

Fala galera! Espero que estejam todos bem. Hoje vamos resolver mais um problema de NLP desta vez usando uma Rede Neural Recorrente ou apenas RNN. What?! A ideia é fazer o processamento de linguagem natural com TensorFlow. Calma, quando mostrar o nosso modelo te explico direitinho o que é. Para isso vamos utilizar uma biblioteca muito importante para a evolução das redes neurais, o TensorFlow.
Então, sem mais delongas, vamos entender melhor o que é o TensorFlow. Mas se não sabe o que é NLP sugiro ver o post NLP com scikit-learn, que tem conceitos importante sobre processamento de linguagem natural, temas que vou abordar aqui.
O que é o TensorFlow?
TensorFlow é uma biblioteca para aprendizado de máquina de código aberto criada pelo Google. Com ele é possível criar redes neurais que funcionam de forma análoga ao aprendizado e raciocínio humano.
As redes neurais artificiais, que podem ser criadas com TensorFlow, são inspiradas no sistema nervoso central animal em forma de modelos matemático. Tornando possível o aprendizado de máquina e o reconhecimento de padrões.
Na teoria é tudo muito lindo, mas vamos resolver alguns problemas de processamento de linguagem natural com o TensorFlow.
O Problema
Vamos desenvolver um modelo de aprendizado de máquina para prever uma das quatro categorias de problemas de saúde mental (depressão, suicídio, alcoolismo e drogas).
Para isso temos um dataset com declarações e perguntas expressas por estudantes de várias universidades do Quênia que relataram sofrer com esses diferentes desafios de saúde mental. Estes dados foram de uma competição no Zindi.
Então com o modelo, vai ser possível classificar uma declarações ou perguntas dentro das quatro categorias de problemas de saúde mental. Partiu Python ao Cubo!
Carregando Bibliotecas e Dataset
Primeiramente vamos começar importando todas as bibliotecas para rodar o nosso modelo. Destaque para as biblioteca Pandas, Numpy, NLTK e TensorFlow! Pandas utilizamos para importar e organizar os nossos dados em formato de data frame. Numpy utilizamos para fazer algumas conversões importantes com nossos dados. NLTK utilizamos para trabalhar com o texto, muito poderosa para problemas de NLP. Por fim o TensorFlow que utilizamos para o nosso modelo de machine learning. As demais bibliotecas foram utilizadas de forma auxiliar e vou te explicar no decorrer do código.
# Importação das bibliotecas
import pandas as pd
import numpy as np
import nltk
nltk.download('stopwords')
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.tokenize.treebank import TreebankWordDetokenizer
import wordninja
import textblob
import collections
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoderApós as bibliotecas importadas vamos carregar o dataset para começar a trabalhar os dados.
# Importação dos dataset
df = pd.read_csv('https://raw.githubusercontent.com/dadosaocubo/nlp/master/mental_health.csv')Preparação dos Dados
Vamos começar a preparar os dados para serem consumidos pelo modelo. Então, criamos algumas variáveis que vamos utilizar mais a frente. A lista de palavras vazias (stop_words), o tamanho da base para teste (test_size) e duas variáveis para o modelo quantidade de épocas (epochs) e número de exemplos por lote (batch_size).
# Palavras para retirar da análise
stop_words = stopwords.words('english')
# Variável tamanho da base de teste
test_size = 0.1
# Variáveis do modelo
epochs = 10
batch_size = 128Agora vamos começar a tratar os nosso dados, fazer aquela faxina. Dessa forma o “lixo” que vamos tirar, não vai atrapalhar o nosso modelo.
Limpeza dos Dados
O primeiro passo separar as possíveis palavras concatenadas. Para essa tarefa criamos a coluna text_split e aplicamos a função split da biblioteca wordninja. Na sequência criamos a coluna text_new e aplicamos a função TreebankWordDetokenizer().detokenize para formar novamente um texto com as palavras separadas.
# Separando palavras juntas df['text_split'] = df['text'].apply(wordninja.split) df['text_new'] = df['text_split'].apply(TreebankWordDetokenizer().detokenize)
Agora vamos corrigir palavras escritas de forma incorreta. Dessa vez vamos aplicar a função textblob.TextBlob.correct da biblioteca textblob na mesma coluna text_new . Observe que já existe muita coisa pronta em python, basta saber encontrar para utilizar.
