

Estamos avançando no Business Intelligence – Do Problema Ao Dashboard. E agora temos uma missão muito importante no projeto, a modelagem de dados. Mas não pense que o caminho até aqui foi simples, já completamos muitas etapas antes de partir para a modelagem de dados. Confere nossa caminhada para chegar até aqui:
- Introdução ao Business Intelligence – Do Problema Ao Dashboard
- Ambiente de Desenvolvimento para Business Intelligence
- Definições para Projetos de Business Intelligence
- Linguagem SQL e os Bancos de Dados Relacionais
Então, já vimos todas as etapas da caminhada, vamos ver o que nos aguarda neste artigo.
Primeiramente veremos alguns conceitos sobre bancos de dados multidimensionais, modelagem de fatos e dimensões, operações em cubos e por fim, iremos modelar o projeto de BI do Dados ao Cubo.
1. Banco de Dados Multidimensional
Essa técnica é utilizada em projetos de BI, aplicados nos dados relacionais, que aprendemos na etapa anterior. A modelagem multidimensional (também conhecida como modelagem dimensional) é baseada nas estruturas de Fatos e Dimensões (veremos em detalhes essas duas estruturas daqui a pouco). Esse modelo de trabalho é ideal para estruturação de dados em um Data Warehouse (DW). A dimensão é o que dá personalidade e qualidade aos “Fatos” ocorridos, é a dimensão que nos permite visualizar as informações por diversos aspectos. Assim é possível estruturar os dados em cubos (junção entre dimensões e fatos) por assuntos, de forma a entregar mais resultados para o usuário que vai consumir essas informações.
Para esse tipo de modelagem podemos utilizar dois modelos como base:
- Star Schema – Mais simples de trabalhar e entender. Todas as dimensões se relacionam com uma ou mais fatos.
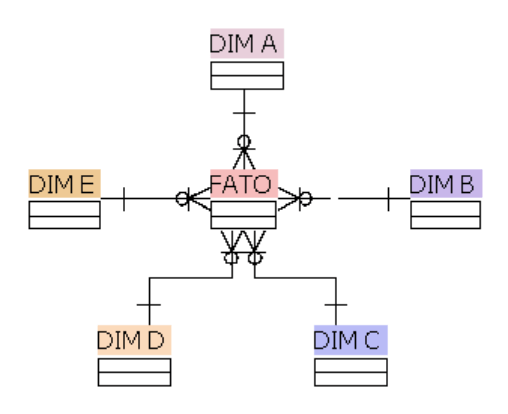
- Snowflake – Nesse modelo fica um pouco mais complicado o trabalho e o entendimento. As dimensões além de ligadas a fato, podem ter outras dimensões auxiliares.
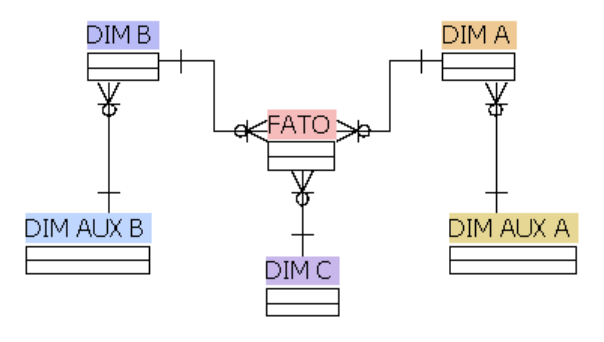
O modelo Star Schema é o mais recomendado para projetos de BI. Isso não é uma regra, e nem estamos falando que o Snowflake não funciona. Mas pense no Star Schema como uma boa prática de BI.
Agora que já entendemos o que é o modelo multidimensional, precisamos entender onde esses dados ficarão armazenados.
1.1. Staging Area
Quando vamos realizar as cargas dos dados para o DW. Uma boa prática ,muitas vezes ignorada, é a utilização da staging area. Em tradução livre seria a área de preparação, é uma zona intermediária na etapa de ETL onde os dados dos bancos relacionais, são carregados diretamente. Só após os dados estarem copiados na staging area é que fazemos as devidas transformações nos dados para ser carregado no DW. Essa prática visa o não consumo de transações no banco de dados relacionais, uma ou mais operações SQL executadas de uma vez sobre determinada base de dados pode gerar bloqueios em tabelas do sistema transacional. Por esse motivo, deve ser feita uma cópia das tabelas de produção e após isto, na staging area serão aplicadas as transformações do ETL. Caso ocorram erros nas etapas de transformações, as cargas para o DW podem ser retomadas a partir da staging area.
