

Chegamos a mais uma etapa do Business Intelligence – Do Problema Ao Dashboard. Vamos agora estabelecer as definições fundamentais em projetos de Business Intelligence. Se esse é o seu primeiro post de Business Intelligence aqui no Dados ao Cubo, confere a Introdução ao Business Intelligence – Do Problema ao Dashboard e a preparação do Ambiente de Desenvolvimento para Business Intelligence. Sem mais delongas, vamos explorar o que este artigo oferece.
Primeiramente entenderemos a definição do problema, para fechar o escopo de entrega do projeto. Dessa forma, podemos mapear as fontes de dados necessárias para resolução do problema. Assim, possibilitando identificar as fatos e dimensões (que veremos em detalhes na modelagem dos dados). Vamos precisar também estimar o esforço para execução do projeto. E por fim, vamos conhecer o projeto de Business Intelligence do Dados ao Cubo, que desenvolveremos ao longo das próximas etapas. Sem mais enrolação, vamos ao problema.
1. Definindo o Problema
Na fase de definição do problema, a clareza é fundamental. Aqui é crucial que todos os envolvidos compreendam claramente qual é o desafio a ser superado. Para avançar, devemos ter respostas afirmativas para questões como:
- O problema é passível de solução com Business Intelligence?
- Possuímos equipe para o desenvolvimento ou precisaremos de consultoria externa?
- Como será a manutenção do projeto após a implementação?
- Temos dados suficientes para o projeto de BI?
- Há orçamento disponível para o projeto de BI?
Essas perguntas são vitais para delinear o escopo e garantir uma compreensão clara dos projetos de Business Intelligence.
2. Mapeando as Fontes de Dados
Identificar todas as fontes de dados necessárias é uma etapa crucial. Estas fontes podem variar, desde bancos de dados internos até dados públicos, como os do IBGE.
A relevância das fontes de dados deve ser alinhada com a solução do problema, destacando a importância de uma definição de problema precisa.
3. Identificando Dimensões e Fatos
Com as fontes de dados identificadas, é hora de discernir entre dimensões e fatos. Essa informação é essencial para estimar o esforço do projeto, bem como para a visualização de dados.
A identificação de dimensões e fatos será fundamental na modelagem multidimensional. Então precisamos sempre identificar baseado nos problemas que vamos resolver.
4. Calculadora de Projetos Business Intelligence
Estimar o esforço em projetos de BI pode ser complexo, mas uma abordagem sistemática pode ajudar. Dividindo as atividades em ETL (Extração, Transformação e Carga) e DataViz (Visualização de Dados), podemos estimar o esforço necessário.
4.1. Esforço para ETL
Pensando na parte de ETL, podemos dividir as atividades por tipos, listar as atividades de cada tipo e atribuir uma quantidade de horas para cada atividade. Importante levar em consideração o esforço com base no número de dimensões e fatos. Vamos observar a imagem da tabela abaixo com um exemplo.

