
Fala galera do mundo dos dados! Neste artigo nós iremos realizar uma Análise Exploratória de Dados (EDA) com ML.Net no ambiente WSL *Ubuntu (Linux). Dessa forma, dando prosseguimento com a construção de nosso exemplo de regressão linear para previsão de preços das residências em conjunto com um Dataset do Kaggle.
*É importante frisar que apesar o processo de instalação do ML.Net para usuários nativos do Ubuntu é semelhante ao utilizado no artigo para instalação no ambiente WSL.
Antes de tudo, vimos no artigo anterior criar aplicativos de Machine Learning utilizando C# nunca foi tão fácil!
Caso não tenha visto o artigo anterior sobre ML.Net
Introdução ao ML.Net com Jupyter Notebooks.
Após o anúncio oficial do suporte ao ML.NET para Jupyter notebooks agora tivemos o anúncio do suporte ao novo tipo DataFrame que vem para facilitar a realização de exploração de dados.
Se você já utilizou a biblioteca Pandas em Python na manipulação dados em Jupyter notebooks, você já está familiarizado com o conceito de DataFrame. Em alto nível o DataFrame é uma representação em memória dos dados estruturados.
Configurar o ambiente Ubuntu para a realização de nossa Análise Exploratória de Dados (EDA) com ML.Net
WSL – Windows Subsystem for Linux
O Subsistema do Windows para Linux permite que os desenvolvedores executem um ambiente GNU/Linux, incluindo a maioria das ferramentas de linha de comando, utilitários e aplicativos, diretamente no Windows, sem modificações e sem a sobrecarga de uma máquina virtual tradicional ou da instalação em dualboot.
Todo o processo de instalação é detalhado neste artigo da Microsoft.
Anaconda
O Anaconda é uma distribuição gratuita e de código aberto, que visa simplificar o gerenciamento e a implantação de pacotes. A distribuição inclui pacotes de ciência de dados adequados para Windows, Linux e macOS.
Baixar o Anaconda
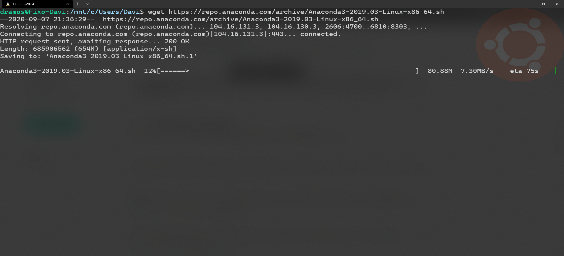
Inicie o seu ambiente WSL e baixe o Anaconda:
wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
Instalando o Anaconda
Em seguida vamos executar o arquivo para instalar o Anaconda:
bash Anaconda3-2020.07-Linux-x86_64.sh
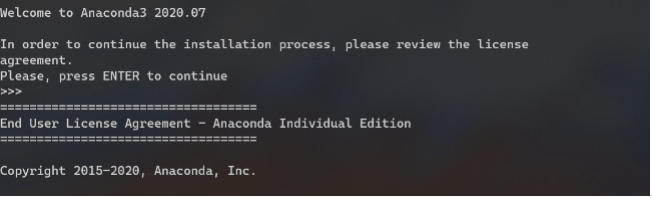
Depois de seguir as instruções na tela para instalar o Anaconda você deve remover o arquivo de instalação:
rm Anaconda3-2020.07-Linux-x86_64.sh
Atualizando o Anaconda
Agora vamos iniciar o ambiente Anaconda:
source ~anaconda3/bin/activate
“~anaconda3/bin/activate” é o local padrão em que o Anaconda irá se instalar, mas se você escolher outro local, simplesmente aponte para esse diretório.
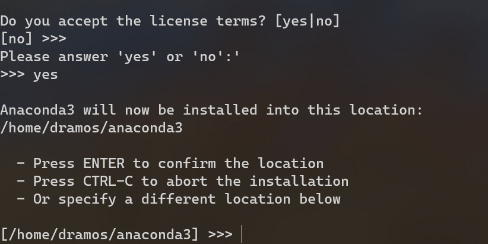
Uma vez que o ambiente esteja ativado nós iremos agora iniciar sua atualização completa:
conda update –all
Você configurou com sucesso o Anaconda 3 para um subsistema Windows para Linux!
