

Fala galera! Espero que esteja tudo bem com vocês. Já falamos aqui de vários modelos de machine learning! Mas e agora? Meus modelos treinados vão ficar para sempre no Jupyter ou no colab? Claro que não. Consigo deixar mais profissa de uma forma SIMPLES? A resposta é SIM! E é o que vou te mostrar aqui, agora.
Senso assim, vou te apresentar um framework para colocar seus modelos de machine learning em “produção”. Nada de outro mundo, coisa simples e de fácil implementação. Portanto, vamos utilizar o modelo que fizemos sobre NLP, não lembra ou não viu, só conferir o post NLP com scikit-learn. Primeiramente vamos conhecer agora que framework é esse.
Framework Streamlit
O streamlit é um framework open-source, que constrói aplicações web. Como ele foi desenvolvido pensando na área de ciência de dados, então é de fácil utilização. Como diz na própria página do streamlit “Tudo em python. Tudo de graça.”.
Aqui vou te mostrar as opções de exibição, algumas formas de interação com o usuário e como trabalhar com arquivos externos. Nunca se esqueça de consultar a documentação, em qualquer ferramenta, deve ser sua fonte primária de informação.
Instalar o pacote
Se for a primeira vez que for construir uma aplicação com o streamlit, é possível que precise instalar o pacote. Utilize o comando em python abaixo:
pip install streamlit
Importando o pacote
Na aplicação é preciso importar a biblioteca do streamlit como qualquer outra. Utilize o comando em python abaixo:
import streamlit as st
Executando a aplicação
Para executar uma aplicação que utiliza o streamlit salvo em um arquivo do tipo python (extensão .py). Utilize o comando em python abaixo:
streamlit run app.py
Será aberto o app no seu navegador padrão com o endereço (http://localhost:8501/), sendo transparente para o usuário como está sendo executado por trás da aplicação.
Agora podemos conhecer as opções de exibição disponíveis.
Opções de Exibição no Streamlit
Conforme as necessidades, com apenas uma linha de comando podemos exibir na aplicação, textos, tabelas, mídias (imagens, áudio e vídeo) e gráficos. De uma forma bem simples, vamos ver.
Texto
Existem algumas formas de inserir o textos com uma certa formatação para facilitar o desenvolvimento. Vamos ver 3 delas e como utilizamos no streamlit
st.title('Classificação Mercadológica')
st.subheader('**Classificação com NLP**')
st.markdown('Este app faz a classificação mercadológica, a partir da descrição…)Abaixo podemos ver na imagem como é exibido, em amarelo o título (st.title), em azul o subtítulo (st.subheader) e em verde o texto (st.markdown) em formato markdown.

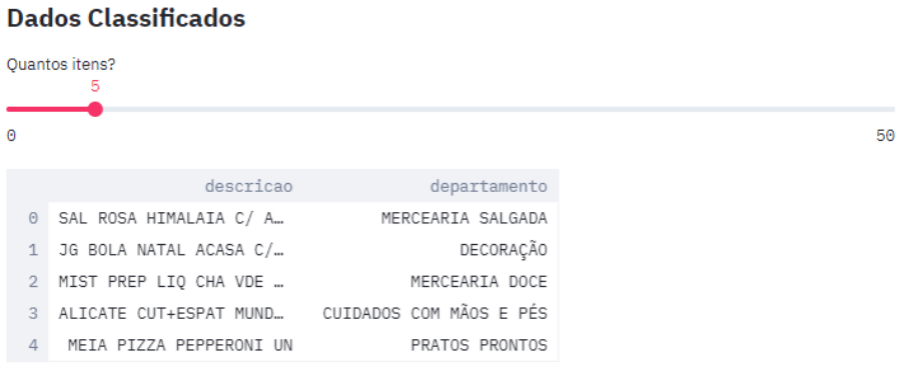
Dados
Os dados formatados em tabelas podem ser exibidos facilmente através do código abaixo:
st.dataframe(df)
É exibida uma tabela com os dados do dataframe informado.
Mídia
Para exibir imagens na aplicação como a logo de uma empresa, com apenas uma linha, passamos a função, o caminho e o formato, como vemos no código python abaixo:
st.image('LogoD3.png', format='PNG')É exibida a logo na página da aplicação, como podemos ver na figura abaixo. Logo após a logo está o título, que está aí só para representar a aplicação.
É possível inserir áudio e vídeo de forma bem simples também, para a minha aplicação não foi necessária, caso você precise, basta consultar a documentação.

