

Fala galera viciada em dados! Espero que estejam todos bem e se cuidando. Hoje vou mostrar para você uma solução que usa técnicas avançadas de Machine Learning mas que tem uma biblioteca Python prontinha para a gente se divertir. Sabe o que Charlie Brown Jr tem haver com Machine Learning? Talvez nada, mas vamos usar uma de suas canções perfeitas para nossa brincadeira. Já ouviu falar de reconhecimento de voz? É isso mesmo, vamos pegar uma música no formato mp3 e converter para texto.
No final, terá um GitHub para fazer aquele clone maroto. Vamos rapidinho conhecer alguns conceitos das bibliotecas que vamos usar e #PartiuCode.
O que é a biblioteca SpeechRecognition?
A biblioteca SpeechRecognition foi desenvolvida para realizar reconhecimento de voz. O próprio termo Speech Recognition se traduzido para o português tem o significado de reconhecimento de voz. Essa é uma área interdisciplinar da ciência da computação e linguística computacional que tem como objetivo o reconhecimento e a tradução da linguagem falada para em texto por computadores.
Sendo assim, vamos utilizar essa biblioteca para fazer a transformação de um áudio em um texto. Falando assim parece bem simples, e de fato essa biblioteca faz a tarefa um tanto transparente para o programador. Em poucas linhas podemos fazer isso acontecer, mas para chegar nessa solução tem muitos anos de estudos por trás.
Mas, ainda precisaremos fazer uma conversão do arquivo de áudio de mp3 para wav. Depois dividir em partes menores para que possamos fazer o input dos dados no algoritmo. Assim, para essa tarefa vamos utilizar a biblioteca Pydub.
O que é a biblioteca Pydub?
A biblioteca Pydub, foi criada para manipulação de áudio de forma simples e alto nível. Com ela podemos fazer conversões de formatos, juntar ou dividir arquivos de áudio entre outras atividades. Aqui vamos ver algumas dessas funcionalidades. Então, chega de conversa e vamos ao que interessa!
Partiu Reconhecimento de Voz
O objetivo é aplicar reconhecimento de voz na música Vícios e Virtudes do CBJr. A música selecionada foi uma escolha aleatória de gosto pessoal, mas pode ser utilizado qualquer arquivo mp3 com o código que iremos construir.
Como spoiler do que estar por vir, olha a nuvem de palavras criada com o texto resultado da transformação.

Olhando essas palavras, e comparando com a letra original, será que o nosso algoritmo teve uma boa performance? A resposta dessa pergunta vamos ver nas próximas etapas.
Instalando e Importando Bibliotecas
Primeiramente, vamos começar instalando algumas bibliotecas que vamos utilizar ao longo de nossos solução. são elas a SpeechRecognition e a pydub, que vão ser instaladas com os códigos abaixos
pip install SpeechRecognition pip install pydub
Após a instalação vamos importar essas bibliotecas Matplotlib e WordCloud que são bibliotecas gráficas.
import speech_recognition as sr from pydub import AudioSegment from pydub.utils import make_chunks import matplotlib.pyplot as plt from wordcloud import WordCloud
Finalizados os imports necessários podemos começar a desenvolver a nossa solução.
Convertendo Arquivos de Áudio
A nossa primeira missão aqui será realizar a conversão do arquivo no formato mp3 para o formato wav. Essa conversão vai ser necessária, pois o algoritmo de reconhecimento de voz espera uma entrada de arquivo de áudio no formato wav.
Para esta etapa, vamos utilizar a biblioteca pydub. Serão três passos, primeiro vamos declarar as variáveis dos arquivos mp3 e wav. Em seguida vamos utilizar a função AudioSegment para realizar a conversão e finalizando com a função export para gerar o novo arquivo.
# arquivos audio_mp3 = 'Vicios_e_Virtudes.mp3' audio_wav = 'Vicios_e_Virtudes.wav' # conversão de mp3 para wav sound = AudioSegment.from_mp3(audio_mp3) sound.export(audio_wav, format='wav')
Agora já temos o nosso arquivo no formato esperado, vamos a mais uma missão antes de realizar o reconhecimento de voz.
Dividindo Arquivos de Áudio
Mas uma necessidade do algoritmo de reconhecimento de voz é ter pequenos arquivos de áudio para realizar a tradução. Então, vamos dividir o nosso arquivo em pequenas partes.
Aqui nesta etapa novamente vamos utilizar a biblioteca pydub. E a função que vai realizar a divisão é a make_chunks. Esta função realiza a divisão do arquivo de áudio em tamanhos iguais, que vai ser definido na variável tamanho e vai estar em milisegundos.
# selecionando audio
audio = AudioSegment.from_file(audio_wav, 'wav')
# Tamanho em milisegundos
tamanho = 30000
# divisão do audio em partes
partes = make_chunks (audio, tamanho)
partes_audio =[]
for i, parte in enumerate(partes):
# Enumerando arquivo particionado
parte_name = 'Vicios{0}.wav'.format(i)
# Guardando os nomes das partições em uma lista
partes_audio.append(parte_name)
# Exportando arquivos
parte.export(parte_name, format='wav')O trecho de código acima vai realizar a divisão do áudio original e exportar as partes fracionadas, para que possamos realizar o reconhecimento de cada uma delas.
Função para Reconhecimento de Voz
Para realizar o reconhecimento de voz, foi criada a função transcreve_audio. a função vai receber o nome do arquivo de áudio e vai retornar a variável texto, com a transcrição ou com erro apresentado.
Em detalhes técnicos, vamos utilizar as funções Recognizer e record para ler o arquivo de áudio. Em seguida, utilizaremos a função recognize_google para fazer a transcrição do arquivo de áudio para texto. Veja os detalhes no trecho de código abaixo.
def transcreve_audio(nome_audio):
# Selecione o audio para reconhecimento
r = sr.Recognizer()
with sr.AudioFile(nome_audio) as source:
audio = r.record(source) # leitura do arquivo de audio
# Reconhecimento usando o Google Speech Recognition
try:
print('Google Speech Recognition: ' + r.recognize_google(audio,language='pt-BR'))
texto = r.recognize_google(audio,language='pt-BR')
except sr.UnknownValueError:
print('Google Speech Recognition NÃO ENTENDEU o audio')
texto = ''
except sr.RequestError as e:
print('Erro ao solicitar resultados do serviço Google Speech Recognition; {0}'.format(e))
texto = ''
return textoCom a função criada, só precisamos aplicar a mesma em cada parte do arquivo que dividimos. Então vamos lá!
Transformação do Áudio em Texto
Chegou a hora de ver o resultado da nossa solução. Criaremos uma string vazia com a variável texto, e um loop for para aplicar a função transcreve_audio em todas as partes que criamos do arquivo .
# Aplicando a função de reconhecimento de voz em cada parte texto = '' for parte in partes_audio: texto = texto + ' ' + transcreve_audio(parte)
Então, esse é o resultado do nosso reconhecimento de voz.

