

Olá, apaixonados por futebol e análise de dados! Estão prontos para uma nova imersão no universo do Dados ao Cubo? Desta vez, nosso foco se volta para os dados do Brasileirão, o principal campeonato brasileiro de futebol, estruturado no formato de pontos corridos. Então, o objetivo deste estudo é desvendar insights fascinantes e tendências que emergem desse esporte tão amado, oferecendo a vocês uma perspectiva detalhada sobre as competições mais acirradas do país.
Portanto, se você é novo por aqui ou ainda não se familiarizou com o Brasileirão, não se preocupe! Vamos começar com um breve resumo para apresentar esse emocionante campeonato a todos, independentemente do nível de conhecimento sobre o assunto. Prepare-se para mergulhar nos dados do futebol brasileiro e descobrir tudo que faz do Brasileirão uma competição única e imperdível.
Um Resumo do Brasileirão Série A
O Campeonato Brasileiro Série A é o principal torneio de futebol do país, onde 20 clubes disputam em sistema de pontos corridos em dois turnos. Assim, ao final da competição, o time que tiver a melhor performance é coroado campeão, enquanto os quatro clubes com as piores campanhas sofrem o rebaixamento para o Campeonato Brasileiro Série B do ano seguinte, o qual mantém o mesmo formato.
Em 2003, implementou-se o sistema de pontos corridos, e, em 2006, adotou-se o formato atual com 20 clubes. Com a introdução do tema concluída, vamos aos detalhes.
DataSets do Brasileirão
Você pode encontrar os datasets utilizados nas análises realizadas e as referências nos links a seguir.
DataSets
- campeonato-brasileiro-pontos-corridos-2003-2020-periodo.csv
- campeonato-brasileiro-pontos-corridos-2003-2020-jogos.csv
Referências dos DataSets
- https://github.com/adaoduque/Brasileirao_Dataset
- https://pt.wikipedia.org/wiki/Campeonato_Brasileiro_de_Futebol_de_2003
Sendo assim, agora que já temos os dados necessários, seguimos para as análises.
Partiu Brincar com os Dados do Brasileirão
Então vamos começar?
Primeiramente, importamos as bibliotecas usadas nas análises. Destacamos as bibliotecas pandas, seaborn e pyplot da matplotlib. Usamos a primeira biblioteca para manipular os dados, permitindo ler e transformar os datasets. Já as duas últimas bibliotecas para construir os gráficos.
Importando Bibliotecas
Abaixo o código python para importação das bibliotecas.
### importando bibliotecas import pandas as pd import warnings as wa import seaborn as sns import matplotlib.pyplot as plt ### ignorando warnings do tipo FutureWarning wa.simplefilter( action='ignore', category= FutureWarning) pd.options.mode.chained_assignment = None
Após importação das bibliotecas, iremos carregar as bases de dados.
Carregando Dados do Brasileirão
Para a leitura dos datasets vamos utilizar o método read_csv do pandas. Observe que chamamos o método usando o alias pd do pandas definido na importação da biblioteca.
Importante definir o atributo delimiter como ponto e vírgula (;), pois os arquivos não estão delimitados com o delimitador padrão de arquivos csv que é a vírgula (,).
### carrega datasets path_periodo = "https://github.com/juvenalfonseca/python/blob/master/datasets/campeonato-brasileiro-pontos-corridos-2003-2020-periodo.csv?raw=true" path_jogos = "https://github.com/juvenalfonseca/python/blob/master/datasets/campeonato-brasileiro-pontos-corridos-2003-2020-jogos.csv?raw=true" df_periodo = pd.read_csv(path_periodo, delimiter=";") df_jogos = pd.read_csv(path_jogos , delimiter=";")
Antes de iniciar as análises é importante a realização do tratamento dos dados. Quase sempre, no processo da análise exploratória de dados, é necessário realizar eventuais ajustes na base de dados. Dessa forma conseguimos identificar partes incompletas, incorretas, imprecisas ou irrelevantes dos dados e, em seguida, realizar os devidos ajustes necessários.
Tratamento dos Dados do Brasileirão
Neste ponto, definimos que todas as colunas dos dataframes lidos serão utilizadas em caixa baixa. Para isso, usamos o método lower nas propriedades columns.str.
### padroniza caixa dos nomes das variáveis df_periodo.columns = df_periodo.columns.str.lower() df_jogos.columns = df_jogos.columns.str.lower()
O método to_datetime converte os campos que têm características de datas, mas que foram carregados como strings. Nesse método também é definido o formato da data.