Gráficos
Podemos inserir gráficos pré formatados do próprio framework, ou se preferir, pode contar com o suporte a várias bibliotecas gráficas disponível no streamlit. A biblioteca mais básica é a famosa e já conhecida por nós a Matplotlib.
Vejamos o código para gerar um gráfico do tipo WordCloud.
all_words = ' '.join(s for s in df['nova_descricao'].values) # criar uma wordcloud wc = WordCloud(stopwords=stop_words, background_color="black", width=1600, height=800) wordcloud = wc.generate(all_words) # plotar wordcloud fig, ax = plt.subplots(figsize=(10,6)) ax.imshow(wordcloud, interpolation='bilinear') ax.set_axis_off() st.pyplot()
O comando st.pyplot() é o responsável por fazer a integração do matplotlib com o streamlit, exibindo o gráfico mostrado na imagem abaixo.

Interações com Usuário no Streamlit
De acordo com a necessidade, é possível interagir com o usuário de diversas formas através do streamlit desde botões até formas de seleções.
Botões
Podemos inserir botões como o Link Exemplo, que está logo após o texto na imagem abaixo. Conforme o código Python a seguir.
if st.button('Link Exemplo'):
exemplo = pd.read_csv('https://raw.githubusercontent.com/dadosaocubo/streamlit/master/itens.csv')
st.markdown(get_download(exemplo, 'itens'), unsafe_allow_html=True)Na nossa aplicação ao acionar o botão é apresentado o link de download do exemplo de itens que pode ser baixado pelo usuário.

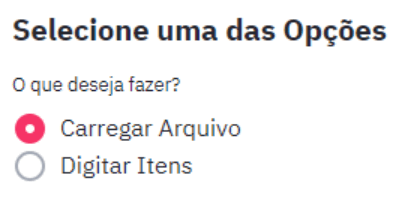
Radio
O radio é uma forma de seleção exclusiva, em outras palavras, ou você escolhe uma ou outra opção, vamos ver como fica em python.
st.subheader('**Selecione uma das Opções**')
options = st.radio('O que deseja fazer?',('Carregar Arquivo', 'Digitar Itens'))
if options == 'Carregar Arquivo':
code
if options == 'Digitar Itens':
codeNa nossa aplicação cada uma das opções geram geram outras instruções no programa. Uma opção permite o carregamento de arquivo csv e a outra a inserção de itens pelo usuário.
Checkbox
O checkbox é uma forma de seleção múltipla, onde o usuário pode fazer a seleção de um ou mais opções, vamos ver como fazer isso com python.
if st.checkbox('WordCloud'):
code
if st.checkbox('Top10 Departamentos'):
code
if st.checkbox('Bottom10 Departamentos'):
codeNa nossa aplicação, temos 3 opções de checkbox, que permite ao usuário gerar gráficos ao selecioná-las. A primeira opção gera um gráfico do tipo WordCloud, a segunda com os Top10 Departamentos com mais itens e por último os Bottom10 Departamentos com menos itens. Conforme podemos ver na imagem abaixo.

Trabalhando com Arquivos no Streamlit
Podemos também trabalhar com arquivos externos, fazendo tanto upload, quanto download de arquivos.
Upload
Pode ser necessário, subir um conjunto de dados para trabalhar pela aplicação, neste caso fazemos um upload do arquivo. Em python fica da seguinte forma.
data = st.file_uploader('Escolha o dataset (.csv)', type = 'csv')
if data is not None:
df = pd.read_csv(data)É apresentada uma tela similar a imagem abaixo para ser feito o upload do arquivo, internamento uso a variável data para receber o caminho do arquivo através da função (st.file_uploader), usei um if somente para garantir que a variável data não está vazia. Após selecionar o arquivo crio o dataframe através da função (pd.read_csv).