1.2. Data Warehouse
O data warehouse (DW) pode ser definido da forma mais simples como um armazém de dados. Nele são consolidados os dados de diversas fontes internas e externas à empresa para auxiliar na tomada de decisão. Em projetos de business intelligence, o DW é peça fundamental. Para explorar os dados em um DW, podem ser utilizadas diversas ferramentas, a mais comum é a OLAP (Online Analytical Processing) em tradução livre Processo Analítico em Tempo Real.
1.3. Data Mart
O data mart (DM) é uma parte de um DW. Normalmente a criação do DM se dá pela necessidade do recorte de algum assunto específico do DW. O principal objetivo é suportar uma grande intensidade de consulta nos dados, sem impactar a performance do DW.
Sendo assim, precisamos compreender como transformar os nossos dados relacionais em dimensões e fatos. Para isso vamos utilizar o modelo Star Schema.
2. Modelagem de Dimensões e Fatos
Para a modelagem dos dados em dimensões e fatos, podemos pensar em atributos e métricas. Vejamos a imagem abaixo para ficar mais claro.
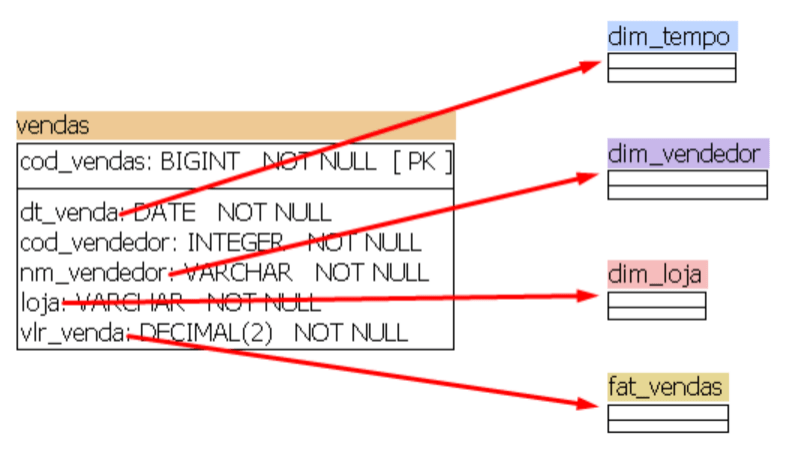
Pensando nessa tabela de venda, podemos identificar 3 dimensões e uma fato. Vamos entender os atributos, que são nossas dimensões, e as métricas que são nossas fatos.
2.1. Dimensões
Na nossa tabela de vendas, vimos o campo dt_venda, então, logo temos um atributo de tempo. Ou seja, temos a data (tempo) em que a venda foi efetuada. Dessa forma definimos a seguinte dimensão de tempo.
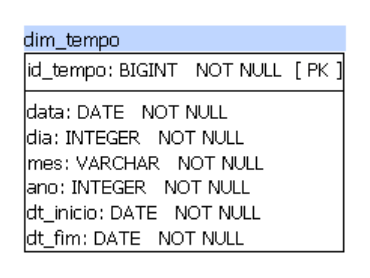
Com a dimensão de tempo, vai ser possível fazer uma análise temporal da métrica. Assim, podemos fazer agrupamentos das vendas por data, dia, mês ou ano como definimos na dim_tempo. Pode ser necessário incluir outras informações de tempo como trimestre, semestre ou outras relações com a data conforme o problema a ser resolvido.
A nossa próxima dimensão está relacionada com o atributo vendedor. A relação com a nossa tabela de vendas será através do campo cod_vendedor. Assim podemos definir a seguinte dimensão vendedor.

Com esse atributo, vai ser possível responder perguntas de vendas relacionadas aos vendedores. Com a dim_vendedor podemos identificar a média de vendas por vendedor, ou o melhor e o pior vendedor, por exemplo.
Para finalizar os atributos, temos a dimensão loja. O seu relacionamento com a tabela de vendas é através do campo loja. Sendo assim, podemos definir a dimensão loja.

Com o atributo loja, é possível identificar as lojas com mais vendas. Se relacionarmos com a dimensão de tempo, podemos ver as lojas com mais vendas em um dado período de tempo.
