

Fala Galera do mundo dos dados, hora de manipular dados no Cassandra com Python. Dessa forma, seguimos na missão de fazer uma introdução aos bancos de dados NoSQL com Python. O Cassandra, assim como outros bancos de dados NoSQL tem grande potencial para atender as soluções de Big Data. Portanto, é bem importante para os engenheiros e analistas de dados saber como funciona o Apache Cassandra.
Aqui você vai ver:
- O que é o banco de dados Apache Cassandra
- Qual biblioteca Python para manipular dados no Cassandra
- Como criar um banco de dados Cassandra com Docker
- Como fazer uma conexão do Python com Cassandra
- Como criar keyspaces e tabelas no Cassandra com Python
- Como inserir dados em uma tabela do Cassandra com o Python
- Como consultar dados de uma tabela no Cassandra com o Python
- Como inserir e consultar dados no Cassandra com Spark
- Conectar ao Cassandra com o SQLPad
Então, vamos ao que interessa! Partiu, conhecer um pouco mais do banco de dados Apache Cassandra.
Banco de Dados Cassandra

Apache Cassandra é um banco de dados distribuído altamente escalável, que reúne a arquitetura do DynamoDB, da Amazon Web Services e modelo de dados baseado no BigTable, do Google. O Cassandra inicialmente foi criado pelo Facebook, que abriu seu código-fonte para a comunidade em 2008. Agora é mantido por desenvolvedores da fundação Apache e colaboradores de muitas empresas.
A estrutura de dados do Cassandra é bem simples e de fácil entendimento, ele é estruturado em Keyspaces, onde cada espaço desse tem as suas tabelas e cada tabela tem a estrutura colunar. Na imagem abaixo você pode ver a representação gráfica desta estrutura de dados do Cassandra.
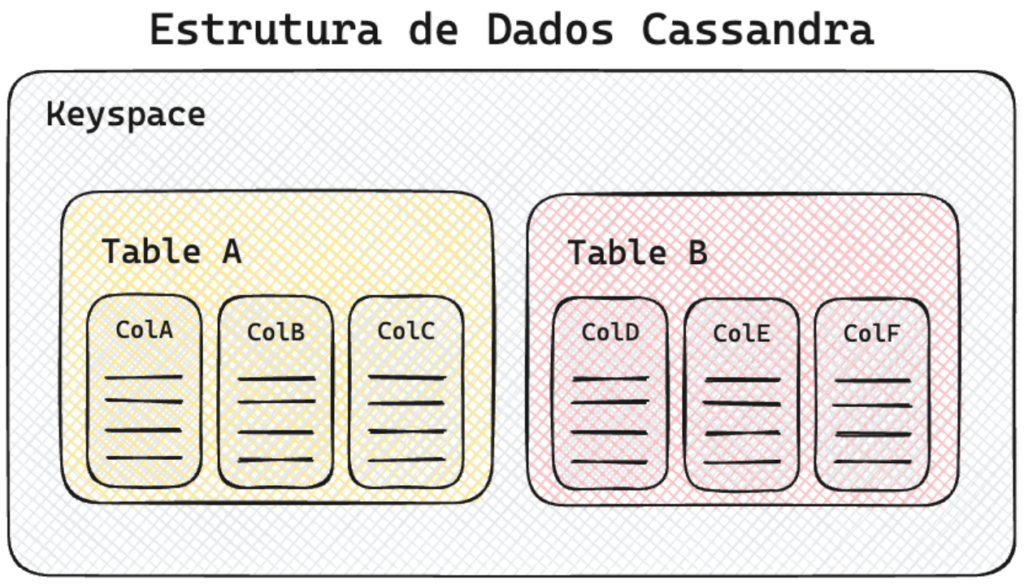
A forma de manipular tanto a estrutura quanto os dados, é através da linguagem CQL. Uma linguagem própria a Cassandra Query Language (CQL), é uma interface simples para acessar o Cassandra, como uma alternativa à tradicional SQL (Structured Query Language). Além da linguagem CQL, precisaremos de uma biblioteca para trabalhar com Cassandra no Python.
A Biblioteca Cassandra
A lib cassandra-driver é uma biblioteca cliente Python moderna, rica em recursos e altamente ajustável para Apache Cassandra, ela é bem simples e bastante funcional. Para a instalação da biblioteca, utilizamos o comando abaixo.
pip install cassandra-driver
Agora é hora de manipular dados no Cassandra com Python no Dados ao Cubo!
