

Iniciamos nossa série sobre detecção de fraude com o artigo Análise de Dados para Detecção de Fraude, onde contextualizamos o tema. Aprofundamos nos aspectos teóricos da escolha do modelo para dados desbalanceados, Métodos de Classificação para Classes Desbalanceadas. Agora vamos aplicar alguns dos conceitos estudados em um problema prático. Vamos utilizar a linguagem de programação Python e algumas de suas principais bibliotecas (pandas, numpy, scikit-learn e outras) para resolver nosso problema de negócio.
Problema de Negócio
Iniciamos o nosso projeto com a definição e contextualização do problema de negócio. Sendo assim, vamos supor o seguinte cenário hipotético. Somos uma empresa de cartão de crédito europeia e precisamos garantir que os nossos clientes não sejam vítimas de fraude. Tentamos ao máximo ter processos de detecção eficientes para que a fraude seja evitada.
O time de sucesso do cliente está preocupado com a possível classificação de bons clientes como suspeitos (falso positivo, erro do tipo I). Então, querem garantir que o sistema de detecção cometa o menor erro possível. Evitando ao máximo a classificação equivocada de um cliente. Em conversa listaram os principais problemas que esse tipo de erro pode causar para o negócio:
- Prejuízo para o varejista, em especial os pequenos, pois compromete a conversão do cliente. Ele pode perder além do valor da compra, todo o investimento feito para aquisição do cliente.
- Prejudica a reputação da empresa no mercado. Fraude não se refere apenas a proteção, mas também viabilizar a compra.
- Prejuízo para a credibilidade da empresa, além dos custos com a transação a empresa pode ter prejuízos por ter muitos clientes detratores relatando reclamações nas redes.

Dessa forma, temos os seguintes objetivos:
- Aprovar o maior número possível de clientes automaticamente.
- Não prejudicar outros negócios com muitas barreiras para aprovação.
- Prezar sempre pela relação de confiança com os clientes, partimos do ponto de que todos são bons.
Diante dos problemas que uma classificação equivocada de um cliente, pode causar. A empresa precisa saber se é possível incluir os custos operacionais de uma fraude ou bloqueio do cliente nos critérios para a detecção de fraude. A empresa entende que fraudes sempre vão ocorrer e preferem arcar com o custo de algumas a perder o cliente. Eles podem ser considerados na avaliação final.
- Como podemos evitar ao máximo classificações equivocadas?
- Podemos utilizar o custo para avaliar qual a melhor forma de detectar fraudes?
- Como podemos garantir eficiência no tempo para avaliação da transação e transparência sobre os critérios usados?
Análise de dados
Conforme falamos no artigo, Métodos de Classificação para Classes Desbalanceadas, podemos usar Algoritmos Sensíveis ao Custo para incorporar os custos da fraude aos critérios de ajustes do modelo. Nas etapas seguintes, vamos executar etapas para construção do modelo de detecção de fraude: limpeza, tratamento, análise exploratória, construção e avaliação do modelo.

Enfim vamos à parte prática, agora iremos fazer uma análise dos dados e criar o nosso modelo. Abaixo destacamos as principais etapas, mas ao final do artigo deixamos o link para ter acesso ao material completo.
Leitura dos Dados
Utilizamos a biblioteca pandas para importar os nossos dado. Em seguida verificamos se os dados foram importados corretamente de acordo com o esperado:
dados = pd.read_csv('creditcard.csv', index_col=None)
dados.shape
classe = dados.values[:,-1]
counter = Counter(classe)
for c1, c2 in counter.items():
c3 = c2 / len(classe) * 100
print('Classe=%d, Contagem=%d, Porcentagem=%.3f%%' % (c1, c2, c3))
dados.head()
dados.info()
# Verificar ser existe valores faltantes ou nulos
dados.isnull().sum()
dados.isin([0]).sum()Tratamento do Dados
Momento de verificar se há inconsistências nos dados, como valores ausentes e duplicação. Foram identificados valores nulos nas variáveis ‘Time’ (2) e ‘Amount’ (1825). Como se trata de transações no cartão de crédito, não faz sentido ter ‘Amount’ zero. Como não tenho orientação da área de negócio sobre como lidar com essas informações, optamos por substituir esses valores pela média. Da seguinte forma, utilizando a função “SimpleImputer” da biblioteca scikit-learn:
imputer = SimpleImputer(missing_values=np.nan, strategy='mean') imputer = imputer.fit(dados) dados_missmean = imputer.transform(dados) dados_mean = pd.DataFrame(dados_missmean, columns=names)
Análise Exploratória
Estamos à procura de evidências que auxiliem na construção do nosso modelo e insights relevantes para o negócio.
