

Fala pessoal! Em primeiro lugar, todo mundo bem? Espero que sim. Então vamos ao que interessa, o que temos para hoje? Em? O que? Posso falar? Você está realmente preparado?

SURPRESAAAAAA! Ou melhor Surprise, vou apresentar um pouco do poder dessa biblioteca para sistemas de recomendações. Mas ainda não sabe do que estou falando? Usa o YouTube? Ou Netflix? Ou qualquer plataforma de Streaming? Portanto, todas elas usam sistemas de recomendação para sugerir o melhor conteúdo para você.
Primeiramente vamos entender o que são sistemas de recomendações. Em seguida, vou apresentar a biblioteca Surprise, e por fim vamos resolver um problema de recomendação.
Sistemas de Recomendações
Os sistemas de recomendações nada mais são que algoritmos com diversas técnicas computacionais combinadas para entregar ao usuário itens personalizados. Sendo assim, usando o exemplo do YouTube, à medida que você assiste conteúdos na plataforma ele sugere novos conteúdos similares. Assim, por debaixo dos panos, um algoritmo de inteligência artificial combina seu perfil, com outros usuários e conteúdos similares, para te sugerir “o que você quer assistir e nem sabia ainda”.
Afinal, será que o Python também tem uma ferramenta para facilitar a construção de sistemas de recomendações? E a resposta é: sim ou claro! Então vamos conhecer a biblioteca Surprise.
O Surprise
Primeiramente vamos na documentação, onde a biblioteca está definida (em tradução livre) da seguinte forma:
“Surprise é um pacote Python para construir e analisar sistemas de recomendação que lidam com dados de classificação explícitos.”
Ainda de acordo com a documentação da biblioteca que é bem completa, com a proposta de dar autonomia ao desenvolvedor. O pacote Surprise já disponibiliza diversos algoritmos prontos para previsão (vamos utilizar 3 deles aqui). Além disso possui ferramentas para avaliar os modelos.
Sendo assim, podemos resolver problemas de recomendações com a biblioteca surprise.
O Problema de Recomendação
Nosso problema é como recomendar filmes para usuários de uma plataforma, a Filmes ao Cubo (o Netflix do Dados ao Cubo). Na Filmes ao Cubo, o usuário pode avaliar os filmes com uma nota de 0 a 5, qualquer semelhança com outras plataformas é mera coincidência. Portanto, como sugerir novos filmes para o usuário baseado nas suas experiências e dos outros usuários?
Logo, para resolver nosso problema, vamos usar o dataset do MovieLens Latest Datasets, com 100 mil avaliações de 600 usuários em 9 mil filmes.
A recomendação de filmes é algo comum encontrado nas plataformas de streaming, mas os sistemas de recomendações no geral estão presentes em muitas outras aplicações. Agora, chega de conversa fiada e vamos ao que interessa. Let’s CODE Dados ao Cubo!
Importando as Bibliotecas
Vamos começar instalando a biblioteca Surprise, como ela não é uma biblioteca nativa do python, então, precisamos instalar através do comando abaixo.
pip install surprise
Assim podemos importar todos os pacotes que vamos utilizar. A biblioteca Pandas para manipular os dados e os pacotes necessários da biblioteca Surprise para o nosso modelo.
import pandas as pd from surprise import Reader, Dataset from surprise.prediction_algorithms.knns import KNNBaseline from surprise.model_selection import train_test_split from surprise.prediction_algorithms.slope_one import SlopeOne from surprise.prediction_algorithms.co_clustering import CoClustering from surprise import accuracy
Pronto! Todos os pacotes importados, vamos carregar os nossos datasets.
Carregando os Dados
Antes de mais nada, salvei todos os datasets no GitHub para facilitar a leitura dos dados, e qualquer um consegue utilizar os dados a partir do endereço raw do GitHub.
Primeiro dataset com os detalhes:
# Dataset com o detalhe dos Filmes
movies = pd.read_csv('https://raw.githubusercontent.com/dadosaocubo/recomenda_filmes/main/data/movies.csv')Segundo dataset com as avaliações:
# Dataset com as avaliações
ratings = pd.read_csv('https://raw.githubusercontent.com/dadosaocubo/recomenda_filmes/main/data/ratings.csv')Dados carregados, vamos verificar o que temos.