### altera campos de datas de character para date df_periodo['inicio' ] = pd.to_datetime(df_periodo['inicio'], format="%d/%m/%Y") df_periodo['fim' ] = pd.to_datetime(df_periodo['fim' ], format="%d/%m/%Y") df_jogos['data' ] = pd.to_datetime(df_jogos['data' ], format="%d/%m/%Y")
Ao utilizar o método title é realizada a padronização dos campos de formato texto. Dessa forma os textos são iniciados com letras maiúsculas seguidos por letras minúsculas.
Para realizar essa transformação foram utilizadas duas formas de acesso ao método title. A primeira de forma direta através da propriedade str e a segunda utilizando o método apply com lambda.
### captalizar strings df_jogos['dia' ] = df_jogos['dia' ].str.title() df_jogos['mandante' ] = df_jogos['mandante' ].str.title() df_jogos['visitante'] = df_jogos['visitante'].str.title() df_jogos['vencedor' ] = df_jogos['vencedor' ].str.title() df_jogos['arena' ] = df_jogos['arena' ].apply(lambda x: x.title())
Junção dos Dataframes
Para a junção dos dataframes foi definido, para cada um, um novo atributo com o nome key. Como os dataframes df_periodo e df_jogos não têm atributos em comum o atributo key é utilizado como chave para a junção de ambos os dataframes.
Ao definir o atributo key com valor 1 (um) para todos os registros é realizada a junção full join para que todos os registros de ambos os dataframes sejam relacionados. Feito isso é aplicado filtro para considerar apenas os registros que a data de realização do jogo esteja entre a data de início e fim da realização do torneio.
Resumindo a junção dos dataframes:
- merge: método utilizado para a junção entre os dataframes;
- on: indica o campo utilizado na junção;
- drop: remove a coluna do dataframe;
- query: filtra os registros conforme o critério especificado.
### junta os datasets e retorna apenas os registros corretos criados na junção
df_periodo['key'] = 1
df_jogos['key'] = 1
df = pd.merge(df_periodo, df_jogos, on ='key').drop("key", 1)
df = df.query('data >= inicio & data <= fim')Após a criação do novo dataframe (df), podemos visualizar os cinco primeiros registros utilizando o método head. O parâmetro no método indica a quantidade de registros exibidos.
df.head(5)
Observe na saída do resultado que o índice varia de 0 (zero) até 4 (quatro) já que o índice em python inicia em 0 (zero).

Agora sim! Vai começar a brincadeira, iniciaremos a análise de dados.
Análise de Gols do Brasileirão
O que seria o futebol sem gols? Não podemos imaginar. Gols é a essência da existência do futebol. E é por isso que não poderia faltar uma análise sobre ele.
Aqui analisamos os gols em cada edição do campeonato de pontos corridos. São definidos os gols de mandantes e visitantes, gols total, além dos percentuais de gols dos mandantes e visitantes em cada edição.
Interessante notar que em todas as edições os mandantes foram responsáveis pelo maior número de gols.
Mas detalhando o código, utiliza-se o método groupby para agrupar o conjunto de dados em um ou mais atributos. Neste caso, realizamos o agrupamento por torneio. Feito isso, a função sum, utilizado no formato lambda com o método de agrupamento agg, soma os valores encontrados na propriedade mandante placar no conjunto de dados selecionados. O método reset_index desagrupa o conjunto de dados realizada pelo método groupby.
Com o método rename a propriedade mandante placar é renomeada para gols mandantes no conjunto de dados resultado da operação. O atributo inplace=True indica que a operação deve ser efetivada no conjunto de dados.
O mesmo é realizado para determinar os gols dos visitantes e assim chegar ao número total de gols e o percentual de gols dos mandantes e visitantes.
### gols por edição
gols_mandante = df[['torneio', 'mandante placar']].groupby('torneio').agg(lambda x: sum(x)).reset_index()
gols_mandante.rename(columns = {"mandante placar": "gols_mandante"}, inplace=True)
gols_visitante = df.groupby('torneio')['visitante placar'].sum().sort_values(ascending=False).reset_index()
gols_visitante.rename(columns = {"visitante placar": "gols_visitante"}, inplace=True)
gols_edicao = pd.merge(gols_mandante, gols_visitante, on="torneio")
gols_edicao['gols_total' = gols_edicao['gols_mandante'] + gols_edicao['gols_visitante']
gols_edicao['gols_mandante_perc' ] = (gols_edicao['gols_mandante' ]/gols_edicao['gols_total'])*100
gols_edicao['gols_visitantes_perc'] = (gols_edicao['gols_visitante']/gols_edicao['gols_total'])*100
gols_edicao
Então temos algumas informações bem legais acima. Podemos observar o comparativo de gols a cada ano do campeonato. Um fato curioso é o percentual médio de 60% de gols mandantes (times que jogam no seu*** estádio). Na sequência, vamos analisar os ataques e defesas.