Verificamos visualmente como está distribuída os casos de fraude e não fraude:
heigths = [284315,492]
bars_name = ('Não Fraude','Fraude')
y_pos = np.arange(len(bars_name))
plt.figure(figsize=(7,5))
sns.countplot(dados['Class'])
plt.xticks(y_pos,bars_name)
plt.title("Tipo de transação", fontsize=15)
plt.xlabel("Classe", fontsize=12)
plt.ylabel("Frequência", fontsize=12)
plt.show()
Vamos agora verificar como se comporta os valores da transação para casos de fraude e não fraude:
# Resumo estatístico
fraude = dados[dados['Class'] == 1]
normal = dados[dados['Class'] == 0]
print("Fraude - resumo estatístico")
print(fraude["Amount"].describe())
print("\nNão Fraude - resumo estatístico")
print(normal["Amount"].describe())
Outra variável que podemos analisar é o decorrido entre a realização da transação e o registro no banco de dados. Aplicamos uma transformação passando os valores de segundos para minutos e verificamos o seu comportamento:
timedelta = pd.to_timedelta(dados['Time'], unit='s')
dados['Time_min'] = (timedelta.dt.components.minutes).astype(int)
plt.figure(figsize=(7,5))
ax1 = sns.boxplot(x ="Class",y="Time_min", data=dados)
ax1.set_title("Tipo de transação e tempo de registro", fontsize=15)
plt.xlabel("Não fraude Fraude", fontsize=12)
ax1.set_ylabel("Tempo de registro (minutos)", fontsize = 12)
Não iremos nos aprofundar nessa análise nas demais variáveis que são resultantes de transformações PCA. Para as variáveis analisadas acima, não notamos uma diferenciação de comportamento para o valor da compra e o tempo de registro da transação, entre os casos de fraude e não fraude. São variáveis que poderiam ser desconsideradas na construção do modelo de detecção de fraude.
Seleção de Atributos
Podemos utilizar modelos baseados em árvores para verificar a importância dos atributos. Uma importância maior normalmente indica que podemos elevar o erro do modelo, caso determinado atributo seja removido do modelo. Para o ajuste do modelo, separamos o conjunto de dados em “X” (variáveis explicativas) e “y” (variável preditora). Sendo o rótulo (y) é um vetor de tamanho m com um valor de classe para cada amostra. Os dados (X) devem estar em um array (m linhas por n colunas) numpy.
model = XGBClassifier()
model.fit(X, y)
importancia = model.feature_importances_
for i,v in enumerate(importancia):
print('Atributo: %0d, Score: %.3f' % (i,v))
plt.barh([x for x in range(len(importancia))], importancia)
plt.show(
Como podemos analisar entre os trinta atributos avaliados, apenas um teve maior destaque, com score de 0,38. Para essa análise iremos manter todos os atributos para a construção do modelo, consideramos que o baixo score da maioria dos atributos não possibilita tirar maiores conclusões.
Construção do modelo
Para a construção do modelo, temos que ter todos os atributos na mesma escala. Assim, podemos utilizar algoritmos sensíveis à escala dos dados. Normalização dos dados, vamos trazer os dados para a mesma escala. Aplicamos a função “scale” do scikit-learn.
Para a construção do modelo, optamos por construir a função “avaliar modelo” onde reunimos todas as operações necessárias para avaliar os modelos definidos. A função recebe um dicionário com os parâmetros do modelo e os dados separados e normalizados. A função irá executar os seguintes passos:
- Criação de uma tabela com as métricas de avaliação do modelo.
- Criação da figura que compara duas curvas de avaliação do modelo.
- Treino de cada modelo aplicando validação cruzada estratificada.
- Cálculo do valor predito e probabilidades para cada classe.
- Cálculo das métricas de avaliação.
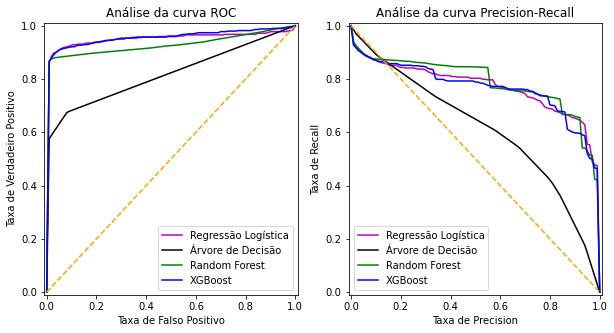
- Construção da curva ROC e AUPRC.