Visualizando o Dataset
Agora, com os nossos dados carregados podemos fazer uma análise dos dados que temos.
Primeiramente, vamos fazer um join utilizando a coluna movieId.
# Juntando as informações de filmes e avaliações
filmes = ratings.join(movies.set_index('movieId'), on='movieId')Vamos avaliar os números da base de dados.
# Números dos datasets
print('Quantidade de Filmes Avaliados: ',
filmes['movieId'].value_counts().shape[0])
print('Quantidade de Usuários Avaliando: ',
filmes['userId'].value_counts().shape[0])
print('Quantidade de Avaliações: ',
ratings.shape[0])Quais são os TOP5 filmes com avaliações?
# Quantidade de Avaliações TOP5 Filmes filmes['title'].value_counts().head()
Qual a quantidade de avaliações por usuário?
# Quantidade de Avaliações TOP5 Usuários filmes['userId'].value_counts().head()
Quais são os filmes avaliados por um determinado usuário?
# Avaliações do usuário 414
filmes.query('userId == 414').head()Essas são algumas das informações que podem ser interessantes para uma análise. Mas não para por aí, a etapa de EDA é uma das mais importantes, se não sabe do que estou falando confere o post Análise Exploratória de Dados com Python Parte I. Entendido? Podemos prosseguir? Vamos ao surprise!
Solução com Surprise
O surprise tem implementado vários algoritmos, vamos fazer a análise com 3 deles (KNNBaseline, SlopeOne e CoClustering). O que tiver a melhor performance na avaliação vamos utilizar para o nosso modelo.
Primeiramente, vamos fazer algumas configurações que vão ser utilizadas para todos os modelos.
Configurações para os Modelos
Vamos começar com a função Reader onde vamos informar a nossa escala de avaliação que varia entre 0 e 5.
Para preparar os dados para os modelos, vamos utilizar a função Dataset.load_from_df onde definimos as colunas do dataset ratings (avaliações dos conjuntos de dados) que irão ser utilizadas.
Por fim, vamos utilizar a função train_test_split, para dividir os nossos dados em treino e teste. Dessa forma, conseguimos avaliar os modelos com dados não vistos no treinamento.
# Configuração para treinamento reader = Reader(rating_scale=(0,5)) # Seleção das variáveis para o modelo data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader) # Divisão dos dados de treino e teste trainset, testset = train_test_split(data, test_size=.25, random_state=42)
Finalizando as configurações vamos definir como se comportaram as medidas de similaridade. Em name vamos definir o nome da semelhança a usar, pearson_baseline vai levar em conta a correlação de pearson para fazer a similaridade . Em user_based define se vamos utilizar a similaridade dos usuário ou dos itens, True vamos utilizar baseado nos usuários.
# Configurações das medidas de similaridade
sim_options = { 'name': 'pearson_baseline', 'user_based': True }Agora, que já temos os dados de treino e teste prontos e as definições de similaridade (utilizada em apenas alguns modelos). Vamos criar e treinar nossos modelos.
Treinando os Modelos
Para criar o modelo é bem simples, instalamos o modelo em uma variável, e passamos os parâmetros desejados. Dessa forma, com o modelo criado, fazermos o fit e informar os dados de treino. Em seguida vamos ver os detalhes no código de cada modelo.
Vamos começar com o modelo KNNBaseline. Um algoritmo básico que utiliza o algoritmo KNN (K Vizinhos mais Próximos) e leva em consideração uma classificação de linha de base.
# Criação do modelo knn = KNNBaseline(k=33, sim_options=sim_options) # Treinamento do modelo knn.fit(trainset)
Agora vejamos o modelo SlopeOne. Ele utiliza um algoritmo de filtragem colaborativa básico. Um algoritmo simples, mas preciso.
# Criação do modelo slo = SlopeOne() # Treinamento do modelo slo.fit(trainset)
Para finalizar, o modelo CoClustering. Um algoritmo baseado em co-clustering. Os clusters são atribuídos usando um método de otimização direta, muito parecido com o k-means.