# Corrigindo palavras incorretas df['text_new'] = df['text_new'].apply(textblob.TextBlob).apply(textblob.TextBlob.correct).apply(str)
Para o tratamento de números, pontuação e caracteres especiais utilizamos expressões regulares sempre aplicando na coluna text_new. No fim deste bloco aplicamos a função lower para deixar todas as letras e caixa baixa.
# Excluindo da descrição os números.
df['text_new'] = df['text_new'].str.replace('[0-9]+', '', regex=True).copy()
# Excluindo da descrição pontuação.
df['text_new'] = df['text_new'].str.replace('[,.:;!?]+', ' ', regex=True).copy()
# Excluindo da descrição caracteres especiais.
df['text_new'] = df['text_new'].str.replace('[/<>()|\+\-\$%&#@\'\"]+', ' ', regex=True).copy()
# Colocando todos os caracteres em caixa baixa.
df['text_new'] = df['text_new'].str.lower().copy()Por fim, na limpeza de dados vamos remover as palavras vazias, mais conhecidas como stop words. Para essa tarefa, criei a função tokenize_df (Faltou um pouco de criatividade no nome :-)) para remover as palavras vazias e retornar somente o conteúdo útil do texto.
# Função para retirar stop words def tokenize_df(tokenized_words): tokenized_words = word_tokenize(tokenized_words) stop = [word for word in tokenized_words if word not in stop_words] text = TreebankWordDetokenizer().detokenize(stop) return text # Eliminando as stop words df['text_new'] = df['text_new'].apply(tokenize_df).copy()
A cada etapa dessa realizada acima, podemos exibir as primeiras linhas do dataframe com a função head para ver se cada etapa está sendo feita corretamente. No notebook que que vou disponibilizar no final foi feito essa análise.
Ao final dessa limpeza estamos pronto para o input no modelo? Não! Precisamos transformar nossa coluna text_new em objetos do tipo tensor para que o modelo entenda os dados. Vamos ver como fazer essa transformação!
Transformação para Input no Modelo
Vamos começar gerando uma lista de palavras únicas de todas as declarações e perguntas das base após a limpeza.
# Selecionando as únicas palavras da variável text_new df['text_new_split'] = df['text_new'].apply(word_tokenize).copy() text = list(df.text_new_split) list_words = [item for sublist in text for item in sublist] list_words = sorted(list_words) only_words = set(list_words)
Com o código acima criamos uma lista com todas as palavras na variável list_words e com a função set removemos as palavras duplicadas gerando a variável only_words apenas com as palavras únicas.
Então, vamos gerar o nosso codificador de palavras com o vocabulário de palavras únicas q criamos assim. Para isso vamos usar a função SubwordTextEncoder(vocab_list=only_words), passando como parâmetro a nossa lista de palavras únicas only_words.
# Gerando encoder com o vocabulário das palavras encoder = tfds.features.text.SubwordTextEncoder(vocab_list=only_words)
O encoder acima foi para a nossa feature, ou seja, nossa variável de entrada. Precisamos agora fazer o codificador do target ou nossa variável de saída. Vamos usar a função do scikit-learn LabelEncoder, como pode ver no código abaixo.
# Encode do label label_encode = LabelEncoder() target = label_encode.fit_transform(df['label'])
Agora precisamos definir as nossas variáveis de feature e target, como podemos ver no código abaixo representadas como x e y. Ainda usando o scikit-learn com a função train_test_split dividimos os dados em treino e teste para fazer uma avaliação de performance do modelo. Lembra da variável test_size que definimos lá no ínicio do item 4.? Agora vamos usar ela para definir o tamanho dos dados de teste.
# Definindo feature e target x = df['text_new'] y = target # Dividindo dataset em treino e teste x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=test_size)
Por fim na transformação do input, vamos converter os dados de entradas para o formato de tensor.
Para essa etapa crie duas funções. A função pad_to_size que define o tamanho do vetor e complementa com zeros. E a função encode_input que pega o texto, converte em vetor usando a função encoder (que falei um pouco mais acima) completa o vetor com zeros com a função pad_to_size e por fim transforma esse vetor em um tensor com a função tf.cast.
# Função para criação da matriz
def pad_to_size(vec, size):
zeros = [0] * (size - len(vec))
vec.extend(zeros)
return vec
# Função para encode do input
def encode_input(text_new):
list_x = []
for text in text_new:
text_encode = encoder.encode(text)
text_encode = pad_to_size(text_encode, 64)
list_x.append(text_encode)
# Convertendo x em tensor
input_encode = tf.cast(list_x, tf.float32)
return input_encode
# Encode do x_train e x_test
x_train = encode_input(x_train)
x_test = encode_input(x_test)Então saímos com os dados prontos para o input no modelo. Agora vamos ver como criar esse modelo.