Dot Net Core SDK
O SDK do .NET Core é um conjunto de bibliotecas e ferramentas que permitem aos desenvolvedores criar bibliotecas e aplicativos do .NET Core. Sendo assim, Ele contém os seguintes componentes que são usados para criar e executar aplicativos.
Instalando o Dot Net Core SDK no WSL com Ubuntu
Para configurar o SDK em ambiente WSL será necessário instalar:
wget https://packages.microsoft.com/config/ubuntu/20.04/packages-microsoft-prod.deb -O packages-microsoft-prod.deb sudo dpkg -i packages-microsoft-prod.deb sudo apt-get update sudo apt-get install apt-transport-https sudo apt-get update sudo apt-get install dotnet-sdk-3.1
.NET interactive
O .NET interactive é um conjunto de ferramentas CLI e APIs que permitem aos usuários criar experiências interativas em notebooks na web.
Instalando a ferramenta .NET interactive
Para configurar o .NET interactive no ambiente WSL será necessário instalar:
dotnet tool install --global Microsoft.dotnet-interactive dotnet interactive jupyter install
Você poderá verificar a correta instalação da ferramenta executando o seguinte no prompt do Anaconda:
> jupyter kernelspec list .net-csharp ~\jupyter\kernels\.net-csharp .net-fsharp ~\jupyter\kernels\.net-fsharp .net-powershell ~\jupyter\kernels\.net-powershell python3 ~\jupyter\kernels\python3
Então agora que o nosso ambiente está configurado vamos iniciar o nosso estudo
Vamos a Parte Prática com ML.Net
Agora vamos iremos modificar o nosso modelo de regresso linear utilizado para prever os preços das residências usando os seus dados de tamanho e preço.
Instalar os pacotes do NuGet em seu notebook
Antes de escrever qualquer código ML.NET, você precisa que o seu notebook tenha acesso aos pacotes NuGet que você irá utilizar. Nesse caso iremos usar o Microsoft.ML para criar o modelo de Regressão.
//Instalar os Pacotes do Nuget //ML.NET #r "nuget:Microsoft.ML" //ML.NET FastTree #r "nuget:Microsoft.ML.FastTree" //DataFrame #r "nuget:Microsoft.Data.Analysis" //XPlot #r "nuget:XPlot.Plotly,2.0.0"
Agora estamos prontos para adicionar o nosso código, então vamos adicionar as instruções de uso:
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using Microsoft.Data.Analysis; using Microsoft.AspNetCore.Html; using Microsoft.ML.Trainers.FastTree; using System.IO; using System.IO.Compression; using System.Net.Http; using System.Globalization; using XPlot.Plotly; using static Microsoft.ML.TrainCatalogBase; using static Microsoft.ML.DataOperationsCatalog;
Dataset California Housing Prices do Kaggle
Neste artigo iremos utilizar o Dataset do California Housing Prices do Kaggle. Os seus dados contêm informações do censo de 1990 em Califórnia – USA. Sendo assim, ele vai nos ajudar a prever os preços de habitação servindo como um conjunto de dados introdutório para o nosso exemplo de machine learning.
Baixar o Dataset
Aqui está o código para download do Dataset:
if (!File.Exists(housingPath))
{
var contents = new HttpClient()
.GetStringAsync("https://raw.githubusercontent.com/ageron/handson-ml2/master/datasets/housing/housing.csv").Result;
File.WriteAllText(housingPath, contents);
}Formatador Dataframe
Na versão atual a saída padrão do DataFrame não é a mais adequada para ser exibida como uma tabela. Contudo podemos implementar um formatador personalizado. Nós faremos isso conforme demonstrado no código abaixo:
Formatter.Register<DataFrame>((df, writer) =>
{
var headers = new List<IHtmlContent>();
headers.Add(th(i("index")));
headers.AddRange(df.Columns.Select(c => (IHtmlContent) th(c.Name)));
var rows = new List<List<IHtmlContent>>();
var take = 10;
for (var i = 0; i < Math.Min(take, df.Rows.Count); i++)
{
var cells = new List<IHtmlContent>();
cells.Add(td(i));
foreach (var obj in df.Rows[i])
{
cells.Add(td(obj));
} rows.Add(cells);
}
var t = table(
thead(
headers),
tbody(
rows.Select(
r => tr(r))));
writer.Write(t);
}, "text/html");Análise Exploratória de Dados (EDA) com ML.Net
A Análise Exploratória de Dados ou EDA (Exploratory Data Analysis) é uma abordagem utilizada para analisar conjuntos de dados com o intuito resumir suas características principais e extrair informações úteis dos seus dados através de técnicas de visualizações
Munido dessas técnicas o cientista de dados é capaz por exemplo, de entender a natureza dos dados e formular algumas hipóteses sobre as informações que estão a sua disposição.