# Criação do modelo co = CoClustering(n_epochs=10, verbose=True, random_state=42) # Treinamento do modelo co.fit(trainset)
Modelos criados e treinados! Chegou a hora de avaliar.
Avaliando os Modelos
A métrica escolhida para avaliar os modelos utilizamos a Raiz do Erro Quadrático Médio das previsões, definida na função accuracy.rmse (root mean square error), lembrando que quanto menor o erro, melhor a qualidade da solução.
Para o modelo KNNBaseline tivemos um RMSE: 0.8888
predictions_knn = knn.test(testset) accuracy.rmse(predictions_knn)
Já para o modelo SlopeOne tivemos um RMSE: 0.9134
predictions_slo = slo.test(testset) accuracy.rmse(predictions_slo)
E para o modelo CoClustering tivemos um RMSE: 0.9534
predictions_co = co.test(testset) accuracy.rmse(predictions_co)
Segundo a avaliação pela Raiz do Erro Quadrático Médio, quando mais próximo de 0, menor o erro do modelo. Então vamos escolher o modelo KNNBaseline!
Predição do Modelo
Para realizar as predições no modelo surprise, precisamos entender alguns parâmetros que são atribuídos às predições:
- uid – O id dos usuários.
- iid – O id dos filmes.
- r_ui (float) – A avaliação real do usuário.
- est (float) – A avaliação estimada pelo modelo.
- details (dict) – Detalhes adicionais sobre a predição.
Parâmetros entendidos vamos fazer as predições com o modelo criado knn e a função predict. Para isso criei duas funções, uma para fazer uma análise da recomendação, informando o id do usuário e o id do filme. E a outra função para gerar o top recomendações, informando o id do usuário e o número de recomendações. Vamos ver em detalhes cada uma delas a seguir.
Função Análise de Recomendação
Esta função retorna a predição do modelo knn para o usuário e o filme informado. Detalhes do código:
- Seleciona o nome do filme com a variável nome_filme.
- Usa um if para verificar se o usuário tem uma avaliação daquele filme, se não tem retorno uma mensagem, se tiver retorno o valor dessa avaliação.
- Faz a predição com as informações de userId e movieId.
def recomenda_filme(userId,movieId):
# ID do usuário para predição
uid = userId
# ID do filme para predição
iid = movieId
nome_filme = movies.query('movieId == @movieId')['title'].values[0]
print('Filme:', nome_filme)
print('Usuário:', userId)
if filmes.query('userId == @userId and movieId == @movieId')['title'].values.size == 0:
print('Usuário não avaliou o filme!')
else:
nota_filme = ratings.query('userId == @userId and movieId == @movieId')['rating'].values[0]
print('Avaliação do usuário:', nota_filme)
# Predição baseada no melhor modelo
print('Estimativa de Avaliação[0-5]:', round(knn.predict(trainset.to_raw_uid(uid), trainset.to_raw_iid(iid))[3], 2))Sendo assim, ao chamar a função recomenda_filme é exibido um print na tela conforme a imagem abaixo.
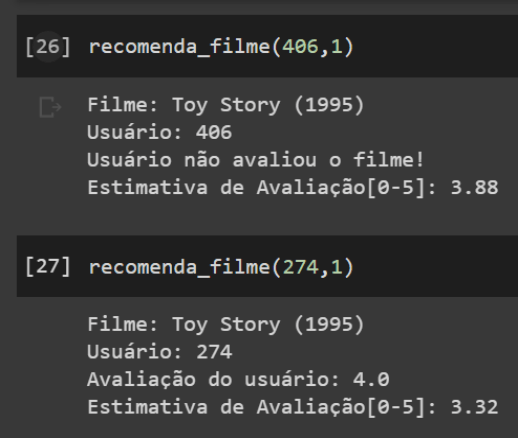
Já vimos a função predict funcionando, então vamos criar a função para retornar as TOP recomendações.
