
Fala galera do mundo dos dados! Hoje vamos falar de agrupamento de dados, mais especificamente de como utilizar o DBSCAN em Python para análise de dados. O DBSCAN (Density-Based Spatial Clustering of Applications with Noise) é um algoritmo de clusterização amplamente utilizado em análise de dados. Ele é capaz de identificar grupos em dados de alta dimensionalidade e é uma alternativa popular ao K-Means (confere o artigo Agrupamento com scikit-learn), especialmente quando não há conhecimento prévio do número de clusters.
Neste post, vamos explorar como utilizar o DBSCAN em Python para análise de dados, utilizando a biblioteca scikit-learn.
Como Funciona o DBSCAN
Primeiro, vamos entender o funcionamento do DBSCAN. Ele funciona criando clusters baseados na densidade dos pontos. Pontos próximos são considerados parte do mesmo cluster, enquanto pontos isolados são rotulados como ruído.
Em Python, a implementação do DBSCAN pode ser feita utilizando a biblioteca scikit-learn.
DBSCAN na Prática
Agora veremos na prática como aplicar o DBSCAN em Python, utilizando a biblioteca sklearn. Primeiramente faremos a importação das bibliotecas necessárias.
Importando bibliotecas
Vamos começar importando as bibliotecas necessárias. A sklearn, biblioteca para aplicação de modelos de machine learning, inclusive o DBSCAN. O Pandas para manipulação dos dados. Finalizando com a Matplotlib para visualização dos dados de forma gráfica.
from sklearn.cluster import DBSCAN from sklearn.datasets import make_blobs import pandas as pd import matplotlib.pyplot as plt
Bibliotecas importadas, agora faremos a criação do conjunto de dados.
Gerando dados aleatórios
Agora, vamos gerar alguns dados aleatórios para utilizar como exemplo, com a função make_blobs do sklearn.
X, y = make_blobs(n_samples=500, centers=4, cluster_std=0.60, random_state=0)
Em seguida uma transformação nos dados para o formato de dataframe com o Pandas.
df = pd.DataFrame(X,columns=['X1','X2'])
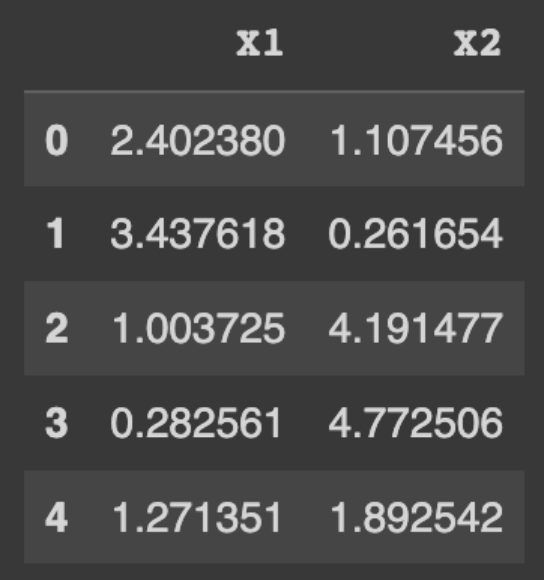
Confere como ficou o conjunto de dados de exemplo.
Uma outra forma de visualizar o conjunto de dados é com a ajudinha do Matplotlib. Observe a construção do gráfico de dispersão com a função scatter no código Python abaixo.
plt.scatter('X1', 'X2', data=df)
plt.show()E então, temos o gráfico de dispersão utilizando o dataframe criado no passo anterior.
