

Fala galera do mundo dos dados! Como prometido, a parte II do post (Profissão: Cientista de Dados Parte I). Então, falamos um pouco da importância domínio do negócio e da matemática para a ciência de dados, agora falaremos um pouco do envolvimento da computação, que também pode se dividir em três partes que formam uma só: a programação, o aprendizado de máquina e os bancos de dados.
Programação na profissão cientista de dados
Primeiramente, programação é o ato de escrever um código em uma linguagem sintética, chamada linguagem de programação. Em Ciência de Dados são utilizadas algumas linguagens que possuem ferramentas adequadas para as tarefas de um cientista de dados, sendo as principais Python e R, mas também são utilizadas as linguagens Scala e Julia.
“Joãozinho desde a exploração dos dados da planilha em excel dos dados de pedidos de dona Ana está utilizando a linguagem python para visualizar esses dados, com o python é possível ler os dados na planilha com pandas, gerar gráficos (com matplotlib, seaborn, bokeh, plotly ou altair) e até criar programas completos para a fábrica de salgados (desktop, web ou mobile).”
Machine Learning (Aprendizagem de máquina) para ciência de dados
São técnicas que utilizam alguma heurística, como por exemplo as redes neurais que utilizam o funcionamento do cérebro como metáfora, ou método matemático a fim de reconhecer padrões e gerar valor ao negócio.
“Joãozinho como um bom cientista de dados que é, uma das suas soluções foi apresentar para dona Ana a classificação dos clientes em categorias (ouro, prata e bronze) utilizando os dados de pedidos de clientes, bom demais esse Joãozinho hein? Para isso, ele usou algoritmos de aprendizagem de máquina implementados na biblioteca Scikit-Learn, para os mais íntimos, sklearn. Nesse caso ele fez uma clusterização (agrupamento), agrupando os clientes mais parecidos entre si e rotulando esses grupos de clientes.”
SQL (Structured Query Language) e NoSQL na profissão cientista de dados
SQL é uma linguagem de consulta em banco de dados relacionais (forma de armazenamento de tabelas com relacionamentos entre si) são os bancos de dados mais tradicionais (MySQL, PostgreSQL, entre outros). Já o NoSQL é um termo que representa os bancos de dados não relacionais, forma de armazenamento otimizado e específicos para o tipo de dados que está sendo armazenado, sem as tabelas tradicionais e sem a necessidade de relacionamentos formais (MongoDB, Cassandra, entre outros).
“Lembra lá em cima quando falei que nosso cientista Joãozinho pegou os dados da fábrica de salgados em uma planilha de Excel? Pois Joãozinho migrou esses dados para um banco de dados relacional, e para serem manipulados ele vai utilizar uma linguagem SQL. Assim eles ficam mais organizados e o sistema fica mais robusto para realizar cadastros, alterações, buscas e remoções (o famoso CRUD – Create, Read, Update, Delete).”
Sistemas de recomendação para ciência de dados
Nada mais é que um conjunto de técnicas computacionais que, conforme o contexto que os clientes estão inseridos e os interesses dos mesmos, são recomendados itens personalizados de forma muito mais assertiva. Os principais tipos de sistema de recomendação são os baseados em conteúdo (content based), filtragem colaborativa (colaborative filtering) e hibridos.
“Mais uma solução de Joãozinho para dona Ana, que sempre reclama que a maioria dos clientes nunca variam os pedidos. Então ele criou um sistema de recomendação que indica quando e qual o salgado o cliente vai querer antes mesmo dele pedir. Proporcionando sugestões mais assertivas para dona Ana. Ôô Joãozinho arretado!”
Processamento de linguagem natural para ciência de dados
É a subárea que trata da geração e compreensão das linguagens humanas naturais. É preciso tratar os dados, removendo stop words (palavras que não acrescentam muito à compreensão). Corrigindo alguns erros de digitação, usando stemming e lemmatization (deixar apenas o radical das palavras) e tokenizando (separar as palavras e transformar em números). Mas cada um desses passos depende de cada problema.
“O site Dona Ana Salgados está recebendo muitos acessos, e muita gente está preferindo comprar pelo site, mas sente falta do afeto de dona Ana ao telefone. Joãozinho então criou um chatbot treinado com conversas da dona Ana para trazer mais humanização aos pedidos.”