Modelo do TensorFlow
Para a resolução do problema vamos utilizar uma Rede Neural Recorrente. Agora preciso em poucas palavras te dizer o que é uma RNN.
Para definir uma RNN vamos ver a definição encontrada no Machine Learning Glossary do Google, adaptada e traduzida:
“Uma rede neural que é executada intencionalmente várias vezes, em que partes de cada execução alimentam a próxima execução. Especificamente, as camadas ocultas da execução anterior fornecem parte da entrada para a mesma camada oculta na execução seguinte. As redes neurais recorrentes são particularmente úteis para avaliar sequências, para que as camadas ocultas possam aprender com as execuções anteriores da rede neural em partes anteriores da sequência.”
De uma forma bruta é uma rede que tem como entrada nas camadas ocultas a própria saída de forma intencional até encontrar a equação matemática desejada.
As redes RNN são boas em resolver problemas de NLP, então criamos uma com 6 camadas, e vamos detalhar um pouco mais essas camadas a seguir.
# Criação do modelo de RNN inputs = keras.Input(shape=(None,), dtype="int64") x = layers.Embedding(encoder.vocab_size, 128)(inputs) x = layers.Bidirectional(layers.LSTM(64, return_sequences=True))(x) x = layers.Bidirectional(layers.LSTM(64))(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(4, activation="softmax")(x) model = keras.Model(inputs, outputs) model.summary()
Com a função summary é possível ter um resumo do modelo criado como podemos ver na imagem abaixo.
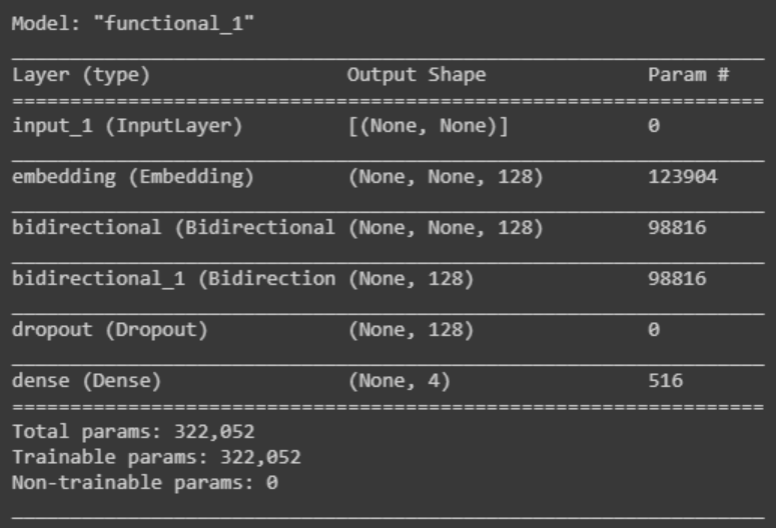
Ficou curioso para saber o que cada camada do modelo faz? Vamos ver os detalhes agora.
Input no TensorFlow
É uma camada obrigatória em todos os modelos, é a camada que recebe os dados de entrada.
Embedding no TensorFlow
É a camada onde é feita a tradução do vetor de entrada em alta dimensão para uma para um espaço de baixa dimensão.
LSTM no TensorFlow
LSTM é a abreviação de Long Short-Term Memory em tradução livre Memória Longa de Curto Prazo. É a camada responsável por armazenar em memória a informação das camadas anteriores, mantendo um histórico das novas entradas para melhorar a performance do modelo.
Dropout no TensorFlow
Esta é uma camada de regularização da rede, que aleatoriamente exclui um número fixo de unidades em uma camada, para forçar uma regularização do modelo.
Dense no TensorFlow
É a nossa camada de saída, a qual está conectadas a todos os nós das camada ocultas anteriores.
Treinamento do Modelo
Com o nosso modelo pronto, podemos compilar com a função compile. Onde é definido a função de perda com o parâmetro loss, a função de otimização com o parâmetro optimizer e a métrica com o parâmetro metrics.
Compilado, então vamos treinar o nosso modelo!
