

Dando continuidade às Boas Práticas de Visualização de Dados, essa é a segunda parte do artigo, se não leu a Parte I confere o post (Boas Práticas de Visualização de Dados Parte I). Na Parte II vamos ver um pouco sobre como dar os primeiros passos com a biblioteca Matplotlib, umas das principais e pioneiras bibliotecas para visualização de dados. Vamos ver também a biblioteca Seaborn, uma excelente alternativa para cumprir as principais regras que uma boa visualização precisa. Vamos simbora!
Até mesmo com a biblioteca Pandas de manipulação de dados, podemos construir os gráficos em Python. Porém devemos ter um bom leque de bibliotecas que constroem visualização de dados em Python, tendo em vista as necessidades que surgem de melhorarmos os gráficos. Por isso vou te apresentar a biblioteca Matplotlib e a Seaborn. Sempre com o objetivo que as visualizações gráficas consigam transmitir uma melhor informação e consigam passar da forma mais adequada o objetivo da informação.
Como construir uma boa visualização de dados com Python?
Primeiramente, a visualização de dados dentro de um projeto de data science em sua maioria ocorre durante a fase de exploração dos dados. Como já dito anteriormente, tendo um papel de suma importância para dar significado aos dados. Então é importante sempre termos a capacidade de questionarmos os dados. Por exemplo, o tradicional gráfico de barras que nos mostra que as barras altas são os valores mais comuns e as barras mais curtas são os valores menos comuns, certo? Logo, deve ser levantado questionamentos do tipo: “Por que x valores são mais comuns que outros?”, “Existe algum padrão incomum?”.
A partir de agora, veremos como dar os primeiros passos e construir uma boa visualização de dados com as bibliotecas Matplotlib e Seaborn do Python. Vamos simbora colocar a mão na massa! Lembrar sempre que o objetivo da visualização de dados é transcrever o problema do negócio para algo que faça sentido e ajude a compreender o problema.
Visualização de Dados com Matplotlib
A biblioteca Matplotlib é a mais conhecida pela comunidade Python, isso porque foi a biblioteca pioneira para visualização de dados, ainda sendo a mais usada por todos os cientistas de dados e programadores Python. A biblioteca ainda é utilizada como suporte para construção de visualização de dados por outras bibliotecas e ferramentas, como a biblioteca de manipulação de dados Pandas. Porém nem tudo são flores, a API da biblioteca não é tão familiar. Dessa forma para que possamos construir uma boa visualização de dados e que seja respeitada as três regras que mencionamos para ter uma boa visualização de dados, é preciso muita customização e trabalho manual para gerar gráficos atraentes.
Antes de começarmos a construir os gráficos, verifique se você tem a biblioteca instalada, caso não, você pode instalar de acordo com o ambiente que está usando:
- Conda – conda install matplotlib
- Pip – pip install matplotlib
Com a biblioteca instalada, para começarmos a trabalhar com ela só nos falta importar:
#Importar a biblioteca import matplotlib.pyplot as plt
Vamos iniciar com um gráfico de Barras, um dos principais gráficos e que usualmente você deve visualizar, principalmente nos dias atuais diante da pandemia. Logo você irá perceber que em poucas linhas de código você já consegue plotar seu primeiro gráfico. As coisas agora vão ficar mais práticas e sem muita enrolação, então vamos pra cima!
Gráfico de Barras com Matplotlib
No gráfico de barras ou bar plot, em sua maioria queremos observar a relação entre uma variável qualitativa (categórica) e uma variável quantitativa (numérica).
Ter cuidado para não confundir o gráfico de barra com o gráfico de histograma, nos histogramas o objetivo é visualizar como os dados de uma variável estão distribuídos.
#Plotando um Gráfico de Barra x = [5, 7] y = [4, 8] plt.bar(x, y) plt.show()
Note que:
- Inseri uma lista de valores para X e Y.
- Usei o comando ‘plt.bar’ para plotar o gráfico de barras e passei os valores de X e Y como parâmetro.