Manipulando Dados no Cassandra com o Dados ao Cubo
Com a lib cassandra-driver instalada acima configuramos o nosso ambiente Python para trabalhar com Cassandra. Mas, se você ainda não tem um banco de dados Cassandra para conectar, faremos a configuração de um banco Cassandra com docker para os nossos estudos.
Criando Banco Cassandra com Docker
Aqui, precisaremos do docker para instalação do Cassandra. Se ainda não utiliza o docker, pode instalar seguindo a documentação oficial da plataforma. Com Docker instalado seguimos os três passos a seguir, primeiro baixamos a imagem do Docker, em seguida criamos uma Network e finalizamos com a execução da imagem do Cassandra.
### Baixando a imagem docker do Cassandra docker pull cassandra:latest
### Criar network docker network create dadosaocubo
### Cria container docker Cassandra docker run --rm -d --name cassandra -p 9042:9042 --hostname cassandra --network dadosaocubo cassandra
Com esses três passos já é possível conectar ao Cassandra com Python. Vale lembrar, que a criação do Network não é um passo obrigatório mas como utilizaremos outra ferramenta também no docker para conectar ao Cassandra, Esse passo é importante para essa comunicação entre duas imagens dentro do Docker. Seguimos agora para o código Python.
Bibliotecas para Manipular Cassandra com Python
Para trabalhar com o Cassandra no Python, precisaremos de algumas bibliotecas para serem importadas. Aqui separei em três blocos as bibliotecas, primeiro a biblioteca de comunicação do Cassandra com python, na sequência duas bibliotecas para consumir dados de uma API e por fim a biblioteca para trabalhar com Cassandra no PySpark.
# importa bibliotecas do cassandra from cassandra.cluster import Cluster from cassandra.auth import PlainTextAuthProvider # importa bibliotecas para consumir dados da API import requests import json # importa bibliotecas do spark from pyspark.sql import SparkSession, functions as f
Com todas as bibliotecas importadas podemos começar a nossa aplicação Python com Cassandra.
Conexão do Python com o Cassandra
Primeiramente, faremos conexão no Cassandra com o Python. Aqui usamos a função PlainTextAuthProvider responsável pela autenticação com usuário e senha, depois a função Cluster com o endereço do Cassandra. finalizando com o método connect, que irá realizar a conexão do Python com Cassandra.
# conexão do python com o cassandra auth_provider = PlainTextAuthProvider(username='cassandra', password='cassandra') cluster = Cluster(['localhost'], auth_provider=auth_provider) session = cluster.connect()
Com a comunicação estabelecida, podemos seguir para a criação da estrutura do banco Cassandra. Agora, todos os comandos no Cassandra através do Python será através da variável session com o método execute.
Criando Keyspace no Cassandra com Python
O Cassandra, trabalha com conceito de Keyspaces, algo análogo a um database. Com comando Python abaixo, podemos listar todos os Keyspaces disponíveis no Cassandra.
# lista todos os keyspaces disponíveis
session.execute("DESCRIBE keyspaces").all()Caso Keyspace ainda não esteja criado, podemos criar um Keyspace no Cassandra utilizando Python. Confere o código a seguir para a criação de um Keyspace com o comando CREATE KEYSPACE.
# criar um novo keyspaces
session.execute("""
CREATE KEYSPACE ks_dadosaocubo
WITH REPLICATION = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};
""")Em algum momento, pode ser necessário consultar os detalhes de um Keyspace criado, para isso basta utilizar o comando a seguir, realizando um SELECT na tabela de configuração do Cassandra system_schema.keyspaces.
# lista detalhes dos keyspaces
session.execute("""
SELECT *
FROM system_schema.keyspaces
WHERE keyspace_name='ks_dadosaocubo'
""")Se precisar deletar o Keyspace no Cassandra, também conseguimos fazer utilizando o Python, Confere o código abaixo com o comando DROP KEYSPACE.
# deletar keyspaces
session.execute("""
DROP KEYSPACE IF EXISTS ks_dadosaocubo
""")Agora que já temos a estrutura do Keyspace construída, podemos criar as nossas tabelas dentro dele.
