

Fala galera do mundo dos dados! Vou iniciar aqui no Dados ao Cubo a trilogia API com Python, o céu é o limite, apresentado como realizar a ingestão de dados via API com Python. No próximo artigo irei trazer para vocês, como realizar o processamento paralelo em Python utilizando também consumindo API com Python para obter os dados. E para fechar a trilogia persistiremos os dados que foram consumidos de uma API em um banco de dados relacional, o PostgreSQL, também utilizando o Python.
Primeiramente, vamos entender o que é uma API, conhecer a biblioteca Requests que irá nos ajudar a consumir dados da API com Python. Para tal utilizaremos uma API pública da Câmara de Deputados, que tem a proposta de transparência e disponibiliza informações relacionadas aos agentes públicos. E para finalizar, veremos na prática com o Python o processo de ingestão de dados, estruturação dos dados utilizando a biblioteca Pandas, além disso, faremos uma breve análise exibindo alguns gráficos com auxílio das bibliotecas Matplotlib e Seaborn. Chega de conversa e vamos consumir API com Python ao Cubo.
O que é API?
A API é uma forma de compartilhamento de dados entre plataformas distintas. Com rotinas e padrões definidos, é possível realizar a comunicação e a troca de informações, como podemos ver na definição que temos na Wikipédia:
“Interface de Programação de Aplicação, cuja sigla API provém do Inglês Application Programming Interface, é um conjunto de rotinas e padrões estabelecidos por um software para a utilização das suas funcionalidades por aplicativos que não pretendem envolver-se em detalhes da implementação do software, mas apenas usar seus serviços.”
Dessa forma, conseguimos trabalhar com dados externos à empresa ou apenas integração entre plataformas distintas. Trabalhar com APIs facilita e muito a vida na área de dados, então, é importante saber pelo menos o básico para consumir esses dados das mais diversas fontes existentes. Vamos conhecer a biblioteca Python que pode nos auxiliar nessa tarefa.
A Biblioteca Requests

A Requests é uma biblioteca de requisições HTTP para Python simples e elegante, como está descrito na própria documentação. Com ela é possível realizar diversos tipos de requisições HTTP: POST, GET, PUT, DELETE, HEAD e OPTIONS, todos de maneira bem simples, que é a principal proposta da biblioteca.
A sua instalação também é simples igual qualquer outra biblioteca em Python e pode ser realizada com o código abaixo:
pip install requests
Agora que já sabemos o que é uma API e qual ferramenta em Python utilizaremos, precisamos de uma fonte de informação.
Os Dados Abertos da Câmara dos Deputados

A proposta dos dados legislativos abertos é levar transparência das informações da Câmara de Deputados para todos. Na imagem abaixo podemos visualizar todas as coleções de dados disponíveis, com elas é possível consultar informações de deputados e partidos, verificar a atuação e os gastos do deputado, descobrir os eventos realizados pelas comissões, e muito mais!

A API dos dados abertos pode entregar dados puros em formatos JSON, justamente o que utilizaremos aqui na parte prática.
Consumir Dados de uma API com o Dados ao Cubo
Como dizia Albert Einstein!
“Na teoria, teoria e prática são a mesma coisa. Na prática, eles não são.”
Então, vamos apresentar na prática o passo a passo como utilizar a biblioteca Request, para consumir dados da API com Python. Primeiro, importaremos as bibliotecas necessárias para o desenvolvimento do nosso código Python.
import requests import json import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from wordcloud import WordCloud
As bibliotecas requests e json vão auxiliar na extração dos dados da API. O pacote pandas vai realizar a estruturação de dados. Por fim, as últimas, seaborn, matplotlib e wordcloud vão auxiliar na parte gráfica na análise dos dados.
Requisição de Dados da API com Python
Vamos iniciar realizando a requisição dos dados na API. Para isso Utilizaremos a função request do pacote requests, passando o método (GET), a url (https://dadosabertos.camara.leg.br/api/v2/deputados) e os parâmetros (logo em seguida veremos um exemplo, vamos deixar vazio neste momento). Com o resultado da requisição utilizaremos a função loads da biblioteca json. Assim conseguimos obter os dados em um formato de dicionário. Todos os detalhes no código abaixo.
# Requisição dos dados dos Deputados
url = 'https://dadosabertos.camara.leg.br/api/v2/deputados'
parametros = {}
resposta = requests.request("GET", url, params=parametros)
objetos = json.loads(resposta.text)
dados = objetos['dados']Os parâmetros, que deixamos vazio acima, tem a função de filtro na requisição de uma API. Dessa forma é possível fazer extrações conforme a necessidade. faremos uma requisição passando como parâmetro o id de um deputado.
# Requisição dos dados dos Deputados utilizando parametros
url = 'https://dadosabertos.camara.leg.br/api/v2/deputados'
parametros = {'id': 204554}
resposta = requests.request("GET", url, params=parametros)
objetos = json.loads(resposta.text)
dados_parametros = objetos['dados']Assim é possível fazer a extração na API conforme os parâmetros informados. Apenas informando a variável “dados_parametros” podemos verificar os dados retornados na requisição.
dados_parametros
Então, temos o seguinte resultado como retorno da API, de acordo com o parâmetro informado. Começamos a consumir os dados API dos deputados com Python.