# Compilando modelo e configurando o processo de treinamento
model.compile(loss="sparse_categorical_crossentropy",
optimizer="rmsprop",
metrics=['accuracy'])
# Treinando o modelo
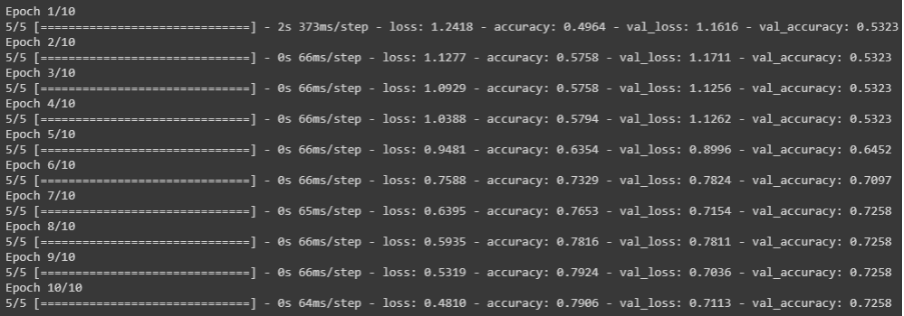
history = model.fit(x_train, y_train, epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, y_test))As variáveis epochs e batch_size que definimos no início do item 4, usamos no nosso modelo para treinamento. Então temos abaixo o resultado do treinamento do modelo ao final das 10 épocas definidas.
Avaliação do Modelo
Para avaliar o resultado do nosso modelo utilizei a função evaluate, que retorna a função de perda e a acurácia do nosso modelo.
# Testando a qualidade do modelo
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test Loss: {}'.format(test_loss))
print('Test Accuracy: {}'.format(test_acc))Uma acurácia de 72,5% não é ruim, mas dá para melhorar muito, caso tenha sugestões de melhoria no modelo só deixar aí nos comentários! Assim a comunidade agradece.

Predição com o Modelo
Enfim o modelo está pronto, treinado e avaliado! Sendo assim, para testar novas entradas fiz a função sample_predict que retorna a probabilidade de cada uma das 4 classes.
# Função para predição def sample_predict(sample_pred_text): encoded_sample_pred_text = encoder.encode(sample_pred_text) encoded_sample_pred_text = tf.cast(encoded_sample_pred_text, tf.float32) predictions = model.predict(tf.expand_dims(encoded_sample_pred_text, 0)) return (predictions)
Com as probabilidades de cada classe, usamos a função argmax do numpy para retornar a posição com a probabilidade mais alta. Dessa forma podemos usar essa posição na função inverse_transform que retorna o label da nossa classe. Podemos ver isso no código abaixo.
# Predição do exemplo
example = 'feel better die happy'
predictions = sample_predict(example)
probabilities = [np.argmax(predictions[0])]
# Retornando os labels
new_label = label_encode.inverse_transform(probabilities)
print('O exemplo "{}" foi classificado como "{}"'.format(example, new_label[0]))
O exemplo "feel better die happy" foi classificado como "Depression"Processamento de Linguagem Natural com TensorFlow ao Cubo
Muita coisa né!? Espero que eu tenha conseguido transmitir da melhor forma possível. Então vimos aqui hoje uma introdução ao processamento de linguagem natural com TensorFlow e criamos uma RNN com ele. Com isso resolvemos um problema de classificação com NLP. Vimos algumas formas de tratar dados com técnicas de NLP e também algumas transformações com esses dados.
Esse código completo está no GitHub, e lá deixei um bônus, tradução de texto com Python com a biblioteca googletrans, em poucas linhas de código é possível fazer tradução de textos com Python! Mas, não esqueça de deixar aquele comentário e até a próxima!
Referências para TensorFlow
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Machine Learning com ML.Net no Jupyter Notebook
- Análise Exploratória com ML.Net e Jupyter Notebook no Ubuntu
- ML.Net – Modelos em Produção com WebApi e Docker
- AutoML (Automated Machine Learning) com ML.Net
- Analisando Dados do Brasileirão Série A
- Loops em Python
- Análise de Dados Poderosa com Polars em Python
- Descubra Como Utilizar o DBSCAN em Python para Análise de Dados
Portanto, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀

2 Comments
paulohsms
3 de março de 2022massa demais, consegui entender um pouco melhor que dá pra usar o tensorflow com o NLTK interessante mesmo.
Tiago Dias
3 de março de 2022Que legal Paulo! Qualquer dúvida manda para nós.