Em todas as nossas dimensões, temos dois campos importantes. A dt_inicio e df_fim, são informações para identificar as dimensões ativas, e guardar o histórico das dimensões, com suas devidas alterações ao longo do tempo.
2.2. Fatos
Enfim a fato, nossa métrica para análise. A fato de vendas vai estar relacionada com todas as dimensões através das chaves primárias de cada uma, que estarão como chaves estrangeira na tabela fato. Abaixo a modelagem dos dados identificando a fat_vendas.
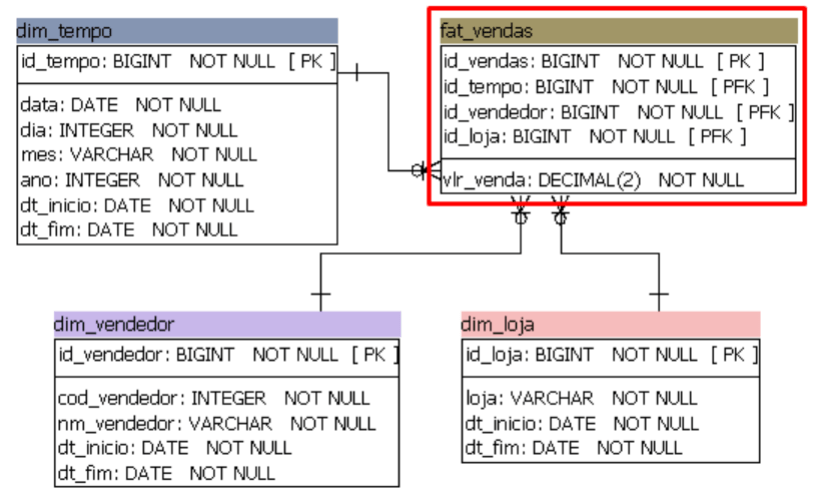
O campo da tabela de vendas que temos a métrica é o vlr_venda. Dessa forma podemos agregar o valor das vendas por quaisquer dimensões, ou uma combinação delas. Assim podemos identificar informações importantes sobre as vendas.
Dessa maneira, transformamos os nossos dados relacionais em cubo. Sendo assim, foi feita a modelagem multidimensional dos dados. Assim podemos fazer operações que vão gerar insights para o negócio.
3. Operações no Cubo de Dados
Na imagem abaixo, temos uma explicação visual das operações possíveis em um cubo de dados, vamos entender em detalhes cada uma delas.
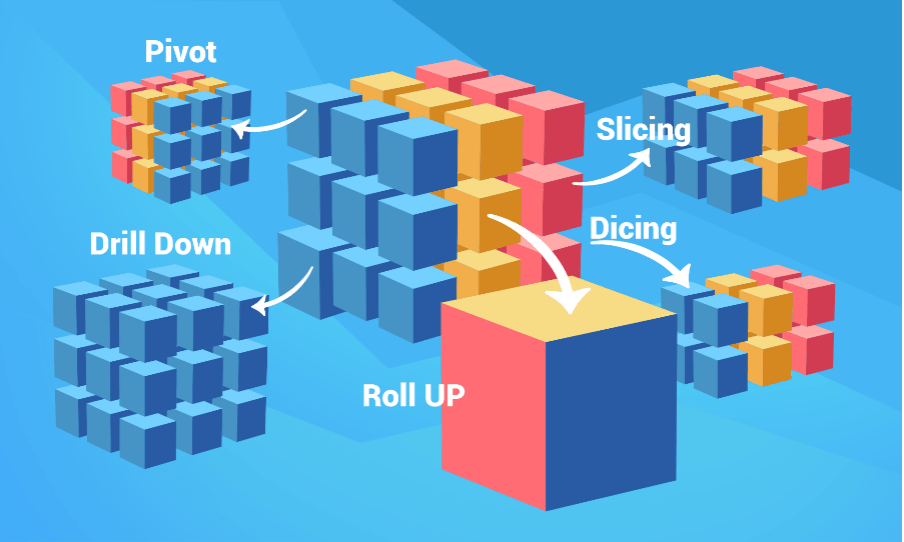
- Slicing – Fatiar os dados, seleção de uma dimensão.
- Dicing – Corte dos dados, seleção de duas ou mais dimensões.
- Pivot – Rotação dos dados, mudar a perspectiva de visualização.
- Drill Down – Detalhar os dados, examinar aumentando o detalhe dos dados.