Dessa forma, temos o nosso primeiro gráfico de barras. No entanto, como vocês podem observar, em nosso gráfico ainda está faltando legendas, identificações dos rótulos X e Y, entre outros argumentos para o gráfico ficar com um melhor visual e entendimento.
x = [5, 7]
y = [4, 8]
#Legendas
plt.title('Meu primeiro gráfico')
plt.xlabel('Eixo X')
plt.ylabel('Eixo Y')
plt.bar(x, y)
plt.show();
Observe que inserimos três novos métodos na construção do nosso gráfico de barras.
- title(), permite que possamos inserir um título ao gráfico
- xlabel(), permite inserirmos um nome ao Eixo X
- ylabel(), permite inserirmos um nome ao Eixo Y
Agora o entendimento do gráfico já deu um UP.
Até o momento estávamos trabalhando apenas com um único valor quantitativo para o gráfico de barras. Vamos agora criar um exemplo para trabalhar com dois valores, sendo eles qualitativo e quantitativo. Imagine que foi feita na cidade de São Paulo uma pesquisa com 100 pessoas para saber se ao certo a pronúncia é biscoito ou bolacha. Assim sendo, 40 pessoas afirmaram ser biscoito e 60 afirmaram ser bolacha.

Existe alguns argumentos disponibilizado pela biblioteca Matplotlib. que podem ser acrescentados em nosso gráfico, para deixá-lo com um melhor visual e entendimento. Como marcadores, cores, nomes, tipos de linhas, entre outros. Então vamos aplicar alguns deles ao nosso novo gráfico. Veja:
BISX = ['Biscoito']
BISY = [40]
BOX = ['Bolacha']
BOY = [60]
plt.title('Biscoito ou Bolacha')
plt.ylabel('Quantidade de Pessoas')
#Chamando os argumentos
plt.bar(BISX, BISY, label = 'Biscoito')
plt.bar(BOX, BOY, label = 'Bolacha')
#Metodo Legend
plt.legend()
plt.show()
Note que foi adicionado ao código do gráfico, um argumento chamado label após passarmos os valores de Biscoito e Bolacha, o argumento label é usado para dar nome aos gráficos e ajudar na comparação dos gráficos. Ao final, ainda usamos o método legend(), para plotarmos os argumentos.
Ainda poderíamos alterar a cor, passando o argumento color, seja através da regra rgba ou regra da biblioteca.
BISX = ['Biscoito']
BISY = [40]
BOX = ['Bolacha']
BOY = [60]
plt.title('Biscoito ou Bolacha')
plt.ylabel('Pessoas')
#Argumento color
plt.bar(BISX, BISY, label = 'Biscoito', color = '#614733')
plt.bar(BOX, BOY, label = 'Bolacha', color = '#cc7f43')
#Metodo Legend
plt.legend()
plt.show()
Veja mais formas de como utilizar os argumentos da biblioteca na documentação do Matplotlib.
Avançando na visualização de dados
Vamos agora criar um dataframe para trabalhar melhor com os dados e construir visualizações um pouco mais complexas.
#vamos criar um dicionário para depois transformar em dataframe
dados = {'canal_venda' : ['facebook', 'twitter', 'instagram', 'linkedin', 'facebook'],
'acessos': [100, 200, 300 ,400, 500],
'site': ['site1', 'site1', 'site2', 'site2', 'site3'],
'vendas': [1000.52, 1052.34, 2002, 5000, 300 ]}
#Criar um dataframe a partir do dicionário
df = pd.DataFrame(dados)
df.head()Antes estávamos plotando um gráfico de barras a partir de uma lista de valores, por outro lado, agora vamos plotar novamente um gráfico de barras a partir de um conjunto de dados e existem duas maneiras de plotarmos:
#Plotando gráfico de barra para o conjunto de dados df.plot.bar();
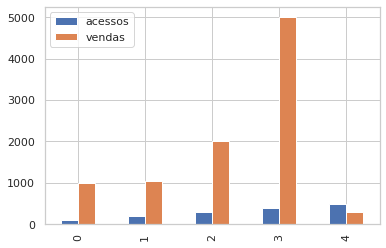
Uma outra opção é usar o parâmetro kind no método plot informando o gráfico que queremos plotar.