O DataFrame é um novo tipo introduzido em .Net. Ele é semelhante ao objeto DataFrame do Python, que é usado para manipular dados em notebooks. É uma coleção de colunas contendo dados semelhantes a uma tabela e muito útil na análise de dados tabulares. Tendo suporte para os métodos GroupBy, Sort, Filter, Join/Merge e para o tratamento de valores nulos o que o torna muito útil para a realização de análises.
Então, neste Artigo iremos cobrir seguintes os recursos do objeto DataFrame:
- Carregar um CSV
- Metadados
- Description()
- Info()
- Exibir registros
- Head()
- Sample()
- Tail()
- Filtering
- Grouping
Carregar os dados para o DataFrame
Aqui vamos utilizar o método “LoadCsv” para carregar os dados.
var df = DataFrame.LoadCsv(housingPath);
Visualizar os Registros
Podemos utilizar os métodos: df.Head(5),df.Sample(5) e df.Tail(5) para exibir os registros. Respectivamente estes comandos irão exibir registros do início, aleatórios e do final do arquivo.

Aqui temos as 10 colunas do Dataset dentre elas: Longitude, Latitude, Total_rooms, Total_bedrooms, Median_house_value
Também podemos usar os métodos df.AddPrefix(“HOUSE_”) e df.AddSuffix(“_data“) para adicionar um prefixo ou um sufixo aos nomes da colunas
Exibir as Estatísticas e as informações do tipo
O comando df.Description() exibe as estatísticas do total, máximo, mínimo e média para cada um dos itens em uma coluna do conjunto de dados.

O comando df.Info() exibe informações de tipo para cada coluna do conjunto de dados.

Limpar os dados
O processo de limpeza e preparação dos dados pode representar até 80% do trabalho de um cientista de dados (Dasu e Johnson 2003). Dessa forma, é uma atividade muito importante para a remoção os dados irrelevantes presentes em nosso conjunto de dados. Nesse sentido, os dados podem ser irrelevantes devido a valores ausentes, valores inválidos ou mesmo em razão de outliers.
Para manter este bloco de notas simples usaremos uma das técnicas mais simples que é remoção de valores Nulls. Mas, existem outras técnicas que também poderiam ser aplicadas aos dados com FillNull para preencher valores nulos com outros valores, como a média, moda ou a mediana.
df = df.DropNulls()
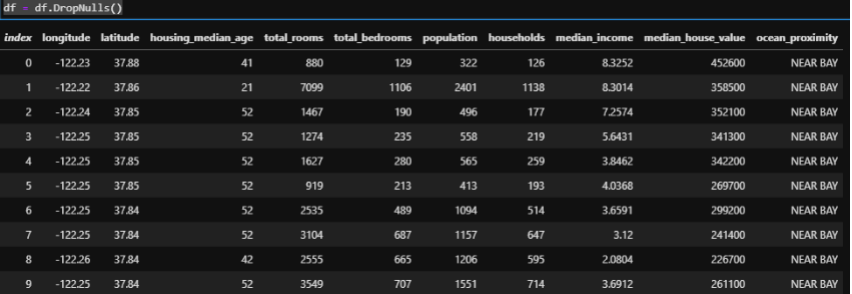
Filtrar os dados
Para filtrar os dados pelos valores das colunas nós podemos utilizar os comandos ElementwiseEquals, ElementwiseGreaterThan, ElementwiseGreaterThanOrEqual, ElementwiseNotEquals, ElementwiseLessThan e ElementwiseLerssThanOrEqual.