- Roll UP – Generalizar os dados, diminuir o nível de detalhe dos dados.
Agora, chegou a hora de fazer a modelagem do projeto de business intelligence do Dados ao Cubo.
4. Modelando o Projeto de Business Intelligence do Dados ao Cubo
Agora que já começamos a entender a modelagem multidimensional, podemos aplicar ao projeto de BI do Dados ao Cubo. Vamos ver quais atributos e métricas identificamos na tabela rf_florestasplantadas_ibge para resolver os problemas levantados na etapa de definição do problema. Vale lembrar que os dados são referentes a reflorestamento no Brasil durante o período de 2014 a 2016.
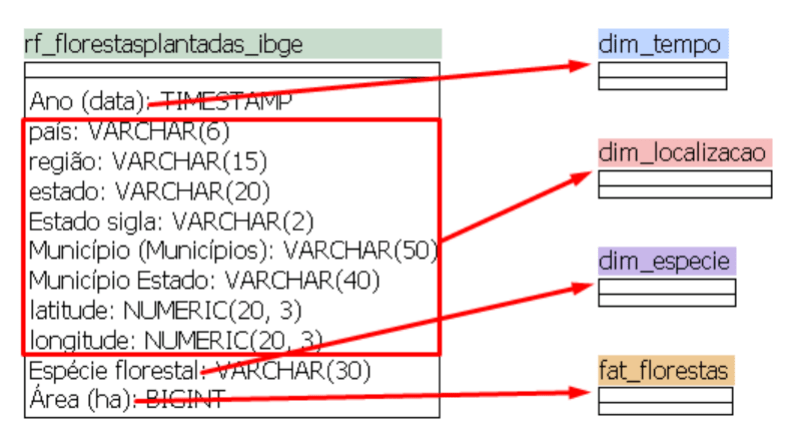
Sendo assim, podemos identificar 3 atributos, que são as dimensões: tempo, localização e espécie. E apenas uma métrica, a área, que é a fato florestas. Vamos ver em detalhes a modelagem de cada uma dessas tabelas que vão compor o nosso DW.
4.1. Modelagem das Dimensões
4.1.1. Dimensão de Tempo
O atributo de tempo, refere-se ao período de reflorestamento. Neste caso representado pelo campo Ano (data) e vamos modelar a dim_tempo da seguinte forma:
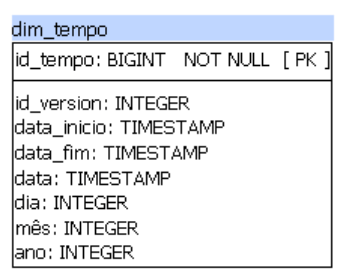
Para o problema que estamos tratando, só vamos poder fazer a agregação do reflorestamento por ano. Pois os nossos dados de origem só tem essa informação, apesar da nossa dimensão tempo ter mais algumas informações, não vão ser úteis para este caso. Esse é um problema muito comum, dados de origem insuficientes ou incompletos. Esse tipo de problemas com dados podem inviabilizar a solução, para o nosso caso só não vamos ter detalhes sobre o período de reflorestamento.
4.1.2. Dimensão de Localização
Em contrapartida, o atributo de localização, vamos ter detalhes desde o estado até a latitude e longitude do reflorestamento. Esse nível de detalhe pode ser necessário em alguns problemas ou não, isso vai depender do problema. Vamos a modelagem da dimensão localização:

Temos diversos campos na tabela de origem para a dim_localização. Mas o importante neste caso é identificar o campo chave para a dimensão, ou seja, o campo que identifica a dimensão de uma forma única. Então, vamos utilizar o campo municipio_uf, com ele garantimos o mapeamento de todas as localizações únicas na tabela de origem. Com essa dimensão vai ser possível saber qual estado teve a maior área reflorestada, por exemplo.
4.1.3. Dimensão de Espécie
O nosso último atributo é a espécie reflorestada. Vamos fazer a modelagem da dim_especie com o campo especie_florestal, vejamos:
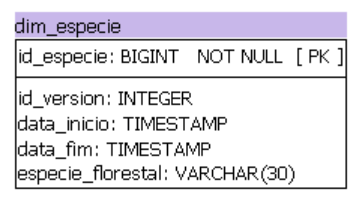
Com a modelagem das espécies de reflorestamento, podemos identificar qual o tamanho da área reflorestada de cada espécie dos dados.