Análise por Ataque e Defesa do Brasileirão
Nesta análise é realizada a plotagem em gráfico de barras dos gols dos mandantes, visitantes e total por edição do torneio.
De novidade aqui é a utilização do método concat que realiza a junção dos três dataframes que indica os gols nas modalidades mandante, visitante e total. Os dataframes são concatenados como se utilizasse um union para formar um novo dataframe.
### gols por edição comparativo
df1 = gols_edicao[['torneio','gols_mandante' ]]
df2 = gols_edicao[['torneio','gols_visitante']]
df3 = gols_edicao[['torneio','gols_total' ]]
df1.rename(columns = {'gols_mandante' : 'gols' }, inplace=True)
df2.rename(columns = {'gols_visitante': 'gols' }, inplace=True)
df3.rename(columns = {'gols_total' : 'gols' }, inplace=True)
df1['tipo_gols'] = 'gols_mandante'
df2['tipo_gols'] = 'gols_visitante'
df3['tipo_gols'] = 'gols_total'
df4 = pd.concat([df1, df2, df3]).reset_index(drop=True)Com o dataframe pronto será utilizado o método barplot da biblioteca seaborn. Nesse método é indicado as propriedades para os eixos X e Y do gráfico, além da fonte dos dados com a propriedade data. A propriedade hue cria uma legenda para distinguir os valores do gráfico.
Para definir o título do gráfico utilizamos o método title da biblioteca pyplot. Como o seaborn é desenvolvido sobre a biblioteca matplotlib, a relação é feita de forma transparente no gráfico.
### gráfico gols por edição comparativo
sns.barplot(x="torneio", y="gols", hue="tipo_gols", data=df4)
plt.title('Gols do Brasileirão')
plt.show()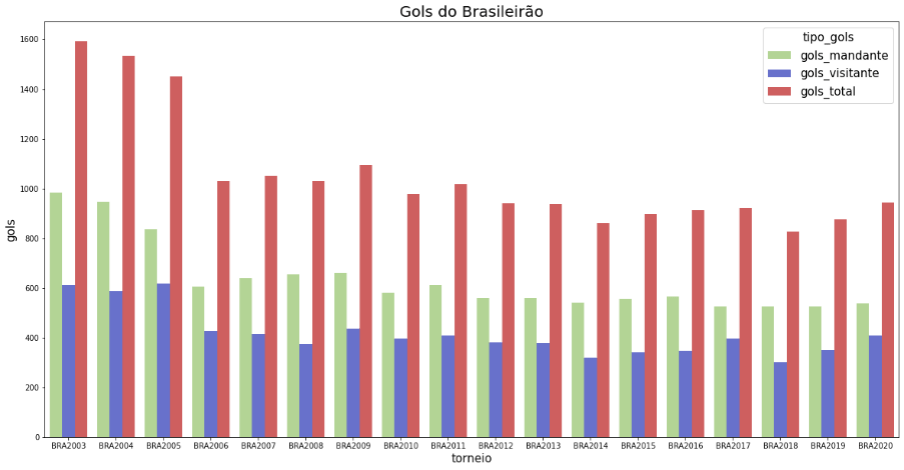
Visualizando o gráfico acima dá para notar que o número de gols_total ficam em torno de 1000. Isso só não acontece nos 3 primeiros anos da série, devido ao maior número de times no campeonato nesse período. Agora vamos ver quais times têm o ataque mais efetivo e que marca mais gols. Nessa análise trazemos o top 10 dos clubes com melhores ataques de todas as edições.
Dados dos Ataques do Brasileirão
Não há novidades em relação ao código. Aqui utilizamos os mandantes e visitantes como agrupador para buscar o totalizador dos gols.
### top 10 clubes gols marcados
gols_mandante_time = df.groupby('mandante' )['mandante placar' ].sum().sort_values(ascending=False).reset_index()
gols_mandante_time.rename(columns = {"mandante" : "time", 'mandante placar' : 'gols marcados' }, inplace=True)
gols_visitante_time = df.groupby('visitante')['visitante placar'].sum().sort_values(ascending=False).reset_index()
gols_visitante_time.rename(columns = {"visitante": "time", 'visitante placar': 'gols marcados' }, inplace=True)
gols_time = pd.concat([gols_mandante_time, gols_visitante_time])
gols_marcados_time = gols_time.groupby('time')['gols marcados'].sum().sort_values(ascending=False).reset_index()
gols_marcados_time.head(10)
Esse é o resultado dos 10 clubes com melhores ataques de todas as edições. Criaremos o gráfico para a análise ficar um pouco mais visual.
