
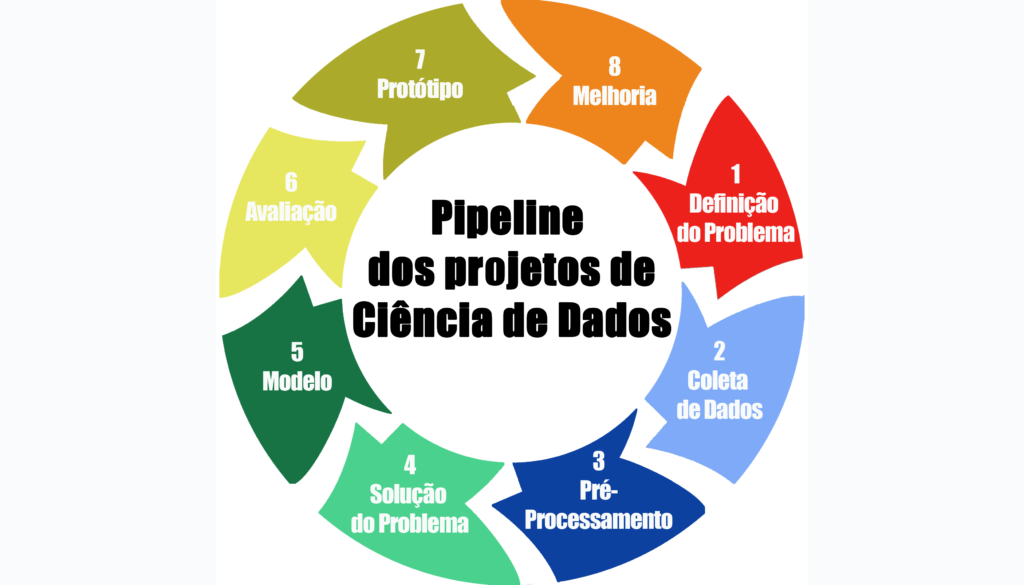
Fala galera do mundo dos dados! O nosso tema de hoje é o pipeline dos projetos de Ciência de Dados. Assunto tão relevante que é necessário uma atenção especial antes de começarmos qualquer projeto de Ciência de Dados. Sendo assim, quando iniciamos um novo projeto, algumas etapas básicas são essenciais para atingir o êxito na solução do problema. E algumas dessas etapas muitas vezes são ignoradas, mesmo sendo cruciais para a entrega de um projeto bem elaborado.
Vamos passar pelas 8 etapas básicas para projetos de Ciência de Dados. Mas saibam que não é uma receita de bolo, cada projeto tem suas peculiaridades e particularidades que devem ser levadas em conta na construção de um fluxo do processo. Essas não são as únicas etapas e nem devem ser seguidas à risca em cada projeto de Ciência de Dados, mostraremos aqui apenas uma das diversas possibilidades. Lembrem-se cada problema é único, então é necessário adequar-se às peculiaridades de cada caso.
Os projetos de Ciência de Dados são processos contínuos, por isso as etapas estão representadas em uma imagem circular, e vocês deve retornar a cada uma das etapas quantas vezes forem necessário. Vamos ver agora os detalhes de cada etapa.
1 – Definição do Problema

Todos precisam ter uma compreensão clara de qual é o problema que precisamos resolver. Devemos avaliar se é realmente um problema e se existe demanda para a solução que vamos criar.
Essa etapa desempenha um papel crucial nos projetos de ciência de dados. Cada passo tem sua importância, mas se não definirmos bem o problema, não adiantará seguir em frente.
2 – Coleta de Dados

Na coleta de dados precisamos levantar todas as fontes de dados que temos (ou que vamos precisar ter) para resolver o problema, essa coleta pode ser de diversas fontes, desde um dado público (dados do IBGE) até uma planilha em excel.
Os dados coletados precisam ser relevantes para a solução do problema, por isso nosso problema deve estar bem definido para saber o que precisamos para encontrar as possíveis respostas para ele.
3 – Pré-Processamento