Criando Tabela no Cassandra com Python
Antes de criar uma tabela, iremos conferir como listar todas as tabelas disponíveis no Cassandra. Para isso utilizamos o comando Python a seguir.
# listar tabelas dos keyspaces
session.execute("DESCRIBE tables").all()Caso seja necessário listar as tabelas de apenas um Keyspace do Cassandra, o comando abaixo é uma alternativa.
# listar tabelas de um keyspace
session.execute("""
SELECT *
FROM system_schema.tables
WHERE keyspace_name='ks_dadosaocubo'
""")Mas, se precisar criar uma tabela no Cassandra com Python, utilizamos o CREATE TABLE.
# criar uma tabela no cassandra
session.execute("""
CREATE TABLE ks_dadosaocubo.tb_ncm (
codigo text,
descricao text,
data_inicio text,
data_fim text,
tipo_ato text,
numero_ato text,
ano_ato text,
PRIMARY KEY (codigo) );
""")
E para deletar uma tabela existente, também temos o comando DROP TABLE conforme o código a seguir.
# deletar tabelas
session.execute("""
DROP TABLE IF EXISTS ks_dadosaocubo.tb_ncm
""")Agora que já criamos a estrutura do banco Cassandra utilizando o Python, é hora de inserir os dados.
Inserindo Dados no Cassandra com Python
Para inserir dados no Cassandra utilizando Python, podemos fazer isso de diversas formas. primeiro veremos a forma mais tradicional e simples, utilizando o comando INSERT INTO.
# inserir dados em uma tabela
session.execute(
"""
INSERT INTO ks_dadosaocubo.tb_ncm (codigo, descricao, data_inicio, data_fim, tipo_ato, numero_ato, ano_ato)
VALUES (%s, %s, %s, %s, %s, %s, %s)
""",
("2021", "01", "9999-12-31", "2022-04-01", "Animais vivos.", "272", "Res Camex")
)Mas, para grandes volumes de dados essa talvez não seja a melhor solução. Então veremos como inserir dados no Cassandra com o PySpark.
Inserindo Dados no Cassandra com Spark
Iremos dividir esta etapa em 3 pedaços, primeiro a criação da sessão Spark, segundo o consumo de dados de uma APIe terceiro inserir os dados no banco com Spark.
Criar Sessão Spark
Para utilizar o Spark, inicialmente precisamos criar uma sessão através do código abaixo, se não sabe nada sobre Spark, leia o artigo aqui do Dados ao Cubo sobre como preparar ambiente PySpark com exemplos. Um detalhe importante a ser ressaltado são os pacotes do Cassandra que passamos na configuração do Spark.
# criar sessão spark
spark = (SparkSession.builder\
.config("spark.jars.packages", "com.datastax.cassandra:cassandra-driver-core:2.1.1,com.datastax.spark:spark-cassandra-connector_2.12:3.4.1")\
.config("spark.sql.extensions", "com.datastax.spark.connector.CassandraSparkExtensions")\
.getOrCreate() )Consumir dados de uma API
Agora é hora de conseguir uma base de dados digna para inserir os dados no Cassandra. Dessa forma, iremos consumir os dados de uma API com informações de NCM (Nomenclatura Comum do Mercosul).
Abro um parênteses, para destacar a qualidade da origem dos dados do projeto Brasil API. Um projeto experimental, que tem como objetivo centralizar e disponibilizar endpoints modernos com baixíssima latência independente de sua fonte para transformar o Brasil em uma API.
O código a seguir, para requisição em um API e retornará o resultado da variável objeto. Se quiser saber um pouco mais de como trabalhar com API e Python Confere o artigo ingestão de dados via API com Python.