Caso identifique mais alguma atividade, pode incluir no seu modelo. Da mesma forma, pode excluir alguma atividade que não seja necessária no seu projeto.
Com seu modelo pronto, é só calcular de acordo com a quantidade de DIMENSÕES E FATOS do seu projeto. Vejamos um exemplo com 3 dimensões e 1 fato.
Para cada dimensão temos 5h, se temos 3, então 15h para as dimensões. Para cada fato um total de 12h, só temos 1 fato, logo somamos mais 12h. Adicionamos mais 5h para job de cargas e ajustes após homologação. Totalizando 32h até aqui, para finalizar vamos incluir 10% de gestão, 3,2h e 5% de risco 1,6h. Portanto, precisamos de aproximadamente 37h para execução da etapa de ETL do projeto.
4.2. Esforço para DataViz
Essa metodologia também se aplica à visualização de dados, onde o número de telas, filtros, gráficos, tabelas e botões impacta o esforço necessário. Vamos observar a imagem da tabela abaixo.
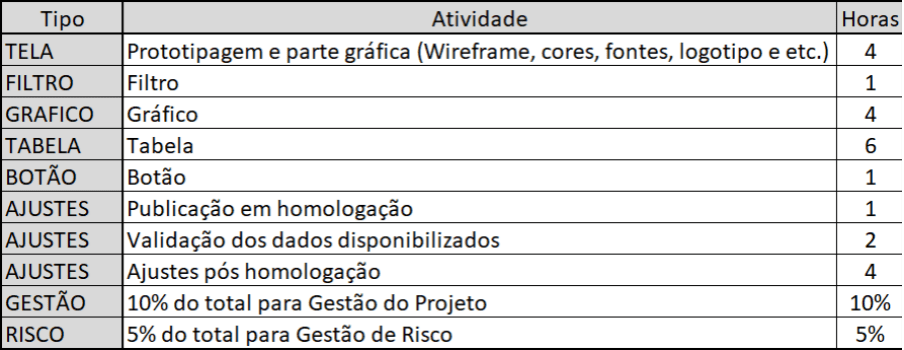
Assim, é só calcular de acordo com a quantidade de TELAS, FILTROS, GRÁFICOS, TABELAS e BOTÕES nos dashboards do seu projeto. Vejamos um exemplo com 1 tela, com 2 filtros, 3 gráficos, 1 tabela e sem botões.
Para a tela somamos 4h, cada filtro 1h, cada gráfico 4h e cada tabela 6h. Então temos até aqui, 24h. Acrescentamos 7h de ajustes e para finalizar vamos incluir 10% de gestão, 3,1h e 5% de risco 1,5h. Portanto, precisamos de aproximadamente 36h para execução da etapa de DataViz do projeto.
Preciso deixar claro que não existe um padrão para isso, e pode variar de acordo com cada projeto de BI e suas particularidades. Esse é o meu ponto de partida e em breve vou automatizar ele, criando uma calculadora em python para projetos de BI, mas deixo isso para outro post.
É notável que essa etapa de definição vai impactar diretamente em todo o projeto. Qualquer mudança seja por parte do cliente, limitação da ferramenta ou outro motivo é possível que seja preciso revisar algumas etapas do projeto.
5. Projeto de Business Intelligence do Dados ao Cubo
No exemplo prático, consideramos um projeto fictício para a “Florestas ao Cubo”. A empresa deseja ter controle sobre informações relacionadas a florestas plantadas. Então, para este projeto, utilizaremos dados do Portal Brasileiro de Dados Abertos. Importante estar atentos as questões da Lei Geral de Proteção de Dados Pessoais (LGPD), devemos sempre saber a origem e como tratar os dados que trabalhamos.

O portal é a ferramenta disponibilizada pelo governo. Para consulta de informações públicas, onde todos podem encontrar e utilizar os dados. Selecionamos informações do Sistema Nacional de Informações Florestais (SNIF).

O SNIF tem como objetivo, colecionar e produzir, organizar, armazenar, processar e disseminar dados, informações e conhecimentos sobre as florestas e o setor florestal brasileiro. Selecionamos a base de dados Florestas Plantadas – IBGE – 2014-2016 que tem informação da área de floresta plantada no Brasil por região, estados, municípios e espécie florestal.
5.1. Definições do Projeto
Sendo assim, a Florestas ao Cubo, uma empresa parceira, solicitou uma consultoria para ter controle sobre as informações relacionadas a essa base de dados. O projeto inclui indicadores como o total de florestas plantadas, distribuição por estados e municípios, proporção de espécies e regiões. Então, listamos as principais perguntas de negócio a serem respondidas:
- Qual o total de florestas plantadas?
- Qual o total de florestas plantadas por ano?
- Quais são os estados que mais plantaram? E os municípios?
- Qual a proporção das espécies de florestas plantadas?
- Qual a proporção por região das florestas plantadas?
Guarda com carinho todas essas perguntas, essas informações detalhadas sobre o problema são essenciais para a modelagem de dados e construção de visualizações.
Projetos de Business Intelligence
Portanto, agora que já temos essas informações sobre o problema da Florestas ao Cubo, delimitamos o escopo do que vai ser entregue, podemos seguir para as próximas etapas.
Com todas essas definições, estamos preparados para os próximos passos, que envolvem o uso do ambiente de desenvolvimento criado anteriormente. O aprendizado incluirá introdução a banco de dados relacionais, linguagem SQL e o mapeamento dos dados para iniciar a modelagem.
A compreensão desses conceitos é uma escada, e cada degrau é crucial para alcançar o topo. Juntos, vamos explorar o mundo do Business Intelligence. Até a próxima etapa!
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Agrupamento com scikit-learn
- Álgebra Linear com NumPy
- Geometria Analítica com SymPy
- Ciência de Dados para Mercado de Ações Parte I
- Ciência de Dados para Mercado de Ações Parte II
- Utilizando Python no Portal Brasileiro de Dados Abertos Parte I
- Trabalhar com Arquivo de Texto em Python
- Análise de Dados com Scikit Learn Python
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
