

E ai pessoal, tudo bem por aí? Dando continuidade a minha última publicação, dessa forma, hoje vamos falar da aplicação prática da Estatística Descritiva Univariada utilizando a linguagem Python na Análise Exploratória de Dados. Então, caso ainda não tenha visto a minha postagem anterior, abordando um pouco da teoria, confere lá a Estatística Descritiva Univariada. Antes de mais nada vamos entender o que é essa tal Análise Exploratória de Dados.
Análise Exploratória de Dados (AED)
A Análise Exploratória de Dados(do inglês, EDA – Exploratory Data Analysis) começa antes da aplicação de qualquer técnica estatística. É nessa etapa que conhecemos a fundo os nossos dados, fazendo uso de algumas ferramentas de estatísticas e de visualização.
A Análise Exploratória de Dados vai além do uso descritivo da estatística, é olhar de forma mais profunda os dados, sem resumir muito a quantidade e qualidade das informações.
É de suma importância que executemos essa fase com total cuidado e atenção antes de realizarmos qualquer outro tipo mais avançado de tratamento nos dados. Uma AED mal realizada pode levar a erros e complicações na base de dados, uma má interpretação das questões importantes e que agreguem maior valor, e na pior das hipóteses, a total invalidação da análise (por exemplo, se os dados disponíveis forem totalmente incapazes de responder às questões levantadas).
Uma parte crucial, mas que geralmente é vista superficialmente ou subvalorizada por quem está começando empolgado, é a estatística. A estatística é a base teórica da ciência de dados, sem ela não seria possível desenvolver com segurança nenhum dos modelos ou algoritmos que fazemos uso hoje.
Portanto, como cientistas de dados, nossa missão é contar histórias utilizando dados, e é muito difícil contar uma boa história a partir dos dados sem usar estatística. Assim, para nos ajudar nessa missão da análise exploratória de dados vamos entender o conceito de variáveis e os tipos de variáveis que temos.
Variáveis
Durante o processo de amostragem(retirar uma parte da base), não coletamos apenas a informação do que realmente temos interesse, mas também muitas outras informações que nos ajudarão no entendimento dos dados e do resultado que desejamos alcançar.
Cada uma das características da população amostrada, como peso, altura, sexo ou idade, é denominada de uma variável.As variáveis podem assumir valores distintos, que basicamente podemos separá-los em Numéricos (variáveis quantitativa) ou Categóricos (variáveis qualitativas). Então, vamos ver abaixo como ficam divididas essa classificação das variáveis:
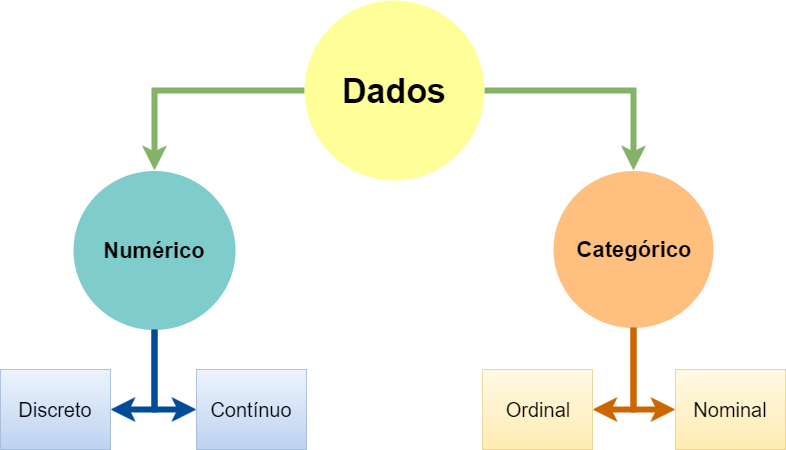
Agora vamos entender melhor cada tipo de variável.
Classificação de variáveis
As variáveis numéricas podem ser dos tipos::
- Discretas: possuem apenas valores inteiros. Ex.: número de irmãos, número de passageiros.
- Contínuas: possuem qualquer valor, incluindo números reais(float). Ex.: peso, altura.
As variáveis categóricas podem ser dos tipos::
- Nominais: quando as categorias não possam ser ordenadas de alguma maneira. Ex.: nomes, cores, sexo.
- Ordinais: nesse caso as categorias podem ser ordenadas. Ex.: tamanho (pequeno, médio, grande), classe social (baixa, média, alta), grau de instrução (básico, médio, graduação, pós-graduação).
Bem, depois dessa breve introdução, vamos a prática! Vamos fundamentar um pouco nossas bases em estatística e ver algumas das principais técnicas para a AED com a biblioteca Pandas em Python.
Análise Exploratória de Dados com Python
Primeiramente importamos as bibliotecas principais para essa atividade.