Download
Para fazer o download precisamos criar uma função, tornando possível o usuário baixar o arquivo gerado após o processamento. Vejamos a função em python.
def get_download(df, arq):
csv = df.to_csv(index=False)
b64 = base64.b64encode(csv.encode()).decode()
href = f'<a href="data:file/csv;base64,{b64}" download="'+arq+'.csv">Download</a>'
return hrefPara chamar a função usamos a função de texto (st.markdown) do streamlit, segue comando exemplo em python.
st.markdown(get_download(exemplo, 'itens'), unsafe_allow_html=True)
Então é exibido um botão com o link para download, como vemos na imagem abaixo.

Onde a Mágica Acontece!
Agora precisamos compilar todas essas informações que vimos até aqui para sair a aplicação.
Criamos o nosso modelo que classifica o departamento no post NLP com scikit-learn. E vamos usar a função abaixo para carregar esse modelo treinado e retornar as predições com os departamentos. Passando apenas o dataframe com as descrições.
from joblib import load
def model(df):
cvt = load('models/cvt.joblib')
tfi = load('models/tfi.joblib')
clf = load('models/clf.joblib')
new_cvt = cvt.transform(df)
new_tfi = tfi.transform(new_cvt)
result = clf.predict(new_tfi)
return resultStreamlit ao Cubo
Dessa forma, vamos chegando ao fim de mais um post. Hoje vimos o framework streamlit e suas principais funcionalidades. Compilamos tudo isso, mas o modelo criado de NLP para colocar uma aplicação em “produção”.
Então, esse é o resultado da aplicação como podemos ver na imagem abaixo.

Portanto, está disponível o código completo da aplicação no nosso GitHub. Não perca o próximo post, que vamos fazer o deploy dessa mesma aplicação no Heroku. Espero que tenham gostado e não esquece de deixar aquele feedback.
Referências Streamlit
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Análise de Dados para Detecção de Fraude
- Métodos de Classificação para Classes Desbalanceadas
- Análise de Dados: Detecção de Fraude de Cartão de Crédito
- Compreendendo Agile BI – Parte I
- Agile BI na Prática – Parte II
- Condicionais em Python
- Polars vs. Pandas: Explorando as principais funções para análise de dados
- Série de Automatização de Tarefas com Python
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Por fim, não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀

7 Comments
Leandro Custodio (@Leandropcustodi)
6 de março de 2021Cara, que post incrível. Ajudou muito, em poucos minutos e com essas dicas, vi que já dá pra fazer muita coisa. Valeu mesmo.
Tiago Dias
8 de março de 2021Show Leandro! Que bom que o objetivo do Dados ao Cubo está sendo atingido. Ajudar a comunidade de dados sempre.
jonatapaulino
13 de maio de 2021Amigo, muito bom seu post, parabéns. Daria pra eu trabalhar com três base, e nesse caso, o usuário escolher quais filtros ele quer fazer e em qual base ele quer fazer? Obrigado.
Tiago Dias
26 de junho de 2021Fala Jonata! Obrigado. As possibilidades são muitas, dá para trabalhar com várias base sim, e no código vc dá opção para o usuário escolher. Abraço!
Marketing To Alot Of People
16 de agosto de 2023My coder is trying to persuade me to move
to .net from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a variety of
websites for about a year and am nervous about switching to another platform.
I have heard excellent things about blogengine.net. Is there a way I
can transfer all my wordpress content into it? Any kind of help
would be really appreciated!
Jackson
27 de setembro de 2023Incredible points. Sound arguments. Keep up the amazing spirit.
fioricet without codeine
17 de novembro de 2023Hi there, I enjoy reading through your article.
I like to write a little comment to support you.