#Plotando gráfico de barra com parâmetro kind df.plot(kind='bar');

Estou determinando que ele plot um gráfico de barras para todo o conjunto de dados e como eu não determinei os eixos X e Y, o gráfico plota as duas colunas numéricas do conjunto de dados, acessos e vendas.
Avançando ainda mais um pouco, agora o objetivo é construir um gráfico que indique o número de acesso por canais de vendas e também vamos alterar as cores e tamanho.
#Agrupando os dados de acesso por canais de venda para construir o gráfico
dados = df.groupby('canal_venda')['acessos'].max()
#Alterando o tamanho (criando uma nova figura por isso o 'ax')
fig, ax = plt.subplots(figsize=(10,6))
#Cores
color = ['#2144de','#d9485b', '#385fba', '#769df5']
#Inserindo argumento de cor
dados.plot(kind='bar', ax=ax, color=(color));
#Alterando as legendas
plt.title('Número de acesso por canais de venda');
ax.set_xlabel('Canal de venda');
ax.set_ylabel('Acessos');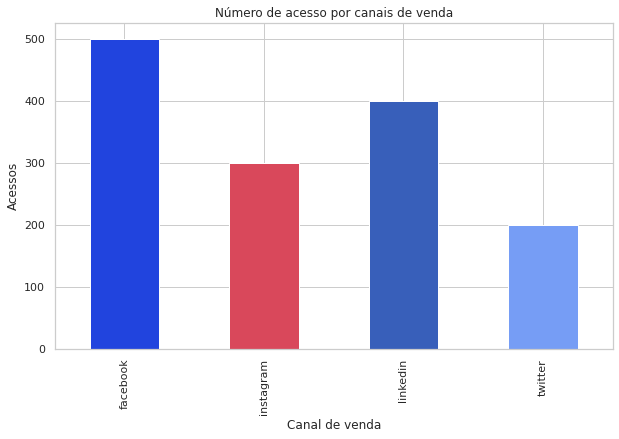
Note que criamos uma variável dados para agrupar e selecionar os dados que queremos usar para construir o gráfico e usamos o método max(), para usar os valores máximos da coluna acessos. Outra novidade foi que aumentamos o tamanho do gráfico construindo uma nova figura, por isso usamos o ax e criamos uma lista de cores para ser usada no parâmetro color.
Lembre-se que isso é só um exemplo, não está nem perto de uma boa visualização.
Histograma com Matplotlib
O gráfico de histograma é um dos gráficos mais conhecidos e úteis na visualização de dados. Através do histograma conseguimos ter uma ideia da distribuição dos dados através de seus bucktes.
Para construí-lo, primeiro separamos o range de valores da variável em buckets (bins), ou seja, intervalos menores, de igual tamanho. A altura de cada retângulo em um bucket (bin) é a contagem do número de observações que pertencem àquele bucket. Quanto mais alto um bucket, mais observações ele contém (e mais denso ele é), menos distribuído.
A construção de um gráfico de histograma é semelhante a segunda opção que vimos para plotar um gráfico de barras, a diferença está no parâmetro bins do histograma que se trata do tamanho de intervalos que queremos observar na variável.