# np é uma convenção para o numpy, convenção é um acordo # estabelecido com o intuito de padronizar e facilitar o entendimento. import numpy as np # pd é uma convenção de alias para o pandas. import pandas as pd # sns é uma convenção de alias para o seaborn. import seaborn as sns
Agora vamos importar o dataset iris da biblioteca scikit-learn e utilizar algumas funções de análise dos dados.
from sklearn.datasets import load_iris iris = load_iris() # selecionando as colunas de 0 a 4 para a variável X, o 5 foi declarado, # mas por padrão ele não é considerado. X = iris.data[:, 0:5] # definindo o y na variável targer, essa será nossa variavel dependente y = iris.target feature_names = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] target_names = ['setosa', 'versicolor', 'virginica'] X = pd.DataFrame(X, columns=feature_names) # utilizamos o head para exibir as primeiras linhas do dataframe (por padrão 5), # no nosso exemplo vamos exibir apenas as 2 primeiras. X.head(2)
Então temos a imagem abaixo com as duas primeiras linhas dos Data Frame.

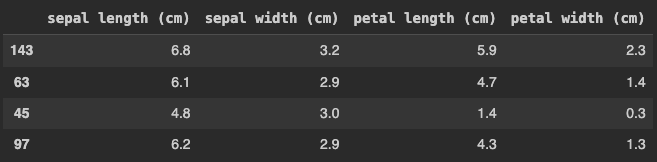
Além das primeiras linhas, também podemos exibir uma amostra aleatória.
# Retorna uma amostra (aleatória) de n elementos, no nosso exemplo 4 elementos X.sample(4)
Assim, temos a amostra aleatória a seguir.
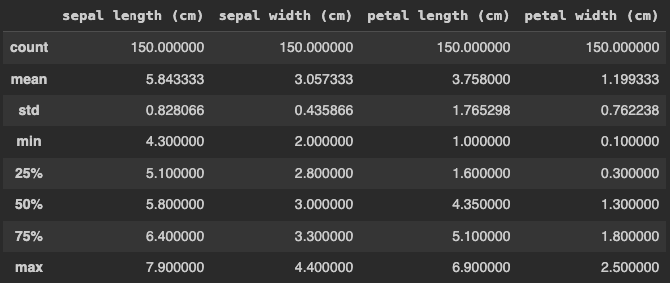
Ainda podemos exibir algumas métricas estatísticas básica com uma função do próprio Pandas.
# Retorna uma descrição do dataset X.describe()
Então, confere a imagem com o resultado da função describe do Pandas.
Agora que já tivemos uma breve amostra dos dados, é hora de conferir as principais medidas estatísticas utilizadas na análise exploratória de dados.
Média
A média ou média aritmética, nada mais é do que a soma de todos os dados da amostra dividido pela quantidade de amostras. Abaixo um exemplo de utilização da função mean(), função esta que calcula a média de um conjunto de dados.
# Média da coluna
media = X['sepal length (cm)'].mean()
print("Média ", media)
Média 5.843333333333335Mediana
Mediana é o valor representado pela amostra central, estando as amostras ordenadas em valores crescentes, caso o total de elementos for par, será necessário calcular a média dos dois valores centrais. Abaixo a função median(), calcula a mediana do conjunto de dados.
# Mediana da coluna
mediana = X['sepal length (cm)'].median()
print("Mediana ", mediana)
Mediana 5.8Moda
A Moda é o valor que aparece com mais frequência em um conjunto de dados, ou seja, o valor que se repete mais vezes. Para fazermos o cálculo da moda de um conjunto de dados, basta encontrar os dados que mais aparecem no conjunto.
# Moda da coluna
moda = X['sepal length (cm)'].mode()
print("Moda ", moda[0])
Moda 5.0Variância
A variância é uma medida de dispersão dos dados, mede o quão afastados os dados estão da média. Quanto maior a variância, mais afastados os dados encontram-se da média. Assim temos a variância populacional.
# Variância da coluna
variancia = X['sepal length (cm)'].var()
print("Variância ", variancia)
Variância 0.6856935123042505Desvio Padrão
O desvio padrão (standard deviation) é a raiz quadrada da variância. Toda discussão em relação à variância populacional Vs. amostral se aplica, com as devidas mudanças, ao desvio padrão.
# Desvio padrão da coluna
desvio = X['sepal length (cm)'].std()
print("Desvio padrão ", desvio)
Desvio padrão 0.8280661279778629Quantis
Quantis são pontos que dividem uma distribuição de probabilidade em partições de tamanhos iguais. Eles podem ser quartis (sendo o 1º quartil correspondente a 25% dos dados, o segundo quartil correspondente a 50% dos dados – a mediana e o 3º quartil correspondente a 75% dos dados) ou percentis (dividem a amostra em 100 partes).
Q1 = X['sepal length (cm)'].quantile(0.25)
Q2 = X['sepal length (cm)'].quantile(0.5)
Q3 = X['sepal length (cm)'].quantile(0.75)
print('Primeiro quartil ', Q1)
print('Segundo quartil (Mediana)', Q2)
print('Terceiro quartil ', Q3)
Primeiro quartil 5.1
Segundo quartil (Mediana) 5.8
Terceiro quartil 6.4Intervalo Interquartil (IQR)
O IQR (do inglês, Interquartile Range), é a diferença entre o terceiro e primeiro quartis: IQR = Q3−Q1. É uma medida de dispersão robusta muito utilizada, por exemplo, quando os dados contêm muitos outliers por ser menos sensível às variações nos extremos do conjunto.