Processamento de imagens para ciência de dados
É a subárea que cuida do melhoramento e extração de informações de imagens digitais. Hoje em dia popularizou-se utilizar deep learning nessa tarefa, com o algoritmo de Redes Neurais Convolucionais (CNN – Convolucional Neural Networks). Também usa-se muita transferência de aprendizado (transfer learning), onde uma rede pré-treinada em bases extensas é usada para melhorar a solução.
“Dona Ana criou uma promoção no instagram para promover sua nova página na rede social. Mas foram tantas postagens que ela não tinha tempo de analisar se cada um realmente estava comendo um salgado dona Ana mostrando o logo da loja (exigência da promoção) na foto. Então ela liga pra quem? Joãozinho é claro. Ele então teve uma idéia de criar uma CNN que fizesse uma segmentação da imagem e identificasse um salgado e o logo da loja na foto do instagram.”
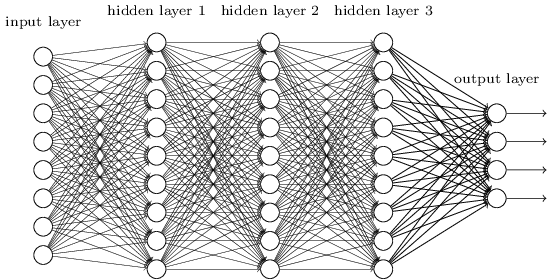
Deep Learning(Aprendizagem profunda) para ciência de dados
É um ramo do aprendizado de máquina que utiliza redes neurais profundas para capturar padrões nos dados e conseguir uma melhor qualidade nos resultados. A figura acima mostra uma rede neural profunda, com uma camada de entrada, 3 camadas ocultas e uma camada de saída.
“Joãozinho se matou de estudar, mas agora ele tem domínio dos algoritmos de deep learning. Ele conseguiu implementar o processamento de linguagem natural e processamento de imagens utilizando redes neurais profundas! Melhorando e muito a performance dos modelos criados por ele anteriormente”.
Big Data e Cloud Computing(Computação em nuvem) na profissão cientista de dados
Como último tópico, vamos falar de Big Data e Cloud Computing. Big data é a área que cuida do tratamento, análise e obtenção de informações de grandes volumes de dados. Cloud Computing é a disponibilidade sob demanda de recursos do sistema de computador, nada mais é que, você acessar remotamente os recursos (programas, dados e serviços) por meio da internet, utilizando a computação como serviço ao invés de produto.
“As vendas de dona Ana bombaram! Depois de abrir várias franquias, ela chamou novamente nosso cientista de dados Joãozinho para um novo desafio: tratar os dados de todas as lojas e unificar o acesso. Joãozinho logo percebeu que o computador do escritório da matriz não ia dar conta e contratou um serviço em nuvem para lidar com essa quantidade de dados muito grande que as franquias da dona Ana estão gerando, além de colocar o Sistema de Recomendação, o chatbot e a CNN (já criados por ele mesmo anteriormente) também na nuvem, após uma pesquisa sobre as vantagens dos principais serviços em nuvem hoje (AWS, Azure ou Google Cloud), Joãozinho optou por hospedar tudo na AWS devido o presidente da Amazon ser o homem mais rico do mundo.”
Profissão cientista de dados ao Cubo
Finalizando galera, “basicamente” é isso o que precisa-se estudar pra ter o conhecimento suficiente e se tornar um UNICÓRNIO na ciência de dados. Portanto, na próxima postagem iremos falar do Pipeline (as etapas básicas) para projetos de Ciência de dados. Então não percam!
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Análise de Dados para Detecção de Fraude
- Métodos de Classificação para Classes Desbalanceadas
- Análise de Dados: Detecção de Fraude de Cartão de Crédito
- Compreendendo Agile BI – Parte I
- Agile BI na Prática – Parte II
- Conceitos Iniciais do Python
- Bases de Dados Gratuitas para Impulsionar suas Análises de Dados
- Geração de Relatórios em PDF com Python
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Tudo sobre o universo Data Science!
