

Tic toc tic toc! Uma série temporal é uma coleção de observações feitas sequencialmente ao longo do tempo. Exemplos de séries temporais são: a temperatura de uma cidade ao longo do ano, o número de crianças nascidas por mês em um país, o valor de uma ação na bolsa de valores ao longo de um dia, mês, ano…. E por aí vai.
Ao mesmo tempo, não são séries temporais: um conjunto de temperaturas de várias cidades, o número de crianças nascidos em um país, em diferentes regiões… etc… Podemos observar então que apesar dos problemas de regressão e previsão (forecasting) parecerem ser semelhantes, na realidade não são, pois enquanto a regressão faz uma previsão baseada em diversos dados associados a uma saída contínua, a tarefa de previsão de séries temporais faz uma previsão dos próximos valores dessa coleção de valores sequenciais ao longo do tempo.
Para ajudar no entendimento de séries temporais vamos utilizar a biblioteca sktime, uma ferramenta importante a auxiliar na análise das séries temporais. Vamos ver em mais detalhes a biblioteca mais a seguir.
Componentes de uma série temporal
Uma série temporal pode ser dividida em: tendência, sazonalidade e resíduo. Vejamos como exemplo a série airline da biblioteca sktime:
from sktime.datasets import load_airline import seaborn as sns y = load_airline() sns.lineplot(data=y);
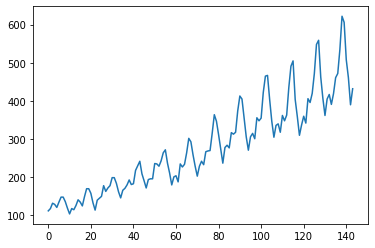
Podemos observar que essa série, apesar de ter quedas e subidas, tem uma tendência de alta. Caso pudéssemos observar uma maior queda ao longo do tempo, teríamos então uma tendência de baixa. Também podemos observar uma movimentação em ciclos, isso se chama sazonalidade, pois a cada N passos de tempo ela repete um movimento semelhante de subida e descida. Por fim, há um elemento que não podemos prever, ele se chama resíduo ou ruído.
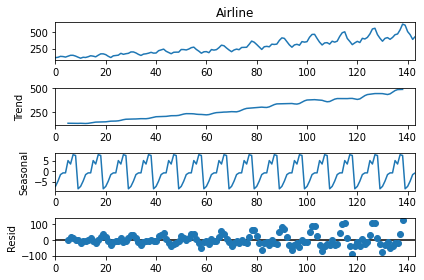
Vamos utilizar a função seasonal_decompose da biblioteca stats models para dividir essa série nesses três elementos: Tendência (trend), sazonalidade (seasonal) e resíduo (resid).
from statsmodels.tsa.seasonal import seasonal_decompose res = seasonal_decompose(y, period=10) res.plot();
Séries Temporais com Sktime

Vamos tentar agora prever valores futuros utilizando a sktime. A sktime é uma biblioteca baseada na scikit learn (por isso o nome), que auxilia nas tarefas de previsão, regressão e classificação de séries temporais (e futuramente prometem clusterização). Ela fornece diversos algoritmos estatísticos de de aprendizado de máquina para essas tarefas.
Para todos os exemplos, vamos usar a função de perda SMAPE (Symmetric mean absolute percentage error), definido abaixo. Essa função é muito utilizado no escopo de séries temporais.
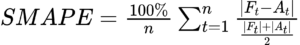
O primeiro modelo que vamos utilizar é o Naive (ingênuo). Ele vai ser nosso baseline para analisar a qualidade da solução. Um baseline significa uma solução de base, para se basear, ou seja, que qualquer algoritmo que performe pior do que ele não é interessante para ser utilizado.