IQR = Q3 - Q1
print('Intervalo interquartil ', IQR)
Intervalo interquartil 1.3000000000000007Boxplots
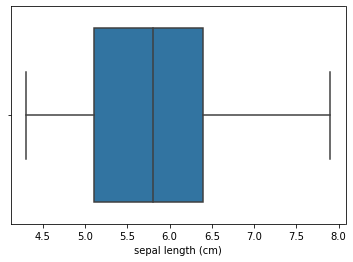
Boxplot é utilizado para avaliar e comparar o formato, tendência central e variabilidade de distribuições de amostra, e para procurar por outliers. Por padrão, um boxplot demonstra a mediana, os quartis, o intervalo interquartil(IQR) e outliers para cada variável.
Nesta imagem demonstramos como são exibidas esses dados no boxplot.
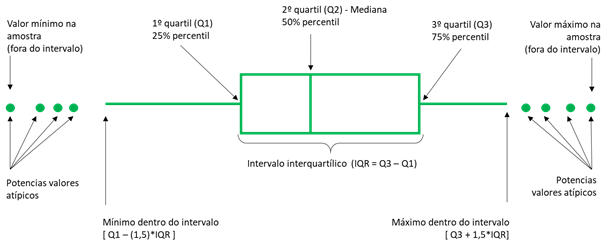
No jupyter notebook utilizamos a função .boxplot() da biblioteca gráfica Seaborn. Como demonstrado abaixo:
sns.boxplot(X['sepal length (cm)'])
Histogramas
Um histograma é uma visualização gráfica de dados usando barras de diferentes alturas. Em um histograma, cada barra agrupa números em intervalos. As barras mais altas mostram que mais dados estão nesse intervalo. Um histograma exibe a forma e distribuição de dados amostrais discretos ou contínuos.
sns.distplot(X['sepal length (cm)'])
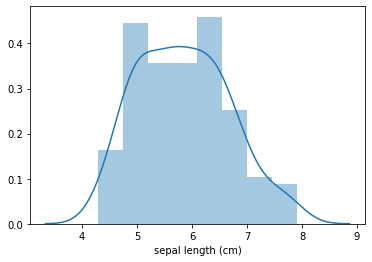
Vocês devem ter observado que utilizamos na célula acima a função distplot. Essa função combina a função hist da biblioteca matplotlib (com cálculo automático de um bom tamanho de bins¹ padrão) com as funções kdeplot (ajuste e plota uma estimativa de densidade de kernel univariada ou bivariada) e rugplot (plota um “tique” para cada ocorrência em uma variável do dataset) da biblioteca Seaborn.
¹ Dados numéricos em grupos de intervalos idênticos.
Assimetria (Skewness)
Assimetria é, na verdade, uma medida de simetria. Ela nos diz o quão simétrica é a distribuição dos dados em torno da média. E junto com a curtose (kurtosis) que veremos em seguida, é uma medida muito boa para informar a aparência ou forma da distribuição dos dados.
assimetria = X['sepal length (cm)'].skew()
print('Assimetria(Skewness) ', assimetria)
Assimetria(Skewness) 0.3149109566369728Curtose (Kurtosis)
A Curtose ou achatamento também é uma medida que nos ajuda a dar forma à distribuição dos dados. A curtose, diferente da assimetria, tenta capturar em uma medida a forma das caudas da distribuição.
curtose = X['sepal length (cm)'].kurtosis()
print('Curtose ', curtose)
Curtosis -0.5520640413156395Bem pessoal, acho que com esse conteúdo já dá pra explorar bastante os dados.
Análise Exploratória de Dados ao Cubo
Portanto, vimos como iniciar uma análise exploratória de dados com as principais medidas estatísticas. Dessa forma construimos um passo a passo na prática utilizando o Python para auxilixar na construção da EDA.
Mas não para por aqui, teremos mais conteúdos relacionados a análise exploratória de dados. Sendo assim, não deixem de nos acompanhar nas redes sociais para ficar sempre atualizado sobre nossas postagens, se vocês estão gostando, curtam, compartilhem, comentem…Todo feedback será bem vindo! Um abraço a todos e até a próxima!
Referências para Análise Exploratória de Dados
Para se Aprofundar ainda mais em Análise Exploratória de Dados
- Estatística Aplicada
- Estatística Prática Para Cientistas de Dados
- Machine Learning – Guia de Referência Rápida
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Introdução ao Business Intelligence – Do Problema ao Dashboard
- Ambiente de Desenvolvimento para Business Intelligence
- Definições para Projetos de Business Intelligence
- Linguagem SQL e os Bancos de Dados Relacionais
- Modelagem de Dados para Business Intelligence
- ETL com Pentaho
- DataViz com Power BI
- Organização de Arquivos e Pastas com Python
Então, convido você para se tornar Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando seu conhecimento com toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Tudo sobre o universo Data Science!

1 Comment
José Hilário Alves Neto
17 de julho de 2023Sensacional, conceitos básicos de Estatística usando Python.