- Configuração e apresentação do gráfico das curvas ROC e AUPRC.
- Apresentação da tabela de medidas de avaliação do modelo.
def avaliar_modelo(models, X, y):
colors = ['m','k','g','b','r','c','y']
# Criação de uma tabela com as métricas de avaliação do modelo.
tabela_medias = {
'ROC AUC': [],
'AUPRC': [],
'Precision': [],
'Recall': [],
'Time': [],
}
# Criação da figura que compara duas curvas de avaliação do modelo
fig, (ax_roc, ax_precrecall) = plt.subplots(1, 2)
for model_idx, (model_name, model) in enumerate(models.items()):
cv = StratifiedKFold(n_splits=10)
fold_scores = {s : [] for s in tabela_medias}
fold_tprs = []
fold_recalls = []
base_fpr = np.linspace(0, 1, 101)
base_precision = np.linspace(0, 1, 101)
# Treino de cada modelo aplicando validação cruzada estratificada.
for i, (train, test) in enumerate(cv.split(X, y)):
xtr, xvl = X[train], X[test]
ytr, yvl = y[train], y[test]
fit_time = perf_counter()
model.fit(xtr, ytr)
fit_time = perf_counter() - fit_time
# Cálculo do valor predito e probabilidades para cada classe
y_pred = model.predict(xvl)
y_score = model.predict_proba(xvl)[:, 1]
precision, recall, _ = precision_recall_curve(yvl, y_score)
# Cálculo das métricas de avaliação
fold_scores['ROC AUC'].append(roc_auc_score(yvl, y_pred))
fold_scores['AUPRC'].append(auc(recall, precision))
fold_scores['Recall'].append(recall_score(yvl, y_pred,average='weighted'))
fold_scores['Precision'].append(precision_score(yvl, y_pred,average='weighted'))
fold_scores['Time'].append(fit_time)
fpr, tpr, _ = roc_curve(yvl, y_score)
tpr = np.interp(base_fpr, fpr, tpr)
tpr[0] = 0.0
fold_tprs.append(tpr)
recall = np.interp(base_precision, precision, recall)
recall[0] = 1.0
fold_recalls.append(recall)
# calcula médias das métricas
for nome_medida, lista_medidas in fold_scores.items():
tabela_medias[nome_medida].append(np.mean(lista_medidas))
# Construção da curva ROC e AUPRC
tprs = np.array(fold_tprs)
mean_tprs = tprs.mean(axis=0)
ax_roc.plot(base_fpr, mean_tprs, color=colors[model_idx], label=f"{model_name}")
# calcula e plota a curva PRECISION-RECALL média
recalls = np.array(fold_recalls)
mean_recalls = recalls.mean(axis=0)
ax_precrecall.plot(base_precision, mean_recalls, color=colors[model_idx], label=f"{model_name}")
# Configuração e apresentação do gráfico das curvas ROC e AUPRC
ax_roc.plot([0, 1], [0, 1], color='orange', linestyle='--')
ax_roc.axis(xmin=-0.01, xmax=1.01)
ax_roc.axis(ymin=-0.01, ymax=1.01)
ax_roc.set_title("Análise da curva ROC",fontsize=12)
ax_roc.set_ylabel('Taxa de Verdadeiro Positivo')
ax_roc.set_xlabel('Taxa de Falso Positivo')
ax_roc.legend()
ax_precrecall.plot([0, 1], [1, 0], color='orange', linestyle='--')
ax_precrecall.axis(xmin=-0.01, xmax=1.01)
ax_precrecall.axis(ymin=-0.01, ymax=1.01)
ax_precrecall.set_title("Análise da curva Precision-Recall",fontsize=12)
ax_precrecall.set_ylabel('Taxa de Recall')
ax_precrecall.set_xlabel('Taxa de Precision')
ax_precrecall.legend()
plt.subplots_adjust(hspace=0.5)
fig.set_size_inches(10,5)
plt.show()
# Apresentação da tabela de medidas de avaliação do modelo
df = pd.DataFrame(tabela_medias, index=models.keys())
return dfEntendemos que há vantagens e desvantagens ao agregar todas as operações em uma única função. Para esse caso optamos por construir uma única função após testar todas as operações de forma desagregada e entender que para a apresentação final do resultado a função agregada torna o código mais objetivo.