### gráfico top 10 clubes gols marcados
sns.barplot(x="gols marcados", y="time", data=gols_marcados_time.head(10))
plt.title('Top 10 Times Gols Marcados do Brasileirão')
plt.show()
Dá para notar um certo equilíbrio nos 10 primeiros times com melhor ataque.
Dados das Defesas do Brasileirão
E se existem os melhores ataques, também devem existir as piores defesas. E nesta análise trazemos os clubes que mais gols levaram em todas as edições analisadas.
### top 10 clubes gols sofridos
gols_mandante_time = df.groupby('visitante')['mandante placar' ].sum().sort_values(ascending=False).reset_index()
gols_mandante_time.rename(columns = {"visitante": "time", 'mandante placar' : 'gols sofridos' }, inplace=True)
gols_visitante_time = df.groupby('mandante' )['visitante placar'].sum().sort_values(ascending=False).reset_index()
gols_visitante_time.rename(columns = {"mandante" : "time", 'visitante placar': 'gols sofridos' }, inplace=True)
gols_time = pd.concat([gols_mandante_time, gols_visitante_time])
gols_sofridos_time = gols_time.groupby('time')['gols sofridos'].sum().sort_values(ascending=False).reset_index()
gols_sofridos_time.head(10)
Como fizemos acima, vamos ver a informação em um gráfico.
### gráfico top 10 clubes gols sofridos
sns.barplot(x="gols sofridos", y="time", data=gols_sofridos_time.head(10))
plt.title('Top 10 Times Gols Sofridos do Brasileirão')
plt.show()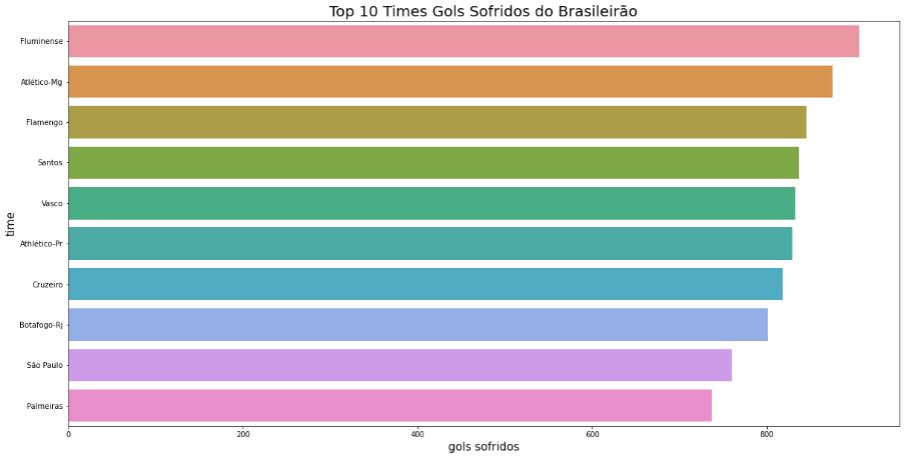
Um ponto a ser observado é que a maioria dos times não disputam todas as edições, devido ao rebaixamento de times. Sendo assim, uma análise que poderia ser feita é a média de gols de cada time (isso vale para Gols Marcados e Sofridos) ao invés da soma total de gols em todas as edições.
Ainda podemos olhar para o melhor ataque do campeonato. Nesta análise mostramos os melhores e piores ataques por edição.
### melhores ataques por edição
df['clube'] = df['mandante']
gols_clubes_mandantes = df.groupby(['torneio','clube'])['mandante placar'].sum().sort_values(ascending=False).reset_index()
gols_clubes_mandantes.rename(columns = {"mandante placar" : "gols_mandante" }, inplace=True)
df['clube'] = df['visitante']
gols_clubes_visitantes = df.groupby(['torneio','clube'])['visitante placar'].sum().sort_values(ascending=False).reset_index()
gols_clubes_visitantes.rename(columns = {"visitante placar": "gols_visitante"}, inplace=True)
gols_clubes = pd.merge(gols_clubes_mandantes, gols_clubes_visitantes, on=["torneio","clube"])
gols_clubes['gols_total'] = gols_clubes['gols_mandante'] + gols_clubes['gols_visitante']
ataque_pior = gols_clubes.groupby('torneio')['gols_total'].min().sort_values(ascending=False).reset_index()
ataque_melhor = gols_clubes.groupby('torneio')['gols_total'].max().sort_values(ascending=False).reset_index()
gols_torneio_ataque_melhor = pd.merge(gols_clubes, ataque_melhor, on=['torneio','gols_total'])[['torneio','clube','gols_total']]
gols_torneio_ataque_melhor.rename(columns = {"gols_total": "ataque_melhor"}, inplace=True)
gols_torneio_ataque_pior = pd.merge(gols_clubes, ataque_pior , on=['torneio','gols_total'])[['torneio','clube','gols_total']]
gols_torneio_ataque_pior.rename(columns = {"gols_total": "ataque_pior" }, inplace=True)
gols_ataques = pd.merge(gols_torneio_ataque_melhor, gols_torneio_ataque_pior, on="torneio", suffixes=("_melhor","_pior"))
gols_ataques.sort_values(['torneio','clube_melhor'])Destaque para o Palmeiras que por três edições seguidas (2016, 2017 e 2018) teve o ataque mais positivo da competição.