Abaixo uma análise em breve e bem básica somente para efeito de comparação da canção original e a transformação em texto.
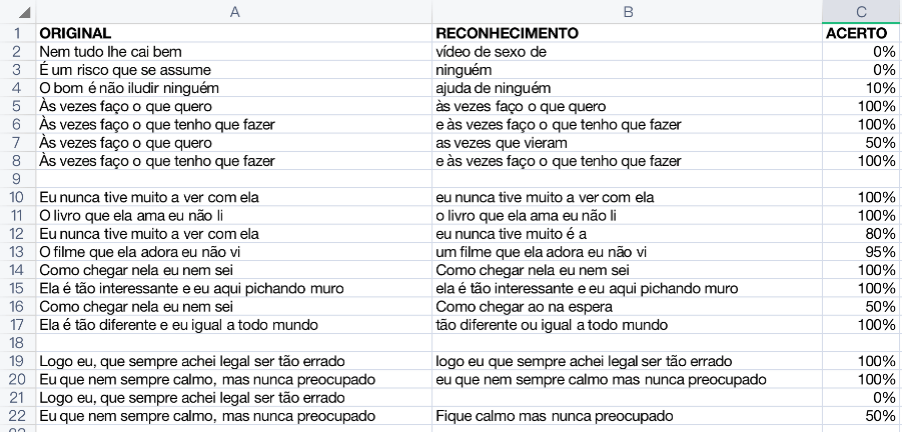
Podemos ver que apesar de alguns erros o algoritmo de reconhecimento de voz performa muito bem. Sendo assim, temos na imagem acima na coluna A a letra original, na coluna B a letra após o reconhecimento de voz e na coluna C o percentual de acerto.
Reconhecimento de Voz ao Cubo
Essa foi uma breve introdução do que pode ser feito com a biblioteca SpeechRecognition. A área de linguagem natural é um campo bem amplo e tem muito a ser desbravado, mas com o que tem pronto em Python dá se fazer muita coisa legal.
A avaliação final do percentual de acerto foi feita de forma manual, apenas para ficar didático. Mas já tem muitos estudos nesse sentido e uma dica para próximo post seria verificar a qualidade do algoritmo com métricas estatísticas de similaridade entres textos.
Portanto, espero que você tenha curtido o conteúdo, no GitHub do Dados ao Cubo você encontra o notebook e a música utilizada na solução. Além disso, não esqueça de mandar aquele feedback e compartilhar nosso conteúdo com a comunidade.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos anteriores também do Dados ao Cubo, sempre falando sobre o mundo dos dados.
- NLP com scikit-learn
- Processamento de Linguagem Natural com TensorFlow
- Modelos em Produção com Streamlit
- Deploy de Modelos com Heroku
- Agrupamento com scikit-learn
- Deletar Dados com Streamlit e o PostgreSQL
- Análise de Dados com Numpy Python
- Pipeline de Dados Airbyte com GA4 e Snowflake
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