O método Naive do sktime pode utilizar 3 estratégias: last, o último valor válido; seasonal_last, último valor de acordo com a sazonalidade; e mean, a média entre os valores de uma janela de tempo. Utilizamos o seasonal_last e podemos observar um erro de 0.14 aproximadamente.
from sktime.forecasting.naive import NaiveForecaster from sktime.forecasting.model_selection import temporal_train_test_split from sktime.performance_metrics.forecasting import smape_loss y_train, y_test = temporal_train_test_split(y) fh = np.arange(1, len(y_test) + 1) forecaster = NaiveForecaster(strategy='seasonal_last', sp=12) forecaster.fit(y_train) y_pred_naive = forecaster.predict(fh) smape_loss(y_test, y_pred_naive) # 0.145427686270316
Para demonstrar a versatilidade do sktime, no próximo exemplo vou utilizar um regressor da biblioteca XGBoost para efetuar a previsão. Faz-se isso através da classe ReducedRegressionForecaster.
from sktime.forecasting.compose import ReducedRegressionForecaster from xgboost import XGBRegressor from sktime.forecasting.model_selection import temporal_train_test_split from sktime.performance_metrics.forecasting import smape_loss y_train, y_test = temporal_train_test_split(y) fh = np.arange(1, len(y_test) + 1) forecaster = ThetaForecaster(sp=12) forecaster.fit(y_train) y_pred = forecaster.predict(fh) smape_loss(y_test, y_pred) #0.08661469103230263
O erro deu aproximadamente 0.08. Bem melhor, né? Agora vamos plotar o resultado das duas previsões e o real para verificar se esse resultado condiz com a realidade mesmo…
from sktime.utils.plotting.forecasting import plot_ys
plot_ys(y_train, y_test, y_pred, y_pred_naive,
labels=["y_train", "y_test", "y_pred", "y_pred_naive"])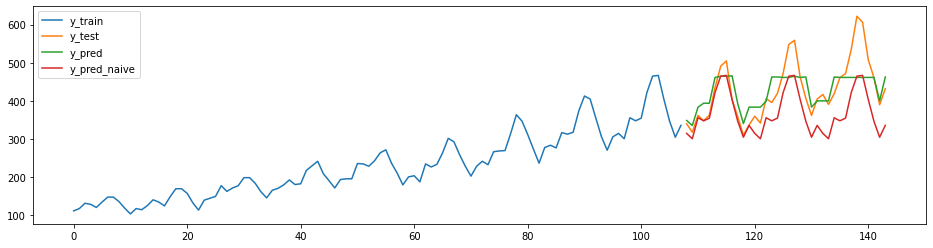
Como vocês podem notar, enquanto o método naive replicou a forma da série mas errou os valores, o método XGBoost chegou mais perto dos valores mas ainda está bem distante da realidade. Para obter melhores resultados, é necessário afinar os hiperparâmetros (hyperparameter tuning). Em breve faremos uma postagem sobre isso!
Séries Temporais ao Cubo
Portanto, a biblioteca sktime é bastante promissora para a parte de séries temporais, ela provém uma interface bem tranquila de usar para as tarefas de classificação, regressão e previsão dessas séries. Dessa forma, comparada a outras bibliotecas que podem ser utilizadas para essa tarefa, como a Prophet e o próprio Keras, a sktime tem uma melhor curva de aprendizagem e é bastante versátil.
Finalizando, para mais técnicas de forecasting utilizando o sktime acesse Examples Forecasting.
Referências sobre Séries Temporais
- Série Temporal
- Hands-on Machine Learning for Algorithm Trading
- Sktime
- Unmasking the Theta method
- Symmetric mean absolute percentage error
- Forecasting With Sktime
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Inteligência Artificial em Ressonância Magnética
- Ciência de Dados para Mercado de Ações Parte I
- Profissão: Cientista de Dados Parte I
- Profissão: Cientista de Dados Parte II
- Álgebra Linear com NumPy
- Condicionais em Python
- Polars vs. Pandas: Explorando as principais funções para análise de dados
- Descubra Como Utilizar o DBSCAN em Python para Análise de Dados
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Programador e cozinheiro. Formado pela Universidade Federal do Piauí e com um mestrado (interrompido) pela UFRGS. Com uma grande sede de conhecimento, está sempre se perguntando os porquês e tentando dar o melhor naquilo que faz. Desde pequeno diz que vai ser cientista, seja da computação, de dados ou na cozinha. O conhecimento é a única esperança.
“Um homem não é outra coisa senão o que faz de si mesmo.” Sartre