Função TOP Recomendações
Esta função retorna um TOP recomendações do modelo knn para o usuário informado. Detalhes do código:
- A lista de filmes do treinamento lista_filmes_treino, em seguida usa um loop for preencher a lista percorrendo a função trainset.all_items(), converte o id utilizado pela função trainset para o id do filme real com a função to_raw_iid.
- A variável filmes_user seleciona filmes avaliados pelos usuários.
- A variável filmes_user_nao primeiro remove os filmes avaliados pelo usuário (filmes_user) e depois verifica se todos passaram no treinamento (lista_filmes_treino).
- Em seguida na variável ranking faz a predição de todos filmes não avaliados pelo usuário (filmes_user_nao).
- Por fim, faz um sort para ordenar os top, e com o n informado pelo usuário é exibido somente a quantidade solicitada.
def top_n(userId,n):
# Selecionando apenas os filmes do treinamento
lista_filmes_treino = []
for x in trainset.all_items():
lista_filmes_treino.append(trainset.to_raw_iid(x))
# Selecionando os filmes do treinamento que o usuário não avaliou
filmes_user = ratings.query('userId == @userId')['movieId'].values
filmes_user_nao = movies.query('movieId not in @filmes_user')
filmes_user_nao = filmes_user_nao.query('movieId in @lista_filmes_treino')['movieId'].values
# Criando um ranking para o usuário para os filmes não avaliados
ranking=[]
for movieId in filmes_user_nao:
ranking.append((movieId, knn.predict(trainset.to_inner_uid(userId), trainset.to_inner_iid(movieId))[3]))
# Ordenando os TOP filmes avaliados
ranking.sort(key=lambda x: x[1], reverse=True)
# Selecionando os Ids dos filmes
x,_ = zip(*ranking[:n])
# Listando os nomes dos filmes em ordem de recomendação
return movies.query('movieId in @x')['title'].copy().reset_index(drop=True)Dessa forma, ao chamar a função top_n é exibido um print na tela conforme a imagem abaixo.
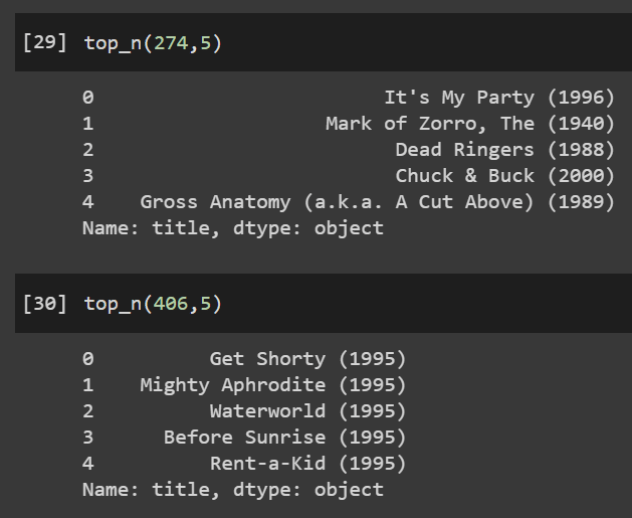
Então, parece que temos um problema de recomendação resolvido! O código completo dessa solução está no GitHub do Dados ao Cubo.
Sistemas de Recomendações ao Cubo
E por hoje é só! Portanto, vimos o que são os problemas de recomendações. O que é a biblioteca Surprise e como ela pode auxiliar em problemas de recomendações.
Também conhecemos um pouco dos algoritmos KNNBaseline, SlopeOne e CoClustering, e como avaliar eles através do RMSE (Raiz do Erro Quadrático Médio).
Em resumo, resolvemos o problema da Filmes ao Cubo! Mas para chegarmos ao nível do Netflix, aqui só vimos a pontinha do iceberg. Espero que tenham curtido bastante e quero ouvir o feedback de vocês!
Referências sobre Sistemas de Recomendações
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Introdução ao Business Intelligence – Do Problema ao Dashboard
- Ambiente de Desenvolvimento para Business Intelligence
- Definições para Projetos de Business Intelligence
- Linguagem SQL e os Bancos de Dados Relacionais
- Modelagem de Dados para Business Intelligence
- ETL com Pentaho
- DataViz com Power BI
- Deploy do Airbyte com Docker
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