# consumindo dados de uma API
url = f'https://brasilapi.com.br/api/ncm/v1'
resposta = requests.request("GET", url)
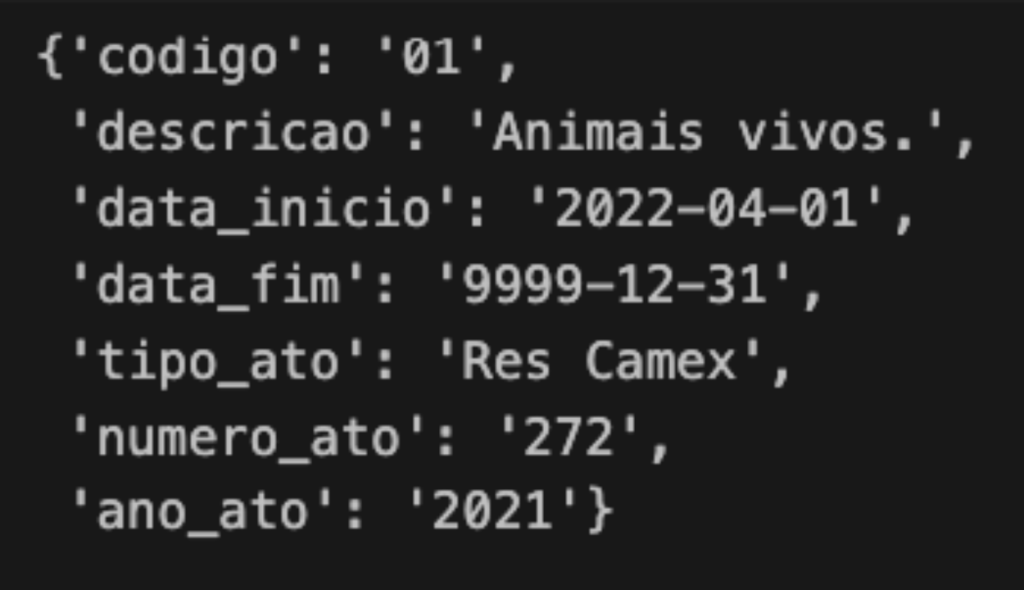
objetos = json.loads(resposta.text)Agora, uma breve verificação se os dados retornaram com sucesso, acessando o primeiro registro da lista objetos.
# verificando o primeiro registro objetos[0]
E então, temos o resultado na imagem abaixo.
Na sequência, faremos a transformação dos dados da API em um DataFrame Spark.
# transfomando dados da API em dataframe spark df_ncm = spark.createDataFrame(objetos)
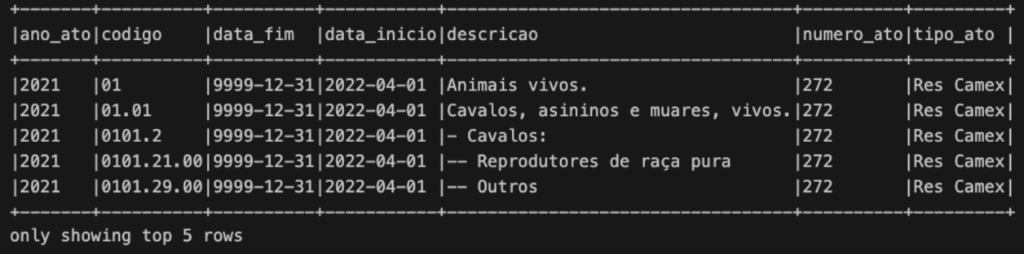
Para verificar se a transformação do DataFrame foi correta, podemos exibir as primeiras linhas através do comando show.
# verifica as primeiras linhas df_ncm.show(5, truncate=False)
Dessa forma, já temos o dado em um DataFrame Spark conforme a imagem abaixo.
Inserir Dados no Cassandra com Spark
Agora podemos utilizar o comando write do Spark, para escrever o DataFrame no Cassandra com PySpark. Alguns detalhes importantes no format informamos o formato de escrita dos dados. No options Informamos em qual keyspace e tabela queremos escrever no Cassandra. Na sequência, temos outra option onde informamos que queremos truncar (apagar) os dados da tabela antes de inserir. Com a tabela truncada, podemos utilizar o mode overwrite (sobrescrever) e finalizamos com o save para salvar os dados no Cassandra.
# inserir dados no cassandra com o Python
df_ncm.write\
.format("org.apache.spark.sql.cassandra")\
.options(table="tb_ncm", keyspace="ks_dadosaocubo")\
.option("confirm.truncate", "true")\
.mode("overwrite").save()Depois de inserir, podemos consultar os dados no Cassandra com o Python.
Consultando Dados no Cassandra com Python
Também podemos consultar os dados no Cassandra utilizando Python de diversas formas. primeiro veremos a forma mais tradicional e simples, utilizando o comando SELECT.
session.execute("SELECT * FROM system_schema.keyspaces").one()Neste primeiro execute, utilizamos o método one para retornar apenas uma linha conforme a imagem abaixo.