#plotando um gráfico de histograma com 10 bins df.plot(kind='hist', bins=10);
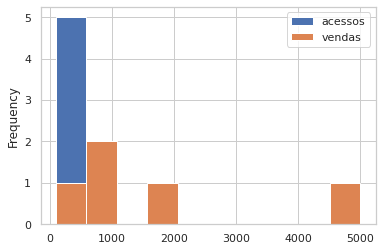
Dessa forma estamos construindo um gráfico de histograma para todas as variáveis numéricas do conjunto de dados, porém também é possível plotarmos um histograma para cada variável, veja:
#Plotando histograma para cada variável (coluna) com 6 bucket (bins) df.hist(bins=6);

O histograma é uma aproximação discreta da distribuição de probabilidade dos dados. A altura de cada retângulo representa a frequência absoluta com que o valor da classe ocorre no conjunto de dados para classes uniformes.
Gráfico de Dispersão com Matplotlib
O gráfico de dispersão ou scatter plot é basicamente um gráfico com a dispersão de pontos em um plano. Sendo útil para verificar como os dados de uma variável estão distribuídos sobre outra variável. O scatter plot se torna muito eficiente quando estamos lhe dando com um grande conjunto de dados e precisamos formular hipóteses. Pois com gráfico podemos analisar como os dados estão dispersos e distribuídos, retirando ricas informações.
- Representando em sua maioria por duas ou mais variáveis, utiliza coordenadas cartesianas para exibir valores de um conjunto de dados.
- Exibidos como uma coleção de pontos, cada um com o valor de uma variável.
Veja a construção do scatter plot:
plt.figure(figsize=(10,6)) plt.scatter(df.acessos, df.vendas, alpha=0.5, cmap="viridis") plt.colorbar();

O parâmetro alpha representa a transparência dos pontos e o cmap as cores do gráfico. O parâmetro cmap é um dos mais úteis para mantermos a integridade gráfica, sendo usado tanto na biblioteca matplotlib como também na seaborn. Temos que sempre buscar outros parâmetros para melhorar a qualidade dos gráficos. Existem diversos parâmetros que podem ser usados para customização do resultado final.
Por mais que a biblioteca matplotlib permite você fazer inúmeras visualizações de dados e de diversas formas, já deu pra perceber que ela é um pouco limitada. Portanto, durante o processo de construção de visualizações de dados seja durante a EDA ou não, devemos saber trabalhar com outras opções de bibliotecas, para entregar uma boa visualização e informação de acordo com o objetivo pretendido.
Visualização de Dados com Seaborn
O Seaborn é uma biblioteca essencial para construir atraentes e informativos gráficos estatísticos. Sendo uma das principais bibliotecas para visualização de dados e que conta com uma das melhores documentações. Permitindo que possamos ir atrás de mais argumentos para melhorar a visualização do gráfico. Ademais, a biblioteca é muito útil para cumprir as regras que toda visualização de dados precisa.
Os mesmos gráficos que foram feitos com a biblioteca Matplotlib, vamos agora construir com a biblioteca Seaborn e tentar melhorar a nossa visualização, cumprindo as três regras que foram faladas para uma boa visualização de dados: Integridade gráfica, maximização de cores e tinta e evitar lixo gráfico.
Vamos repetir o processo realizado anteriormente e verificar se a biblioteca está instalada, caso contrário, você pode instalar de acordo com o ambiente que está usando:
- Conda – conda install seaborn
- Pip – pip install seaborn
Com a biblioteca instalada, para começarmos a trabalhar com ela só nos falta importar:
#Importar a biblioteca import seaborn as sns
A primeira coisa que iremos fazer e já irá ajudar na visualização e interpretação dos gráficos é colocar uma grade ao fundo do gráfico e setar o seu estilo, veja:
sns.set_style('whitegrid')Gráfico de Barras com Seaborn
Antes de construirmos o gráfico de barras, vamos fazer uma manipulação dos dados construindo um segundo dataframe e somar todos os seus registros da coluna acessos, para usarmos na construção do gráfico de barras, isso será útil para evitar algumas repetições da coluna canal_venda.
#Vamos criar um novo df e fazer um agrupamento
#para recuperar o total de acesso de cada canal de venda
df2 = df.groupby(['canal_venda']).agg({'acessos' : 'sum'}).reset_index()Agora sim, a partir desse novo dataframe ficara melhor de se construir o gráfico de barras.