É fundamental que a modelagem seja baseada de acordo com o escopo do projeto e a definição do problema. A grande possibilidade de resposta que os dados podem trazer é capaz de tirar o foco do problema e ao final do projeto não atingir o objetivo desejado.
Dimensões prontas, vamos modelar a nossa fato
4.2. Modelagem da Fato
A métrica da fato de reflorestamento indica a área de floresta que plantamos. Vamos ver a modelagem da fato:
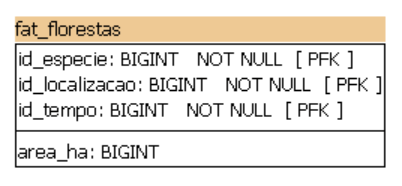
Modelamos a fato fat_florestas com a métrica area_ha e os ids das dimensões relacionadas. Desse modo, as dimensões vinculadas a fato nos permitem realizar todas as operações no cubo. O modelo de dados resultante vamos ver a seguir.
4.3. Resultado da Modelagem
Aqui podemos ver o resultado da modelagem de dados do problema do BI do Dados ao Cubo. Essa imagem representa a estrutura dos dados e o relacionamento entre as dimensões e a fato.
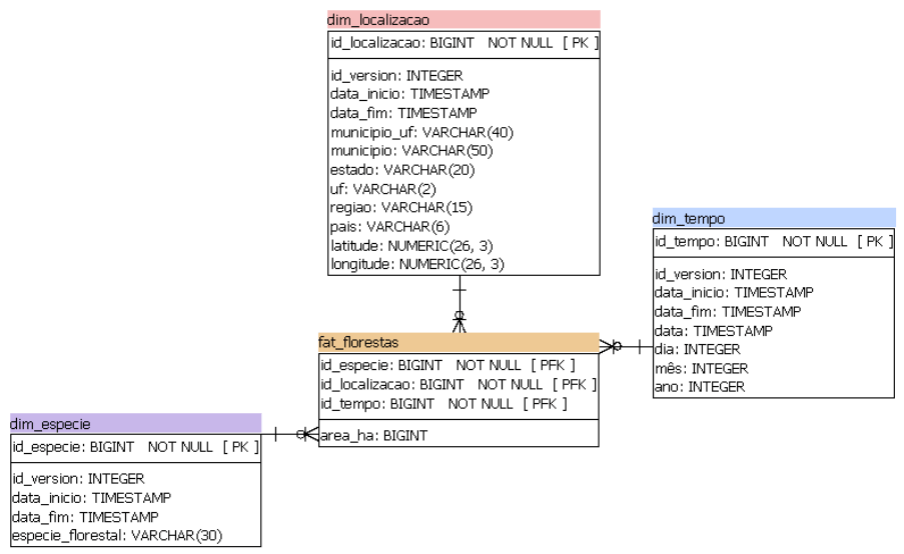
Portanto, aplicamos o modelo star schema, seguindo as boas práticas para projetos de BI. Esse modelo de dados multidimensional vai compor o DW.
Modelagem de Dados ao Cubo
Assim, concluímos mais uma etapa do Business Intelligence – Do Problema Ao Dashboard. Agora falta muito pouco para ver o resultado do projeto de BI do Dados ao Cubo. Na próxima etapa vamos ver como fazer o ETL com Pentaho para levar os dados do banco relacional para o DW. Em seguida finalizamos com o DataViz com o Power BI onde vamos apresentar o resultado final, construindo um dashboard com esses dados.
Espero que o conteúdo de BI do Dados ao Cubo esteja pelo menos dando uma iluminada nas ideias. Se está gostando do conteúdo, vamos levar para o maior número de pessoas possíveis que querem aprender BI. Um grande abraço e até a próxima.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Ingestão de Dados via API com Python
- Processamento Paralelo com Python
- Manipulando Dados em PostgreSQL com Python
- Velocidade da Internet com a Biblioteca SpeedTest Python
- Pipeline dos Projetos de Ciência de Dados
- Trabalhar com Arquivo de Texto em Python
- Análise de Dados com Scikit Learn Python
- Visualizar Dados do Snowflake no Metabase
Portanto, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀

3 Comments
Henrique
25 de fevereiro de 2021Gostei. Muito bem explicado com exemplos e uma linguagem clara.
Tiago Dias
8 de março de 2021Obrigado Henrique! O feedback, é importante para saber que estamos no caminho certo.