O pré-processamento é um etapa onde precisamos trabalhar os dados para que os mesmos fiquem de forma a atender as necessidades dos modelos que vamos aplicar, deixá-los em um formato mais coerente, tratar os dados faltantes (missing), trabalhar  os valores discrepantes (outliers). Para isso, vamos utilizar técnicas de Feature Engineering (Engenharia de atributos) e Feature Selection (Seleção de atributos) para pré-processar nossos dados. Buscamos sempre alcançar os melhores resultados.
os valores discrepantes (outliers). Para isso, vamos utilizar técnicas de Feature Engineering (Engenharia de atributos) e Feature Selection (Seleção de atributos) para pré-processar nossos dados. Buscamos sempre alcançar os melhores resultados.
Até chegarmos aqui e sairmos com esses dados preparados para as próximas etapas, estimamos que gastamos 80% de todo o projeto nessas etapas. Sendo que a maior parte desse percentual está nessa parte específica. O pré-processamento é uma das etapas mais trabalhosas e importantes no projeto de Ciência de Dados.
4 – Solução do Problema

Para chegar a solução do problema (na verdade, é uma hipótese), que será validada ou não, já percorremos um longo caminho. Já aplicamos um modelo e realizamos uma avaliação, então conhecemos bastante dos dados que estamos trabalhando. Chegou então a hora fazer esses dados falarem!
Devemos realizar uma exploração dos dados com técnicas de Matemática e Estatística aliadas a linguagens de programação (atualmente, as linguagens mais comuns em Ciência de Dados são Python, R, Scala e Julia), a fim de saber ainda mais sobre esses dados e as possibilidades que podemos encontrar neles.
Então com todas as ferramentas a disposição do cientista de dados, ele vai escolher as melhores técnicas para aplicar sobre esses dados. Podendo para rejeitar ou não as hipóteses levantadas.
5 – Modelo

Um modelo é uma função que vai melhor descrever os dados que você tem.  Chegando nesta etapa, existem uma infinidade de modelos possíveis de aplicar, vai depender do problema e as informações que possuímos para resolvê-lo.
Chegando nesta etapa, existem uma infinidade de modelos possíveis de aplicar, vai depender do problema e as informações que possuímos para resolvê-lo.
É necessário que esteja bem claro com que tipo de problema estamos lidando, se é uma regressão, uma classificação ou outro tipo, se os dados estão rotulados ou não, pois de acordo com cada detalhe desse, o cientista de dados vai apontar o melhor ou os melhores modelos para começar.
6 – Avaliação

Avaliar projetos de ciência de dados quantifica a qualidade de uma solução. Essa etapa é bem subjetiva, pois a forma de avaliar varia muito de acordo com o problema e com as métricas utilizadas, além do próprio cientista de dados.
7 – Protótipo

Após validar com sucesso a hipótese da solução do problema, podemos avançar para um protótipo da solução, que nada mais é que uma ideia funcional da solução final para o projeto.
Desde algum rascunhado no papel até um software funcional com as funcionalidades básicas da solução, o protótipo pode variar, dependendo da complexidade e do nível de exigência do projeto.
8 – Melhoria

As melhorias são fundamentais em qualquer tipo de projeto, desde o projeto pessoal até os projetos de ciência de dados. As melhoria deve ser contínua, seja do que já foi entregue e está funcionando ou melhorias a serem implementadas.
Projetos de Ciência de Dados ao Cubo
Bem, por hoje foi isso! Chegamos ao fim de mais uma postagem, esperamos que tenham gostado e aprendido algo com ela. Deixe seu feedback, ele é muito importante pra nós. Até a próxima!
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Inteligência Artificial em Ressonância Magnética
- Ciência de Dados para Mercado de Ações Parte I
- Profissão: Cientista de Dados Parte I
- Profissão: Cientista de Dados Parte II
- Álgebra Linear com NumPy
- Conceitos Iniciais do Python
- Bases de Dados Gratuitas para Impulsionar suas Análises de Dados
- Geração de Relatórios em PDF com Python
Encerro com um convite para que você seja um Parceiro de Publicação Dados ao Cubo e escreva o próximo artigo, compartilhando conhecimento com toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Tudo sobre o universo Data Science!

1 Comment
Silvio
11 de julho de 2020Excelente artigo sobre o ciclo de vida de um projeto de machine learning.
O primeiro passo, o entendimento do problema é vital pra que no final seja entregue algo que corresponda a expectativa do cliente e resolva o problema proposto.