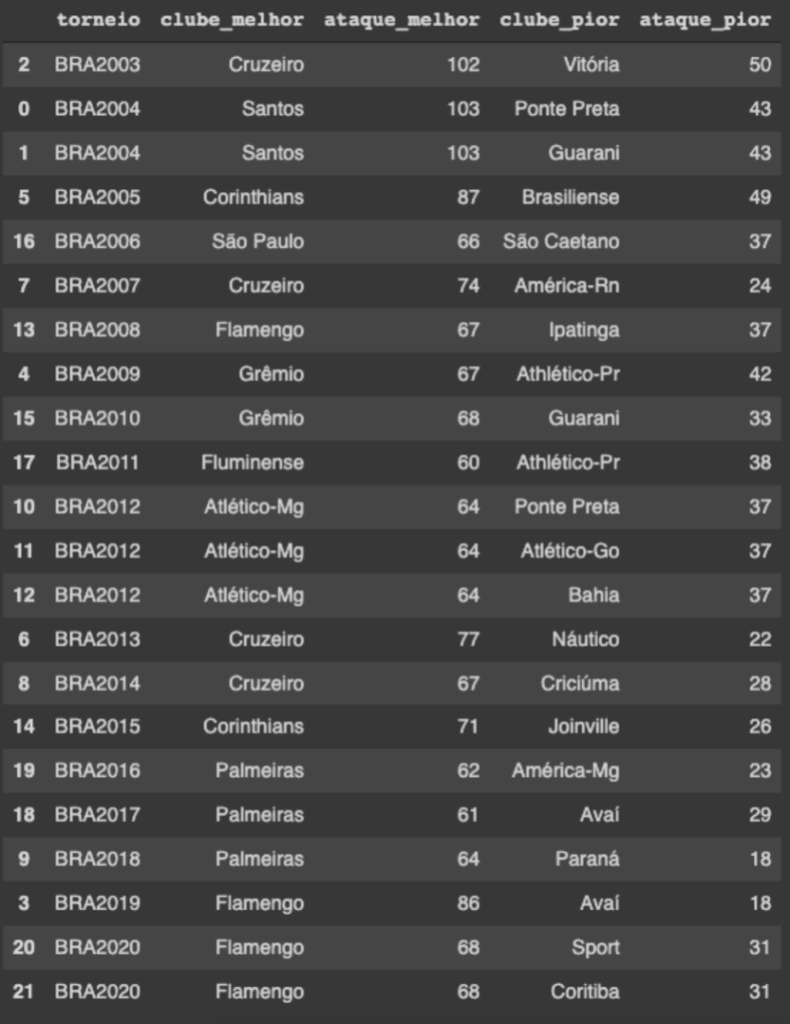
Gols é a essência. É a emoção do futebol. Mas o que adianta fazer gols e não pontuar? A pontuação é a finalidade. Portanto, é com ela que chega-se à glória eterna do título.
Análise de Pontuação do Brasileirão
Para a pontuação faremos uma análise que exibe os clubes com melhor e pior pontuação de todas as edições. Sendo assim, observamos o uso do método nunique. Este método faz a contagem dos registros desconsiderando os valores duplicados.
# pontuação
pontos_participantes = df.groupby('torneio')['mandante'].nunique().sort_values(ascending=False).reset_index()
pontos_participantes['pontos_max'] = (pontos_participantes.mandante - 1)*2*3
pontos = df[['torneio', 'mandante', 'visitante', 'mandante placar', 'visitante placar']]
pontos['pontos_mandante' ] = pontos.apply(lambda x: 3 if x['mandante placar'] > x['visitante placar'] else (0 if x['mandante placar'] < x['visitante placar'] else 1), axis=1)
pontos['pontos_visitante'] = pontos.apply(lambda x: 3 if x['mandante placar'] < x['visitante placar'] else (0 if x['mandante placar'] > x['visitante placar'] else 1), axis=1)
pontos_mandantes = pontos.groupby(['torneio','mandante' ])['pontos_mandante' ].sum().sort_values(ascending=False).reset_index()
pontos_mandantes.rename(columns = {"mandante": "clube" }, inplace=True)
pontos_visitante = pontos.groupby(['torneio','visitante'])['pontos_visitante'].sum().sort_values(ascending=False).reset_index()
pontos_visitante.rename(columns = {"visitante": "clube"}, inplace=True)
pontos_total = pd.merge(pontos_mandantes, pontos_visitante, on=['torneio','clube'])
pontos_total['pontos_total'] = pontos_total.pontos_mandante + pontos_total.pontos_visitanteEntão, chega-se à conclusão que o clube que melhor pontuou foi o Cruzeiro na edição de 2003 chegando aos 100 pontos. E pior clube é o América de Natal com apenas 17 pontos na edição de 2007.