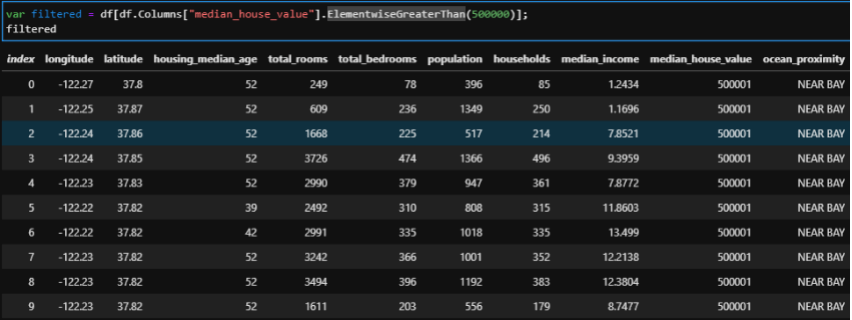
Técnicas de visualização dos dados com XPlot
Para facilitar o estudo do Dataset foram criadas algumas visualizações de acordo com as imagens abaixo:
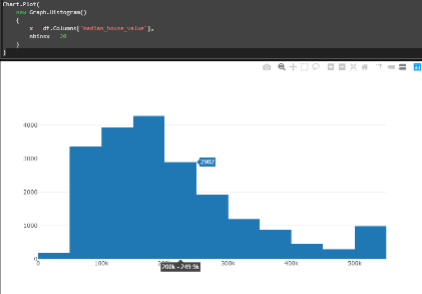
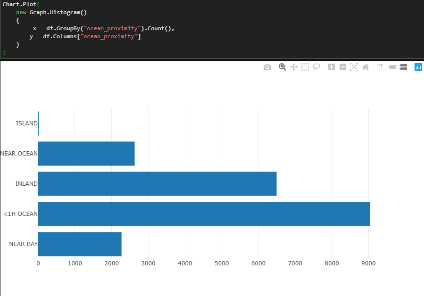
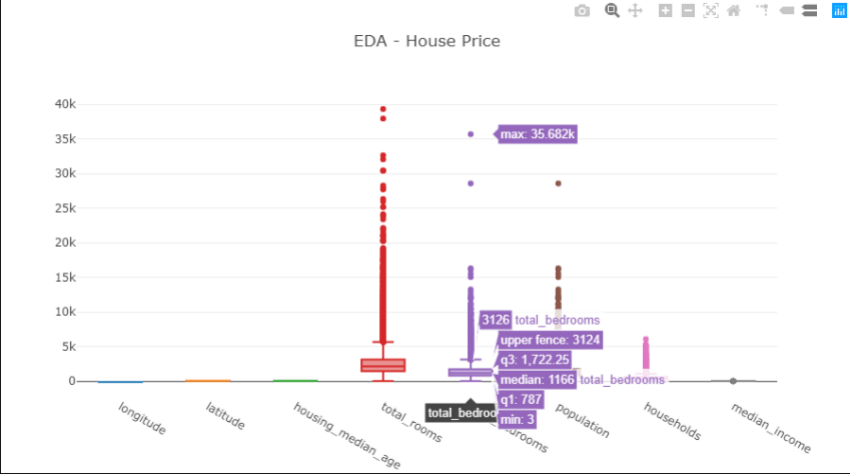
Declarar as classes de dados
Para carregar o conjunto de dados vamos precisar utilizar duas classes uma classe para a entrada de entrada e outra classe para a previsão, serão as classes ModelInput e ModelOutput.
public class ModelInput
{
[LoadColumn(0)]
public float Longitude {get; set;}
[LoadColumn(1)]
public float Latitude {get; set;}
[LoadColumn(2)]
public float Housing_median_age {get; set;}
[LoadColumn(3)]
public float Total_rooms {get; set;}
[LoadColumn(4)]
public float Total_bedrooms {get; set;}
[LoadColumn(5)]
public float Population {get; set;}
[LoadColumn(6)]
public float Households {get; set;}
[public (7)]
public float Median_income {get; set;}
[ColumnName("Label"), LoadColumn(8)]
public float Median_house_value {get; set;}
[LoadColumn(9)]
public string Ocean_proximity {get; set;}
}
public class ModelOutput
{
[ColumnName("Score")]
public float Score {get; set;}
}MLContext, Separação de Dados e Pipeline
A primeira coisa que precisamos fazer é criar um objeto do tipo MLContext, esse é o objeto mais importante do ML.NET, praticamente tudo está ligado a ele. Sendo assim, um aplicativo ML.NET sempre irá iniciar com um objeto MLContext.