Agora que temos um dicionário com todos os dados da API precisamos estruturar.
Estruturando Dados da API com Pandas
Para esta etapa de estruturação, utilizaremos a função DataFrame do pandas. A função head vai ser utilizada apenas para exibir os primeiros resultados. Observe como de maneira simples fazemos a operação com o código abaixo.
df = pd.DataFrame(dados) df.head()
E assim, os dados são exibidos, muito mais apresentável do que no formato de dicionário.

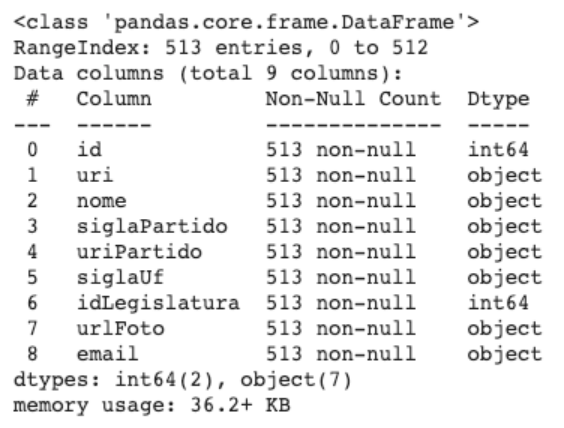
Com a função info, podemos dar uma conferida geral dos dados que temos.
df.info()
Temos algumas informações importantes, como as colunas do data frame, o tipo dos dados, a quantidade total de registro, os registros não nulos de cada coluna entre outras informações.
Para finalizar, faremos uma breve análise dos dados extraídos com Python da API dos deputados federais.
Analisando os Dados da API com Python
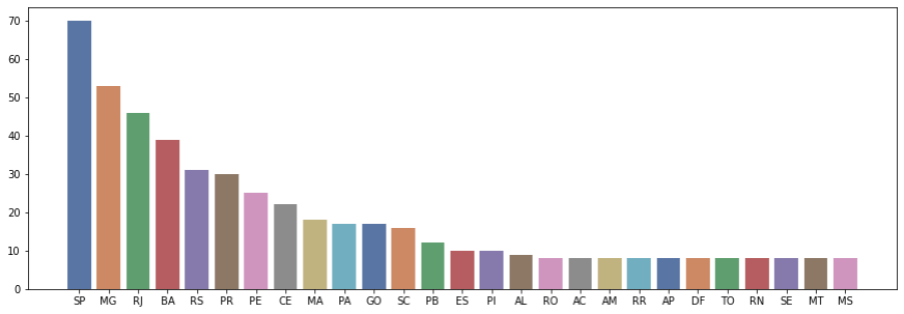
Uma informação importante é a quantidade de deputados pela UF. Aqui usaremos a função figure do matplotlib para ajustar o tamanho do gráfico. A função barplot do seaborn para gerar um gráfico de barras. E a função plot do matplotlib para exibir o gráfico gerado.
# Análise da quantidade de deputados pela UF x = df['siglaUf'].value_counts().index y = df['siglaUf'].value_counts().values plt.figure(figsize = (15, 5)) sns.barplot(x=x, y=y, palette="deep") plt.plot()
Podemos ver de forma bem clara a distribuição da quantidade de deputados pela UF, e a representatividade de cada Estado na casa.
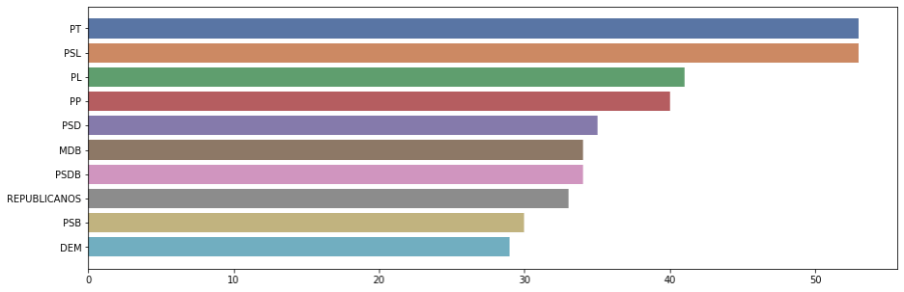
Dessa vez, uma outra informação relevante, que é a quantidade de deputados por partido. Utilizaremos as mesmas funções acima, as diferenças foram a inversão do eixo x e y do gráficos e a quantidade de colunas do gráfico, limitado ao TOP10. Por ter siglas grandes, a exibição na vertical facilita a leitura e a exibição da legenda.
# Análise da quantidade de deputados por Partido x = df['siglaPartido'].value_counts().head(10).values y = df['siglaPartido'].value_counts().head(10).index plt.figure(figsize = (15, 5)) sns.barplot(x=x, y=y, palette="deep") plt.plot()
Aqui podemos ver o TOP10 que representa os brasileiros na câmara de deputados. Um outro ponto são as legendas com maior poder de influência da casa.
Para concluir a nossa breve análise, aqui tem uma coisa curiosa. Quais são os nomes e/ou sobrenomes mais presentes dos deputados federais? Para isso utilizaremos a função WordCloud da biblioteca wordcloud. A variável todos_itens vai conter o nome completo de todos os deputados com a ajuda da função join. A função generate do wordcloud vai realizar essa contagem por palavra. Do matplotlib a função subplots cria o gráfico e a imshow exibe a wordcloud.
# Análise de nomes de deputados mais comuns
todos_itens = ' '.join(s for s in df['nome'].values)
stop_words = ['de','da']
# criar uma wordcloud
wc = WordCloud(stopwords=stop_words,
background_color="black",
width=1600, height=800)
wordcloud = wc.generate(todos_itens)
# plotar wordcloud
fig, ax = plt.subplots(figsize=(10,6))
ax.imshow(wordcloud, interpolation='bilinear')
ax.set_axis_off()Dessa forma, temos a nuvem de palavra abaixo:

Essa é uma visualização muito interessante, que pode trazer muitos insights. Um fato que já sabemos e é comprovado mais uma vez é a baixa representatividade feminina entre os deputados.
A análise dos dados é extremamente importante, e conta sempre com a criatividade do analista. É preciso sair do tradicional para trazer vários pontos de vista sobre os dados.
API com Python ao Cubo
Então, chegamos ao objetivo desta primeira etapa de realizar a Ingestão de Dados via API com Python. Esta é uma forma muito comum de consumo de dados atualmente, é de extrema importância para quem trabalha com dados. Vimos como o Python e seus milhares de pacotes auxiliam e muito nessa jornada de consumir dados de uma API.
Sendo assim, encerramos o nosso primeiro passo para mostrar que API com Python, o céu é o limite. O código completo você pode conferir no GitHub do Dados ao Cubo. Na sequência veremos como trabalhar com requisições em paralelo em uma API com Python. E para fechar persistiremos esses dados em um banco relacional.
Portanto, espero que o conteúdo seja útil para você, se gostou compartilhe o conteúdo do Dados ao Cubo, vamos fortalecer as comunidades de dados aqui no Brasil. Então não esqueça de compartilhar seu feedback conosco, um grande abraço e até a próxima.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- NLP com scikit-learn
- Classificação com scikit-learn
- Agrupamento com scikit-learn
- Previsão de Séries Temporais com SKTime
- Sistemas de Recomendações com Surprise
- Regressão com scikit-learn
- Análise de Dados com Pandas Python
- Visualizar Dados do PostgreSQL no Metabase
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀

2 Comments
Vitor Ravel
7 de abril de 2023Oi, Tiago. Tudo certo? Acabei de terminar o artigo e achei ótimo, mesmo eu que tenho conhecimentos bem básicos de programação consegui entender, parabéns pela didática! Você sabe se existe também alguma forma de importar dados para essas ferramentas do governo? Exemplo: para prestação de contas de um projeto cultural, é necessário enviar relatórios, fotos, recibos fiscais, tudo em PDF ou em alguns casos precisa preencher informações em campos. Você acha que existe alguma forma de importar esses dados via um aplicativo/API de terceiros tendo os dados de login do usuário? Abraço!
Tiago Dias
13 de abril de 2023Fala Vitor! Quem bom que gostou. Formas de enviar dados para API tem sim, mas é preciso ver a documentação de cada uma para construir uma solução adequada.