Agora, faremos a mesma consulta porém utilizando o método all.
session.execute("SELECT * FROM system_schema.keyspaces").all()Dessa forma, ele retornar todas as linha conforme a imagem abaixo.

Porém, se estivermos trabalhando com grandes volumes de dados talvez tenhamos soluções melhores, hora de conferir como consultar os dados no Cassandra com PySpark.
Consultando Dados no Cassandra com Spark
Aqui utilizamos o comando read do Spark, para ler os dados no Cassandra com PySpark. Também colocamos format para o Python saber o formato de leitura dos dados. No options Informamos em qual keyspace e tabela queremos ler no Cassandra. Finalizamos com o load para carregar os dados do Cassandra no DataFrame Spark.
# ler dados no cassandra com o Python
df_ncm_read = spark.read\
.format("org.apache.spark.sql.cassandra")\
.options(table="tb_ncm", keyspace="ks_dadosaocubo")\
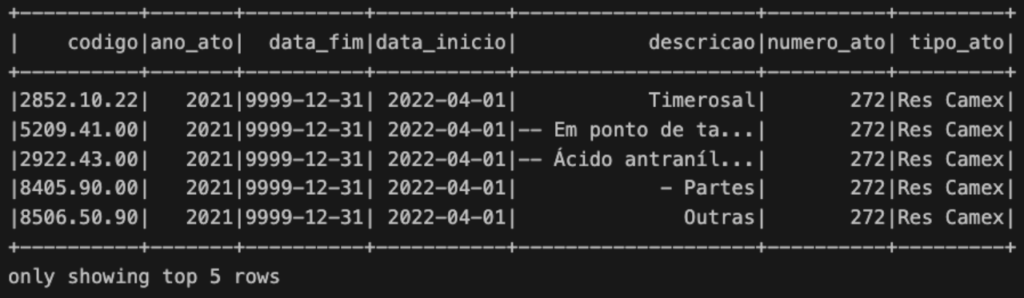
.load()Para verificar o DataFrame, podemos exibir as primeiras linhas através do comando show.
# visualizar as primeiras linhas df_ncm_read.show(5)
E assim, já temos os dados formatados e prontos para manipulação com o Spark.
Para fechar com chave de ouro uma dica bônus para quem gosta de uma ferramenta visual de manipulação de banco de dados. Confere a seguir, como manipular os dados do Cassandra com SQLPad.
Cassandra com SQLPad
Aqui, também vamos utilizar o docker para instalação do SQLPad. Com o único comando docker run com alguns parâmetros, subiremos uma imagem da aplicação e podemos acessar ela no localhost:3000.
### SQLPAD para conectar no cassandra docker run --name sqlpad --network dadosaocubo -p 3000:3000 --env SQLPAD_ADMIN=admin --env SQLPAD_ADMIN_PASSWORD=123456 sqlpad/sqlpad:latest
Após executar a aplicação SQLPad, criaremos uma conexão com Cassandra conforme imagem abaixo.