MLContext mlContext = new MLContext(seed: 1);
Como nós já vimos possuímos apenas um único dataset. E por isso vamos chamar o método TrainTestSplit() para configurar um set com 80% dos dados para treinamento e os 20% restantes para os testes.
private static IDataView trainingDataView;
private static IDataView testingDataView;
IDataView fullData = mlContext.Data.LoadFromTextFile<ModelInput>(path:
housingPath, hasHeader: true,
separatorChar: ',', allowQuoting: true, allowSparse: false);
DataOperationsCatalog.TrainTestData trainTestData = mlContext.Data.TrainTestSplit(fullData, testFraction: 0.2);
trainingDataView = trainTestData.TrainSet;
testingDataView = trainTestData.TestSet;Em ciência de dados é comum utilizar a divisão 80/20 para dividir os dados em treino e teste para um modelo.
Agora já estamos prontos para começar a construir o modelo de aprendizado de máquina:
Os modelos de aprendizado de máquina em ML.NET são criados como pipelines, que são sequências de componentes de carregamento, transformação e aprendizado de dados.
O nosso pipeline possui os seguintes componentes:
- Um OneHotEncoding para executar um Hot Enconding na coluna que contêm os dados enumerados de Ocean_proximity. Esta é uma etapa necessária porque os modelos de aprendizado de máquina não podem manipular dados enumerados diretamente.
- Concatenate, Combina todas as colunas de dados de entrada em uma única coluna chamada Features. Esta é uma etapa necessária porque o ML.NET pode treinar em uma única coluna de entrada apenas.
- AppendCacheCheckpoint armazena em cache todos os dados na memória para acelerar o processo de treinamento.
- Um algoritmo de regressão que em nosso caso foi o Sdca que irá treinar o modelo para fazer as previsões.
var dataProcessPipeline =
mlContext.Transforms.Categorical.OneHotEncoding(new[]
{ new InputOutputColumnPair("Ocean_proximity", "Ocean_proximity") })
.Append(mlContext.Transforms.Concatenate("Features", new[]
{ "Ocean_proximity","Longitude", "Latitude", "Housing_median_age",
"Total_rooms", "Total_bedrooms", "Population",
"Households", "Median_income" })
.AppendCacheCheckpoint(mlContext));
var trainer = mlContext.Regression.Trainers.Sdca(labelColumnName: "Label", featureColumnName: "Features");
var trainingPipeline = dataProcessPipeline.Append(trainer);Treinar o modelo
O método Fit() treina o modelo com o conjunto de dados de treinamento fornecido. Isso é conhecido como treinamento do modelo. Lembre-se de que o modelo de regressão linear acima tem dois parâmetros de modelo: desvio e peso. Após a chamada a Fit(), os valores dos parâmetros são conhecidos.
var model = trainingPipeline.Fit(trainingDataView);
Usar e Avaliar o Modelo
Agora vamos poder utilizar o modelo treinado para fazer as nossas previsões sobre os novos dados:
IDataView predictions = model.Transform(testingDataView);
var metrics = mlContext.Regression.Evaluate(data:predictions,
labelColumnName:"Label", scoreColumnName: "Score");
PrintRegressionMetrics(metrics);Depois de treinar o nosso modelo precisamos saber o quão bem ele fará as previsões futuras? E com ML.NET você pode avaliar o seu modelo com novos dados de teste.
Cada tipo de tarefa de Machine Learning tem suas métricas utilizadas para avaliar a precisão e a exatidão do modelo em relação ao conjunto de dados de teste.
