ainda, imprimir o esquema (schema) do DataFrame df_user. O esquema descreve a estrutura dos dados no DataFrame, incluindo o nome das colunas e os tipos de dados associados a cada coluna.
df_user.printSchema()
Então, o schema do dataframe será exibido conforme imagem abaixo.
Muito bom?! Para ficar melhor ainda e um tanto mais didático vamos utilizar o Spark no Jupyter Notebook.
Utilizar o Spark no Jupyter Notebooks
Para começar, iremos criar o arquivo main_notebook.ipynb no mesmo diretório onde criamos o arquivo anterior e em seguida faremos um print simples para verificar o funcionamento do Júpiter notebook no VSCode. Conforme imagem abaixo.
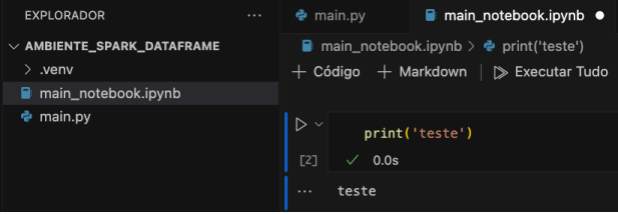
Agora iremos utilizar o mesmo código criado anteriormente, mas vamos escrever por blocos que são executados separadamente mas ficam em memoria até a finalização no jupyter notebook. Inicialmente faremos a importação da biblioteca e a criação da sessão Spark como a imagem abaixo.
Em seguida, a criação dos dados e DataFrame de usuários.
E concluimos, com a exibição dos dados com a função show e do esquema com a função printSchema, tudo isso está exemplificado na imagem a seguir.
E aí? Gostou dessa introdução ao Spark? Quer mais? Confere todo esse passo a passo de como preparar um ambiente PySpark em vídeo, no canal do Fluxo de Dados!
Como Preparar Ambiente PySpark com o Fluxo de Dados
Esse conteúdo é uma parceria com o canal do Fluxo de Dados, lá você confere como preparar o ambiente para o Spark e muito mais.
E então finalizamos o primeiro post da série Fluxo de Dados com Spark . Portanto, fica ligado nos próximos conteúdos que vai ter toda a continuidade de como trabalhar com Spark. Dessa forma, ao final desta série, você estará pronto para embarcar em suas próprias jornadas analíticas usando PySpark. A capacidade de processar dados em escala e realizar análises complexas torna PySpark uma ferramenta valiosa para profissionais que buscam explorar o potencial máximo do big data. Um abraço e até a próxima!
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Boas Práticas de Visualização de Dados Parte I
- Boas Práticas de Visualização de Dados Parte II
- Regressão com scikit-learn
- Engenharia de Atributos AKA Feature Engineering Parte I
- Engenharia de Atributos AKA Feature Engineering Parte II
- O Guia do XGBoost com Python
- Análise de Dados com Numpy Python
- Visualizar Dados do PostgreSQL no Metabase
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