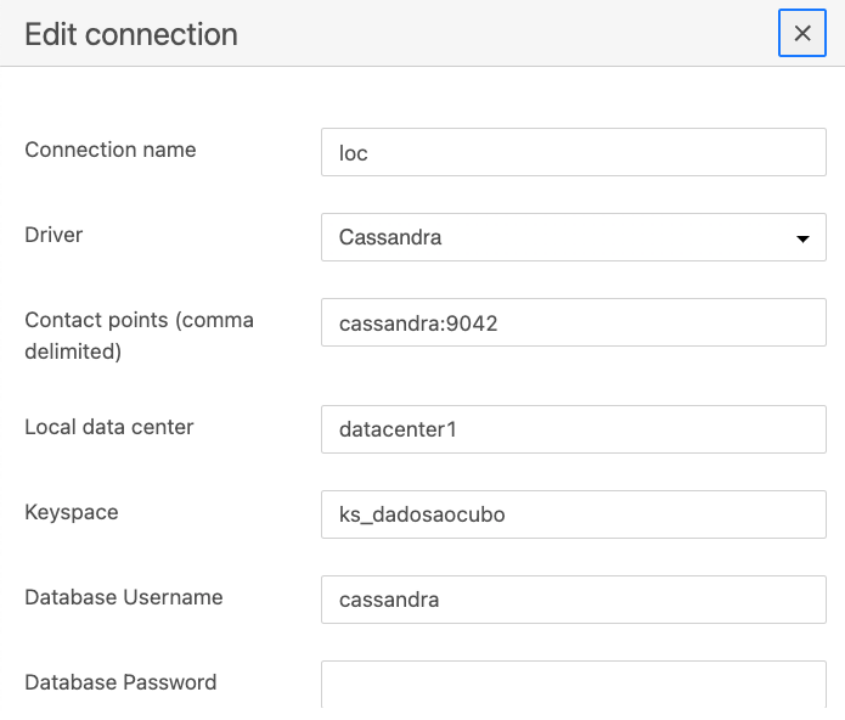
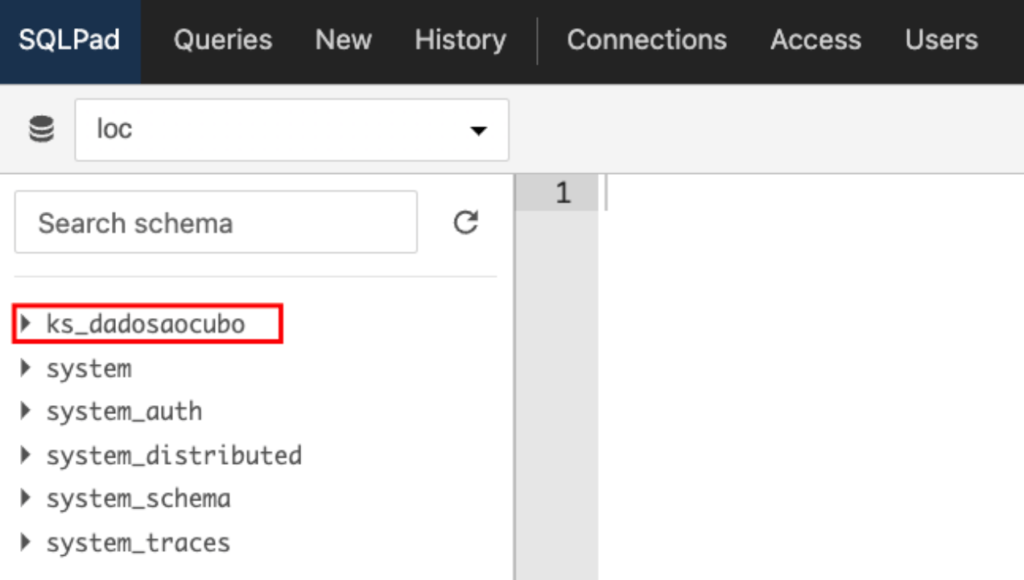
Com a conexão realizada, já podemos visualizar todos os keyspaces do nosso banco Cassandra
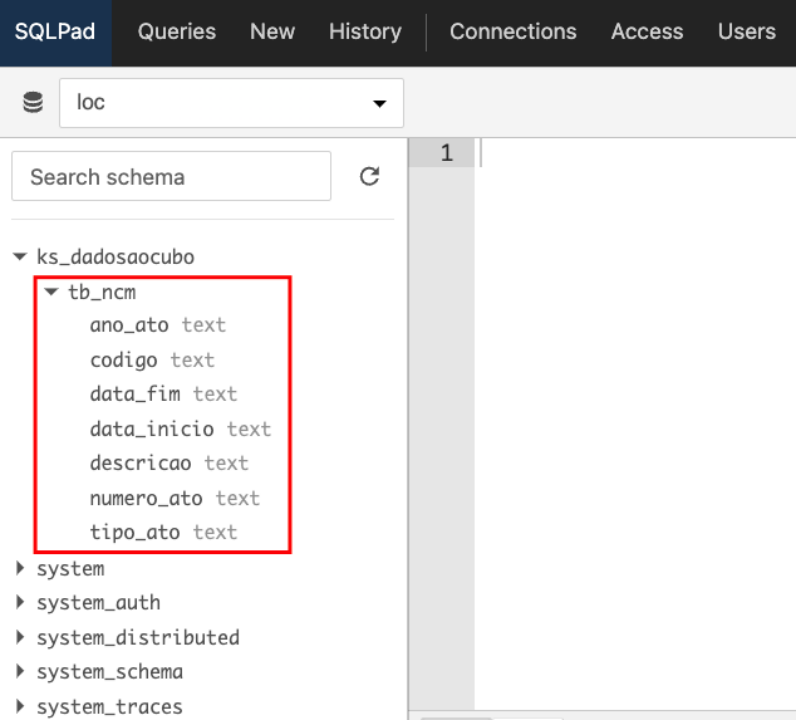
Também podemos visualizar, as tabelas dentro do keyspace bem como sua estrutura colunar.