Para nosso exemplo de preço de residências, iremos usar um Algoritmo de Regressão. Dessa formar para avaliar o modelo vamos adicionar o código abaixo:
public static void PrintRegressionMetrics(RegressionMetrics metrics)
{
Console.WriteLine($"*************************************************");
Console.WriteLine($"* Metrics for Regression model ");
Console.WriteLine($"*------------------------------------------------");
Console.WriteLine($"* LossFn: {metrics.LossFunction:0.##}");
Console.WriteLine($"* R2 Score: {metrics.RSquared:0.##}");
Console.WriteLine($"* Absolute loss: {metrics.MeanAbsoluteError:#.##}");
Console.WriteLine($"* Squared loss: {metrics.MeanSquaredError:#.##}");
Console.WriteLine($"* RMS loss: {metrics.RootMeanSquaredError:#.##}");
Console.WriteLine($"* RMS loss: {metrics.RootMeanSquaredError:#.##}");
Console.WriteLine($"*************************************************");
}Salvar o Modelo
O código abaixo salva o Modelo em disco para que ele possa ser utilizado para previsões futuras sem a necessidade de realização de um novo treinamento:
mlContext.Model.Save(model, trainingDataView.Schema, modelPath);
Console.WriteLine(“O Modelo foi salvo em {0}”, modelPath);
Carregar o Modelo do Disco
O código abaixo carrega o Modelo do disco para que ele possa ser utilizado para nossas previsões:
ITransformer model = mlContext.Model.Load(modelPath, out var modelInputSchema);
var predEngine = mlContext.Model.CreatePredictionEngine <ModelInput,
ModelOutput>(model);Por fim, vamos preencher um objeto do tipo ModelInput() para realizar uma previsão:
ModelInput sampleData = new ModelInput()
{
Longitude = -122.23F,
Latitude = 37.88F,
Housing_median_age = 41F,
Total_rooms = 880F,
Total_bedrooms = 129F,
Population = 322F,
Households = 126F,
Median_income = 8.3252F,
Ocean_proximity = @"NEAR BAY",
};E então, vemos o resultado da previsão:
var resultprediction = predEngine.Predict(sampleData);
Console.WriteLine("Usando o modelo para fazer predição única - Comparando o valor atual de Median_house_value com o valor previsto de para os dados de amostra de Median_house_value ... \n \n");
Console.WriteLine($"Longitude: {sampleData.Longitude}");
Console.WriteLine($"Latitude: {sampleData.Latitude}");
Console.WriteLine($"Housing_median_age: {sampleData.Housing_median_age}");
Console.WriteLine($"Total_rooms: {sampleData.Total_rooms}");
Console.WriteLine($"Total_bedrooms: {sampleData.Total_bedrooms}");
Console.WriteLine($"Population: {sampleData.Population}");
Console.WriteLine($"Households: {sampleData.Households}");
Console.WriteLine($"Median_income: {sampleData.Median_income}");
Console.WriteLine($"Ocean_proximity: {sampleData.Ocean_proximity}");
Console.WriteLine ($"\n \nO Preço previsto para este tamanho é: {resultprediction.Score} \n \n");
Console.WriteLine ("=============== Fim do processo ===============");Código Fonte do projeto de Análise Exploratória com ML.Net
O código do Projeto de exemplo e Análise Exploratória com ML.Net pode ser encontrado no meu github, assim como outros códigos sobre ML.Net.
Análise Exploratória com ML.Net ao Cubo
Neste artigo nós percorremos todo o fluxo de uma Análise Exploratória de Dados (EDA) com ML.Net. Também podemos ver o seu uso em conjunto com um ambiente WSL (Ubuntu), demonstrando assim a capacidade deste framework multiplataforma. Lembre sempre que a Análise Exploratória é uma das etapas mais importantes nos projetos de Dados.
Portanto, no próximo artigo iremos disponibilizar o nosso modelo num aplicativo web.
Referências sobre Análise Exploratória com ML.Net
- Documentação On-Line do ML.NET
- DataFame do ML.Net
- Experimente amostras de notebooks .NET online usando o Binder . Isso também permite que você experimente compilações diárias do .NET Interactive.
- WSL – Windows Subsystem for Linux
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Manipulando Dados em PostgreSQL com Python
- Análise de Dados: Detecção de Fraude de Cartão de Crédito
- Compreendendo Agile BI – Parte I
- Ambiente de Desenvolvimento para Business Intelligence
- Análise Exploratória de Dados com Python Parte I
- Loops em Python
- Análise de Dados Poderosa com Polars em Python
- Deploy do Metabase com Docker
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Mas não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Cientista de Dados especialista em Dados Jurídicos. 📊 Atuando como Data Product Manager na Softplan dedicado a projetos voltados para a aplicação da Ciência de Dados e Inteligência Artificial na área Jurídica. 📚 Atualmente tenho concentrado meus estudos em ML.Net o framework para Data Science da Microsoft.