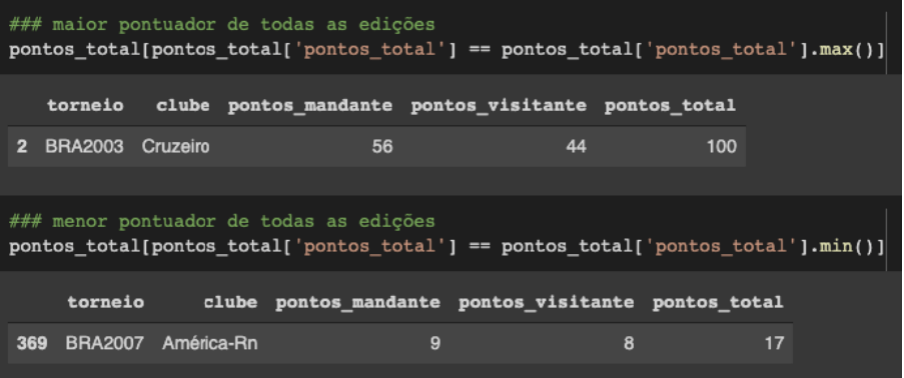
Um outro ponto que podemos entender melhor são os resultados. Quais times têm mais vitórias, derrotas e empates.
Análise de Resultados do Brasileirão
Na análise de resultados é identificado o número de vitórias, empates e derrotas dos clubes que participaram de ao menos uma edição do campeonato de pontos corridos do Brasileirão. Portanto, para definir vitória, derrota ou empate, utilizaram-se os seguintes critérios:
- Se obteve três pontos, considera-se uma vitória;
- Caso conquistou um ponto, considera-se um empate;
- Se não ganhou pontos, considera-se uma derrota.
### número de vitórias, empates e derrotas das equipes
resultado = pontos[['torneio','mandante','visitante','pontos_mandante','pontos_visitante']]
resultado['resultado_mandante' ] = pontos.apply(lambda x: 'Vitória' if x['pontos_mandante' ] == 3 else ('Derrota' if x['pontos_mandante' ] == 0 else 'Empate'), axis=1)
resultado['resultado_visitante'] = pontos.apply(lambda x: 'Vitória' if x['pontos_visitante'] == 3 else ('Derrota' if x['pontos_visitante'] == 0 else 'Empate'), axis=1)
resultado_mandante = resultado.groupby( ['mandante' ,'resultado_mandante' ])['torneio'].count().reset_index()
resultado_mandante.rename(columns = {"mandante": "clube" , "resultado_mandante" :"resultado", "torneio":"ocorrencia"}, inplace=True)
resultado_visitante = resultado.groupby(['visitante','resultado_visitante'])['torneio'].count().reset_index()
resultado_visitante.rename(columns = {"visitante": "clube", "resultado_visitante":"resultado", "torneio":"ocorrencia"}, inplace=True)
resultado = pd.concat([resultado_mandante, resultado_visitante])
resultado = resultado.groupby(['clube','resultado'])['ocorrencia'].sum().reset_index()Ao plotar o resultado da análise no gráfico temos como novidade a definição das cores das barras de forma customizada. Utilizando set_palette em conjunto com color_palette do seaborn.
Destaque também para a propriedade hue_order que define a ordem de exibição dos dados no gráfico, além da propriedade xticks que define a rotação dos labels do eixo X.
### gráfico de vitórias, empates e derrotas das equipes
colors = ["#b2df8a", "#5764db","#e14c4c"]
sns.set_palette(sns.color_palette(colors))
g = sns.barplot(x="clube", y="ocorrencia", hue="resultado", data=resultado, hue_order=['Vitória','Empate','Derrota'])
plt.title('Resultados por Equipe')
plt.xticks(rotation=90)
plt.tight_layout()
A análise por números de vitórias, empates e derrotas destaca os clubes com maiores participações no torneio. Para uma análise mais coerente vamos analisar o aproveitamento de cada clube em suas participações.
Resultados do Brasileirão por Percentual
Aqui, realizamos o cálculo do percentual de vitórias, derrotas e empates para cada clube.