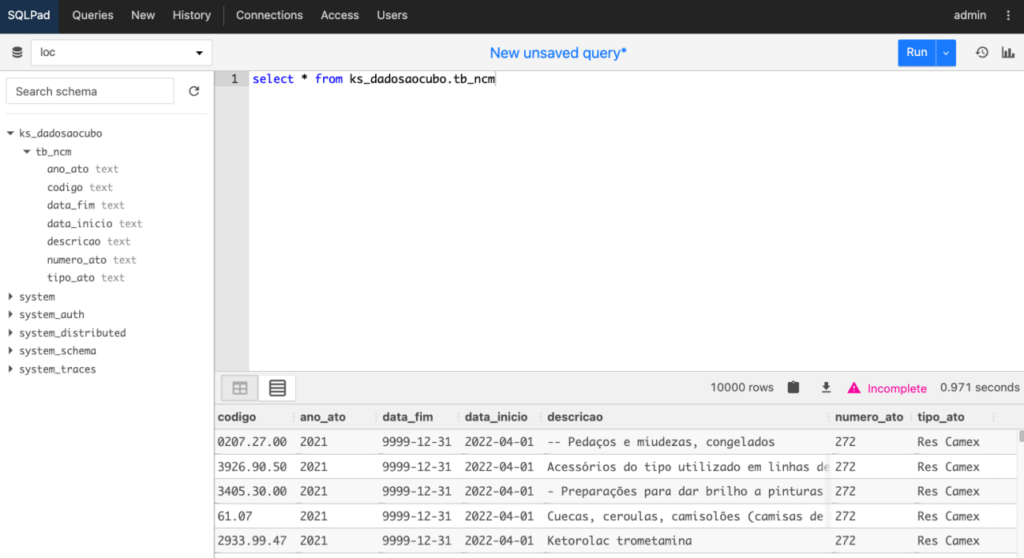
E para fechar, executamos um SELECT * FROM na tabela criada e obtemos os dados da consulta, da mesma forma que visualizamos com o Python.
E então, chegamos ao fim desse passo a passo de como manipular o Cassandra com Python.
Cassandra com Python ao Cubo
Agora você já sabe o que é o banco de dados Apache Cassandra e como ele surgiu. Qual biblioteca Python para manipular dados no Cassandra e como instalar. Criar um banco de dados Cassandra com Docker de forma bem simples. Fazer uma conexão do Python com Cassandra. Criar keyspaces e tabelas no Cassandra com Python, também como deletar os mesmos. Inserir dados em uma tabela do Cassandra com o Python através da biblioteca cassandra-driver e com o Pyspark. Consultar dados de uma tabela no Cassandra com o Python. Inserir e consultar dados no Cassandra com Spark para trabalhar com grandes volumes de dados. E para fechar conectar ao Cassandra com o SQLPad uma ferramenta visual. É bastante coisa em? Mas é só o começo! Um abraço e até a próxima.
Conteúdos ao Cubo
Então, se você curtiu o conteúdo, aqui no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar. Sempre falando sobre o mundo dos dados!
- O que as Vagas em Dados nos Dizem Sobre o Amanhã
- Business Intelligence e Data Warehouse: Guia Para Iniciantes
- Domine o Mundo dos Dados com o Curso Pentaho Data Integration do Zero – Passo a Passo
- Ordenação Lexicográfica versus YYYY-MM-DD
- Data Discovery com a Biblioteca Lux Python
- Série de Automatização de Tarefas com Python
- Descubra Como Utilizar o DBSCAN em Python para Análise de Dados
- Extrair Dados da API do Cartola FC
Portanto, para finalizar, se torne também Parceiro de Publicação Dados ao Cubo. Escreva o próximo artigo e compartilhe conhecimento para toda a comunidade de dados.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