#Os dados que queremos usar para construir o gráfico
dados = df2[['canal_venda', 'acessos']].sort_values(ascending=False, by='acessos')
#grafico de barras com seaborn
plt.figure(figsize=(13,6))
sns.barplot(x='canal_venda',
y='acessos',
data=dados,
palette = sns.color_palette("BuGn_r", n_colors=len(dados)+2))
#setando o gráfico
plt.xlabel('Canais de Venda')
plt.ylabel('Acessos')
plt.title('Número de acesso por canais de venda');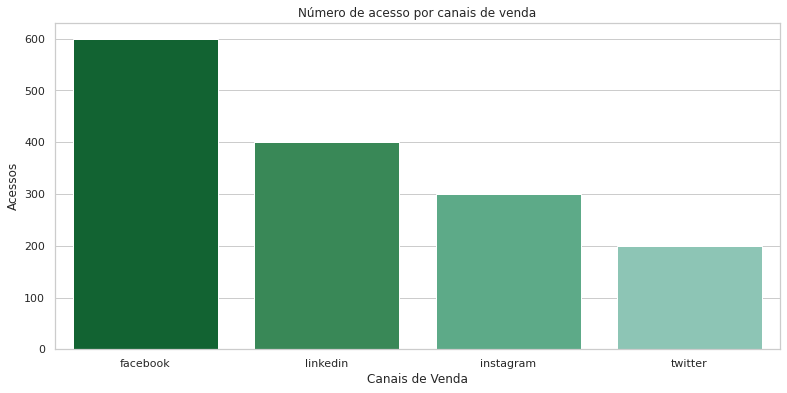
Diferente da biblioteca Matplotlib, para plotarmos um gráfico com a biblioteca Seaborn só precisamos informar o nome do método do gráfico e respectivamente os seus parâmetros. Note também que com a biblioteca seaborn obrigatoriamente precisamos informar quem é o eixo X e Y, e o conjunto de dados dos eixos com o parâmetro data. Também foi utilizado o parâmetro palette para informar uma paleta de cores, assim melhorando a visualização e integridade gráfica.
Vale lembrar que no bar plot do seaborn, cada eixo de X tem sua altura na média dos valores de Y.
Histograma com Seaborn
#histograma com seaborn
plt.figure(figsize=(10,6))
#Transformar a coluna vendas do tipo float em int
df['vendas'] = df['vendas'].astype(int)
#dados que queremos usar
dados = df[['vendas','acessos']]
sns.distplot(dados, rug=True);
plt.title('Histograma ou Distplot')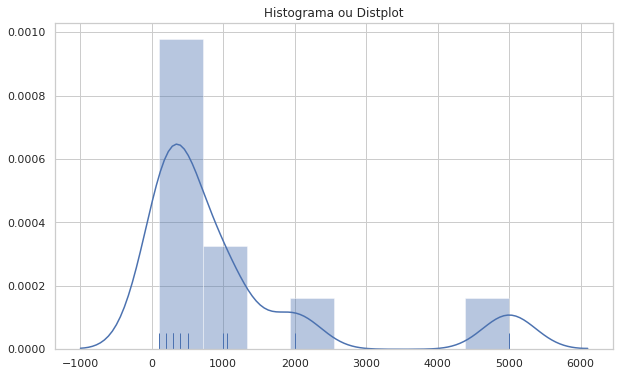
O histograma gerado pelo seaborn ele tende a ser mais rico por possuir alguns parâmetros que não existem no matplotlib e consequentemente isso passa mais informação de como os dados estão distribuídos. Parâmetros como o rug, note que:
O histograma gerado pelo seaborn apresenta a curva de KDE (curva de densidade estimada), que é uma estimação da verdadeira função de densidade dos dados, e com o parâmetro rug, que são as pequenas marcas verticais na parte inferior do gráfico é capaz de indicar a densidade de kernel dos dados como se fossem um histograma 1D.