Avaliação e interpretação do modelo
Os modelos escolhidos para avaliação foram: Regressão Logística, Árvore de Decisão, Random Forest e XGBoost. Foram comparados a sua versão base e a versão ajustada para dados desbalanceados. Como o objetivo é avaliar a aplicação de Algoritmo Sensível ao Custo utilizando as funcionalidades do scikit-learn, a partir do ajuste do parâmetro “class_weight”, todos os outros parâmetros permanecem como o padrão. Para todos os modelos ajustados foram considerados “class_weight=’balanced’”, exceto para o XGBoost, onde o parâmetro foi declarado diretamente (scale_pos_weight=578), sendo o inverso da classe majoritária. Após a execução da função, foram obtidos os seguintes resultados:
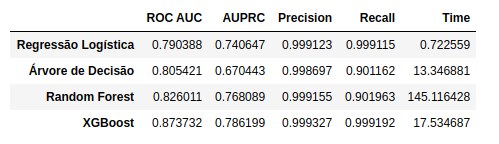
Modelos com dados desbalanceados

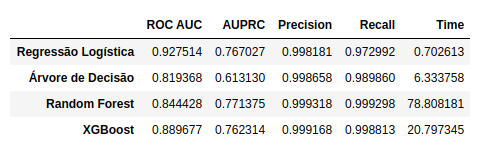
Modelos ajustado para dados desbalanceados
Interpretação
Regressão Logística: Com a ponderação temos uma melhora do resultado comparado ao modelo base: ROC AUC de 0,79 para 0,92 ; AUPRC de 0,74 para 0,76.
Árvore de Decisão: Com a ponderação quase não houve diferença do resultado comparado ao modelo base: ROC AUC de 0,816 para 0,817 ; AUPRC de 0,67 para 0,62. Esse modelo teve o pior desempenho entre os avaliados, mesmo com a ponderação os resultados não melhoraram.
Random Forest:Com a ponderação temos uma melhora do resultado comparado ao modelo base: ROC AUC de 0,83 para 0,84 ; AUPRC de 0,78 para 0,75.
XGBoost: Com a ponderação temos uma melhora do resultado comparado ao modelo base: ROC AUC de 0,87 para 0,88 ; AUPRC de 0,78 para 0,76.
Tempo: Como podemos notar algoritmos mais robustos apresentam melhores resultados, porém tem um tempo para ajuste do modelo muito superior, em especial com os dados não balanceados.
Métricas de avaliação: Como a medida Precicion-Recall (AUPRC) é mais preparada para lidar com classes extremamente desbalanceadas, não é tão impactada com a ponderação das classes como a ROC AUC. Demonstrando que para classes desbalanceadas é a melhor métrica de avaliação.
Como podemos ver pelos resultados, a AUPRC é menos sensível a número pequeno de previsões corretas ou incorretas, os valores não variam na mesma magnitude se comparado a AUC ROC. Não diverge com relação ao melhor modelo, porém a diferença é muito pequena entre os melhores modelos.
Resultado: Com o balanceamento dos dados a Regressão Logística é o modelo de classificação que obtém o melhor resultado em termos de métricas e tempo de ajuste, demorando menos de 1s.
Considerações Finais
Essa análise teve como foco o ajuste e avaliação de modelos de classificação para classes desbalanceadas. As principais conclusões são:
- A escolha por Algoritmo Sensível ao Custo é indicada para o problema, a partir dele conseguimos melhores resultados para os modelos avaliados em um menor tempo.
- Podemos incluir os custos para o negócio para classificação correta ou incorreta de fraude ou não fraude. Através de uma matriz de custos (construída pela área de negócio), que determinará a qualidade do modelo. A matriz irá minimizar o erro dos modelos nos dados de treinamento de forma flexível, incluindo regras de negócio.
- Critérios para a escolha do modelo: diante de dados muito desbalanceados, a métrica utilizada para a escolha do modelo foi a Precision-Recall AUC por ter foco na classe minoritária;
- Com o balanceamento dos dados, a Regressão Logística é o modelo de classificação que obtém o melhor resultado em termos de métricas e tempo de ajuste, demorando menos de 1s.
O código completo de Detecção de Fraude com todos os passos está disponível em nosso repositório no GitHub.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Introdução ao Business Intelligence – Do Problema ao Dashboard
- Ambiente de Desenvolvimento para Business Intelligence
- Definições para Projetos de Business Intelligence
- Linguagem SQL e os Bancos de Dados Relacionais
- Modelagem de Dados para Business Intelligence
- ETL com Pentaho
- DataViz com Power BI
- Visualizar Dados do Snowflake no Metabase
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Uma pessoa curiosa, que gosta de sempre aprender algo novo. Mestra em Demografia, Estaticista, Mestranda em Ciências no momento.