### percentual de resultados por equipe
vit = resultado.query("resultado == 'Vitória'")
emp = resultado.query("resultado == 'Empate'" )
der = resultado.query("resultado == 'Derrota'")
vit.rename(columns = {"ocorrencia": "vitorias"}, inplace=True)
emp.rename(columns = {"ocorrencia": "empates" }, inplace=True)
der.rename(columns = {"ocorrencia": "derrotas"}, inplace=True)
vit = vit[['clube','vitorias']]
emp = emp[['clube','empates']]
der = der[['clube','derrotas']]
rm = pd.merge(vit, emp, on='clube')
ca = pd.merge(rm , der, on='clube')
ca['total'] = ca['vitorias'] + ca['empates'] + ca['derrotas']
ca['perc_vitorias'] = (ca.vitorias / ca.total)*100
ca['perc_empates' ] = (ca.empates / ca.total)*100
ca['perc_derrotas'] = (ca.derrotas / ca.total)*100
ca.head()Então, você pode observar o resultado na lista a seguir.

Temos de novidade a utilização da propriedade suffixes do método merge. Essa propriedade cria sufixos nos atributos dos dataframes na junção. Aqui definimos que os atributos do dataframe da esquerda, percentual, não terá sufixo, porém o da direita, perc_total, terá o sufixo _y.
### gráfico percentual de resultados por equipe
percentual = resultado
perc_total = percentual.groupby(['clube'])['ocorrencia'].sum().reset_index()
percentual = pd.merge(percentual, perc_total, on='clube', suffixes=("","_y") )
percentual.rename(columns = {"ocorrencia_y": "perc"}, inplace=True)
percentual['perc'] = (percentual.ocorrencia / percentual.perc)*
colors = ["#b2df8a", "#5764db","#e14c4c"]
sns.set_palette(sns.color_palette(colors))
g = sns.barplot(x="clube", y="perc", hue="resultado", data=percentual, hue_order=['Vitória','Empate','Derrota'])
plt.title('Percentual dos Resultados por Equipe')
plt.xticks(rotation=90)
plt.tight_layout()Ao plotar a análise no gráfico podemos observar que a distribuição do aproveitamento dos clubes é mais coerente que a análise por número de vitórias, empates e derrotas.

Um fato curioso é que dos 44 times que disputaram o campeonato esses anos, 30 deles tem mais derrotas do que vitórias em seu currículo. Assim podemos dizer que apenas 31,8% dos clubes são mais vitoriosos do que perdedores. O grande número de vitória é o que leva o time à glória, e no final das contas o objetivo de todos os times do campeonato é serem campeões. Veremos quais conclusões podemos fazer sobre os campeões.
Análise de Campeões do Brasileirão
É campeão. É campeão. Quem não gosta de gritar bem alto assim? É o sonho de toda torcida.
E aqui analisamos como os clubes deram esse prazer às suas torcidas em cada edição.
Determinamos os campeões através dos clubes que mais pontuaram em cada torneio. Depois é realizado o merge do dataframe dos campeões com o dataframe de pontos totais para que o novo dataframe de campeões tenha demais dados já analisados.
É calculado o aproveitamento de cada campeão por torneio e extraído o ano do torneio pelo próprio código do torneio. Nesse caso, é utilizado o método extract usando uma expressão regular para retornar apenas números da descrição e depois convertê-los em inteiro com o método astype.
### campeões
campeoes = pontos_total.groupby('torneio')['pontos_total'].max().reset_index()
campeoes.rename(columns = {"pontos_total": "maior_ponto"}, inplace=True)
campeoes = pd.merge(campeoes, pontos_total, left_on=['torneio','maior_ponto'], right_on=['torneio','pontos_total'])
campeoes = pd.merge(campeoes, pontos_participantes, on='torneio')
campeoes['aproveitamento'] = (campeoes.pontos_total / campeoes.pontos_max)*100
campeoes['ano'] = campeoes['torneio'].str.extract('(\d+)').astype(int)
campeoesEntão, você pode observar o resultado na lista a seguir.

Com o dataframe de campeões podemos determinar os campeões com as melhores e piores pontuações. Aqui utilizamos o if else para determinar um atributo de observação quanto a maior e menor pontuação do campeão. Com o if else se a primeira condição for verdadeira (if) será definido o valor para essa condição, caso contrário será definido o valor da condição do else.