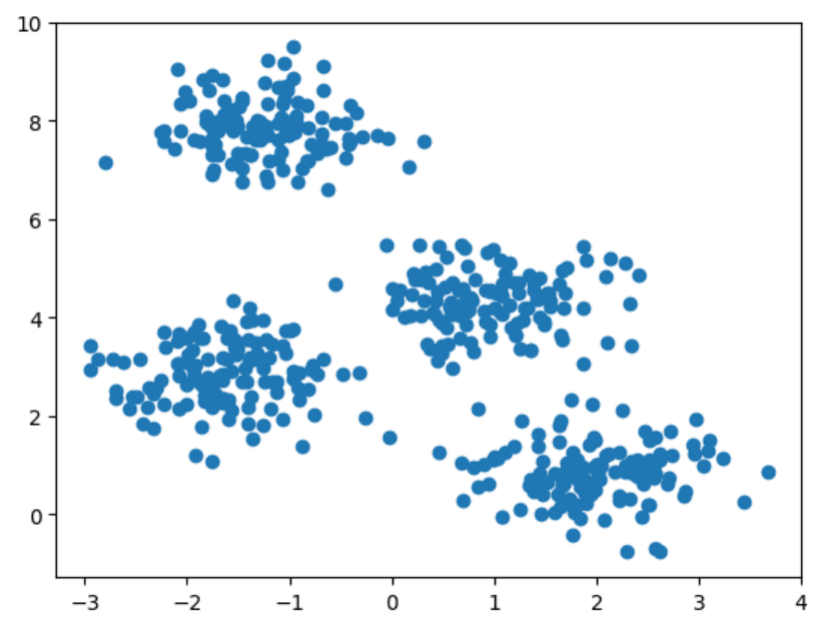
Sendo assim, já temos os dados necessários para aplicar o DBSCAN.
Aplicando o DBSCAN
Com os dados gerados, podemos agora aplicar o DBSCAN para encontrar clusters, confere o código Python a seguir. Aqui, estamos definindo um valor para eps, que é o raio máximo de um cluster, e min_samples, que é o número mínimo de pontos necessários para formar um cluster.
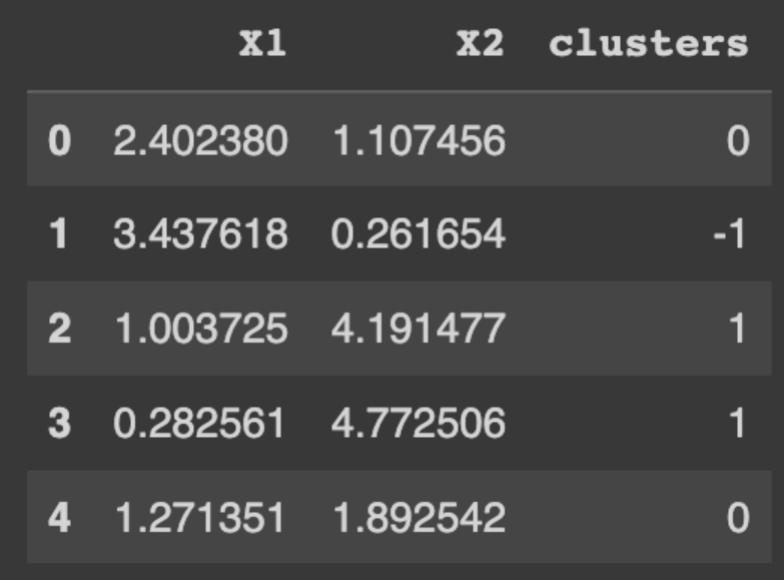
dbscan = DBSCAN(eps=0.5, min_samples=5) clusters = dbscan.fit_predict(df) df['clusters'] = clusters
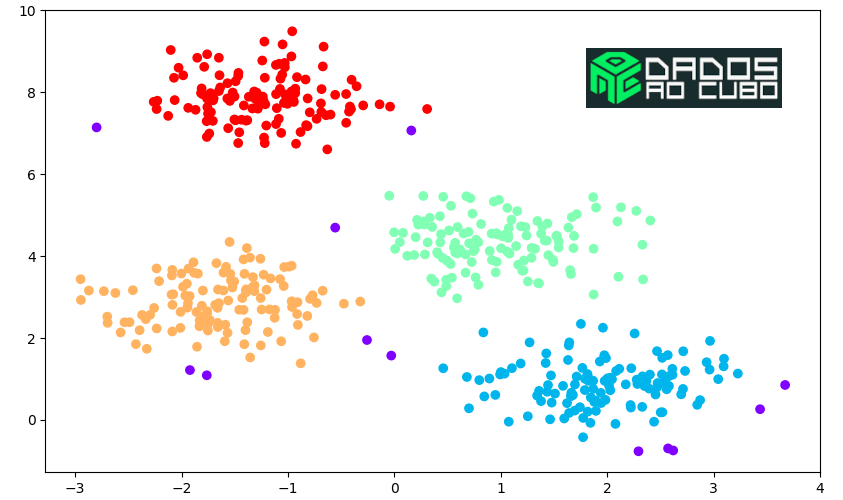
Na imagem a seguir temos os clusters que foram gerados a partir da função DBSCAN.