Para plotarmos o gráfico de histograma ou distplot, basta usar o método do gráfico, distplot(). Porém também é possível usar parâmetros que passam mais informações de como os dados estão distribuídos, como o rug que indica uma estimativa de densidade de kernel.
Gráfico de Dispersão com Seaborn
#scatterplot com seaborn
plt.figure(figsize=(10,6))
sns.scatterplot(x='acessos', y='vendas',
hue="canal_venda", palette="coolwarm",
s=500, alpha=1.0, data=df);
No parâmetro hue passamos as variáveis que cada cor representa e como dito anteriormente, o parâmetro alpha representa a transparência dos pontos. O parâmetro s permite aumentar o tamanho do ícone das bolas.
O Seaborn ainda conta com uma funcionalidade emprestada de uma das principais bibliotecas, ggplot2, para visualização de dados da linguagem R. A possibilidade de criar scatter plots com uma curva de regressão. Veja:
plt.figure(figsize=(10,6)) #scatter plot com curva de regressão sns.regplot(data=df, x='acessos', y='vendas', color='black');
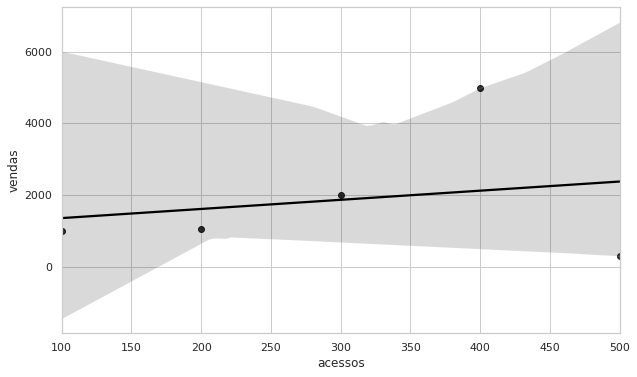
Existem outros tipos de gráficos e bibliotecas que aqui não foram mencionadas que são de extrema importância para a visualização de dados, como boxplot, heatmap (mapa de correlação), distplot e entre outros. Bibliotecas como Plotly, Bokeh e Altair, que não abordamos ainda, têm extrema importância, pois são muito intuitivas.
Visualização de Dados ao Cubo
Sempre que for construir um gráfico e realizar uma visualização de dados, seja na linguagem Python, R ou através de outra ferramenta de visualização de dados, lembre-se sempre das três regras principais que uma boa visualização de dados precisa: Integridade gráfica para que possam confiar em seus gráficos, maximização e proporção de tintas, lembre-se “menos é mais” e evitar lixos gráficos para que seu gráfico seja o foco das atenções. Por fim, indico os dois livros que são essenciais para quem quer aprimorar a visualizações de dados, “Storytelling com Dados” e “Como Mentir com Estatística”. Ambos abordam como você pode ter boas práticas na hora de construir visualização de dados como aqui foi falado.


Até uma próxima e conte sempre comigo se precisar de ajuda nesse mundão da ciência de dados. Não deixa de conferir no GitHub do Luis o notebook com todos esses gráficos.
Referências sobre Visualização de Dados
- The Power of Visualization in Data Science
- 15 Stunning Data Visualizations (And What You Can Learn From Them)
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Introdução a Competições de Ciência de Dados no Kaggle
- AutoML (Automated Machine Learning) com ML.Net
- Entre Vieses e Causalidades: Como (não) ser Enganado pelos Dados
- DataViz com Power BI
- Sistemas de Recomendações com Surprise
- Condicionais em Python
- Polars vs. Pandas: Explorando as principais funções para análise de dados
- Série de Automatização de Tarefas com Python
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Atualmente graduando em Gestão da Informação na UFPE, desenvolvedor em Python, entusiasta em Ciência de Dados e um quase Cientista de Dados. Nas horas vagas jogar um League of Legends e criar filtros para o Instagram cai bem.