### campeões com a maior e menor pontuação
campeoes_pontuacao = campeoes[['torneio', 'clube', 'pontos_total', 'aproveitamento']]
campeoes_pontuacao['maior_ponto'] = campeoes_pontuacao.pontos_total.max()
campeoes_pontuacao['menor_ponto'] = campeoes_pontuacao['pontos_total'].min()
campeoes_pontuacao = campeoes_pontuacao.query('pontos_total == maior_ponto or pontos_total == menor_ponto')
campeoes_pontuacao['observacao'] = campeoes_pontuacao.apply(lambda x: 'Campeão com a maior pontuação' if x['pontos_total'] == x['maior_ponto'] else 'Campeão com a menor pontuação', axis=1)
campeoes_pontuacao = campeoes_pontuacao[['torneio', 'clube', 'pontos_total', 'observacao']]
campeoes_pontuacao
Também com os melhores e piores aproveitamentos.
### campeões com o maior e menor aproveitamento
campeoes_aproveitamento = campeoes[['torneio', 'clube', 'pontos_total', 'aproveitamento']]
campeoes_aproveitamento['maior_aproveitamento'] = campeoes_aproveitamento.aproveitamento.max()
campeoes_aproveitamento['menor_aproveitamento'] = campeoes_aproveitamento['aproveitamento'].min()
campeoes_aproveitamento = campeoes_aproveitamento.query('aproveitamento == maior_aproveitamento or aproveitamento == menor_aproveitamento')
campeoes_aproveitamento['observacao'] = campeoes_aproveitamento.apply(lambda x: 'Campeão com o maior aproveitamento' if x['aproveitamento'] == x['maior_aproveitamento'] else 'Campeão com o menor aproveitamento', axis=1)
campeoes_aproveitamento = campeoes_aproveitamento[['torneio', 'clube', 'aproveitamento', 'observacao']]
campeoes_aproveitamento
E como não poderia faltar, exibimos em gráfico de barras os aproveitamentos dos campeões de cada edição.
Utilizamos a função catplot para essa plotagem. A propriedade kind define o tipo de gráfico a ser plotado. Além disso, utilizamos o método text para adicionar os percentuais na barra de aproveitamento de forma iterativa para uma melhor visualização da informação.
### gráfico de campeões por aproveitamento
campeoes['aprov'] = campeoes.aproveitamento.astype(int)
g = sns.catplot(x='ano',y='aprov', data=campeoes, hue='clube', dodge=False, kind='bar', height=7, aspect=2)
g.set_axis_labels('Ano','Aproveitamento')
g.fig.suptitle('Aproveitamento dos campeões do brasileirão de pontos corridos', ha='center', fontsize=18)
for index, row in campeoes.iterrows():
g.ax.text(row.name, row.aprov, row.aprov, color='black', ha="center")
Apenas nos anos de 2009 e 2019 temos algo um pouco fora da curva, onde registramos o melhor e o pior aproveitamento, fora isso o desempenho dos campeões se mostra bem equilibrado. E então ficamos aqui com as análises.
Dados do Brasileirão ao Cubo
A análise exploratória de dados permite uma infinidade de possibilidades de se obter informações importantes dos dados. Dessa forma, esta é uma etapa muito importante da ciência de dados e que com criatividade irá contribuir bastante para o uso correto dos dados.
A utilização do pandas para manipulação de dados com dataframe é muito poderosa. Aqui foi possível mostrar como é possível realizar a leitura, transformação, junção, cálculos e análises em um conjunto de dados pequenos, mas muito interessante.
Apesar de pequenos os datasets possibilitaram retirar muitas análises legais e com certeza ainda é possível obter muitas informações das mesmas.
Portanto, o limite é a imaginação e com ela podemos ir longe. O notebook completo com essa análise você pode conferir no GitHub, um abraço e até a próxima.
Conteúdos ao Cubo
Vou deixar algumas sugestões de conteúdos anteriores também do Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Storytelling com Dash e Plotly
- ML.Net – Modelos em Produção com WebApi e Docker
- Previsão de Séries Temporais com SKTime
- Classificação com scikit-learn
- Regressão com scikit-learn
- Deletar Dados com Streamlit e o PostgreSQL
- Análise de Dados com Numpy Python
- Pipeline de Dados Airbyte com GA4 e Snowflake
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Analista de Sistemas com Especialização em Business Intelligence e Big Data e graduação em Sistemas de Informação pela Universidade Salvador – Unifacs. É um especialista em dados e tem como principal atuação a área de Business Intelligence envolvendo todos os processos que englobam desde a modelagem dos dados, passando pelo ETL até a apresentação final das informações.

4 Comments
Pedro Anselmo
29 de julho de 2021Muito legal a análise! Essa base de dados é pública? Posso baixá-la e utilizá-la para fazer minhas análises?
Tiago Dias
11 de agosto de 2021Certeza Pedro! Lembra de nós quando compartilhar o conteúdo 🤩
Victor
30 de julho de 2021sensacional
Tiago Dias
11 de agosto de 2021😁