Para visualizar os resultados, podemos utilizar o matplotlib e plotar o mesmo gráfico de dispersão criado anteriormente. Porém agora, utilizaremos os clusters gerados para colorir o gráfico. Se liga no código Python na sequencia.
plt.scatter('X1', 'X2', data=df, c='clusters', cmap='rainbow')
plt.show()E então, temos o resultado abaixo.
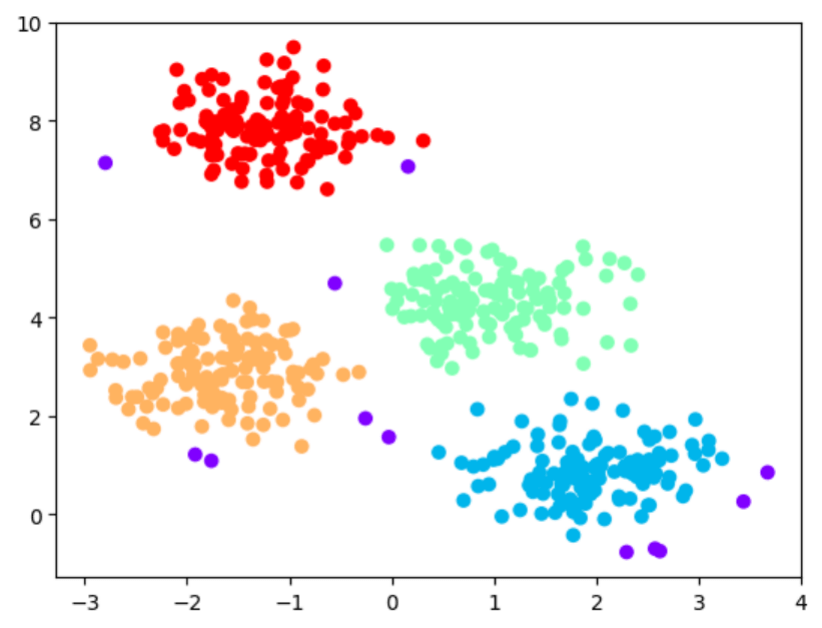
Agora, atribuímos a cada ponto um rótulo correspondente ao seu cluster (vermelho, amarelo, verde e azul). Consideramos pontos com rótulo -1 como ruídos (lilás).
O DBSCAN também permite ajustar outros parâmetros, como a metric, que determina a medida de distância usada para definir a densidade dos pontos, e o algorithm, que especifica o método usado para identificar pontos próximos. Experimenta utilizar nas suas análises.
DBSCAN ao Cubo
A biblioteca scikit-learn torna fácil o uso do DBSCAN para análise de dados em Python. Com suas capacidades de encontrar clusters em dados de alta dimensionalidade e tratar ruídos, ele pode ser uma ferramenta valiosa para diversas aplicações.
Portanto, experimente utilizar o DBSCAN em seus próprios dados e veja como ele pode ajudar a identificar padrões e insights valiosos. Imagina agrupar os clientes? Ou os produtos?
E então, esta é uma introdução ao DBSCAN.Não perca as novidades do Dados ao Cubo! Então, fica ligado com a nossa Newsletter. Um abraço e até a próxima!!!
Conteúdos ao Cubo
Se você curtiu o conteúdo, aqui no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar. Sempre falando sobre o mundo dos dados!
- Time de Dados na Prática
- Etapas para Análise de Dados
- Tipos de Análise de Dados
- Dicas para Visualização de Dados
- Análise de Dados com Airbyte e Metabase
- Importar CSV no PostgreSQL com o DBeaver
- Deploy do Airbyte com Docker
Finalizamos com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
