

Vamos dar continuidade ao tema de Análise de dados para Detecção de Fraude. Aprofundando em alguns aspectos técnicos importantes, antes do nosso projeto prático. Iremos direcionar a nossa atenção ao fato da fraude ser um evento raro. Logo, podemos esperar que o conjunto de dados seja no mínimo desbalanceado. Então vamos analisar aqui métodos e algoritmos para classes desbalanceadas, que podemos explorar diante deste contexto.
Conjunto de dados
No nosso próximo artigo, iremos trabalhar com o conjunto de dados de detecção de fraude de cartão de crédito. O Credit Card Fraud Detection, disponibilizado no Kaggle. São informações coletadas durante 2 dias, totalizando 284.807 transações, dessas apenas 0,17% foram classificadas como fraude. Trata-se de um conjunto de dados extremamente desbalanceado. Para esse tipo de problema não podemos assumir que todos os erros de classificação sejam equivalentes. Em geral os erros de classificação do tipo falso negativo ou falso positivo, tem um impacto maior no negócio. Em casos de fraude, o falso positivo pode em alguns casos ser pior para o negócio, como grande prejuízo financeiro ou perda de um cliente legítimo. Outro exemplo, em um problema de classificação em que buscamos identificar pacientes com uma determinada doença, o falso negativo pode ser muito pior, pode levar a perda de uma vida. Dependendo do contexto do problema um tipo de erro pode ser pior que outro, busque entender com a área de negócio ou especialista do domínio.
Classes desbalanceadas
A classificação é um problema de aprendizado supervisionado, que busca a partir de um conjunto de exemplos rotulados prever o rótulo para uma nova observação. Os problemas mais comuns referem-se a classificação de duas classes, classificação binária. No nosso problema de classificação binária, teremos a fraude, classe minoritária ou positiva (1) e a não fraude classe majoritária ou negativa (0).
- Classe majoritária: representa o caso comum é chamada de classe negativa, rótulo igual a 0.
- Classe minoritária: representa o caso incomum é chamada de classe positiva, rótulo 1
Em geral, os algoritmos de aprendizado de máquina parte do pressuposto que os dados são balanceados, ou seja, temos uma relação de equilíbrio entre a quantidade de exemplos de cada classe em nosso conjunto de dados. Porém, quando lidamos com eventos incomuns ou para os quais temos poucos registros, precisamos buscar algoritmos que se adaptem a dados desbalanceados. Esse é um dos problemas desafiadores para algoritmos de aprendizado de máquina que pode ser resolvido com Cost-Sensitive Learning.
Aprendizado de Máquina Sensível ao Custo
Conhecido como Cost-Sensitive Learning, trata-se da área do aprendizado de máquina que lida com custos desiguais para realizar previsões. Nesse artigo, vamos nos referir a essa área como Aprendizado de Máquina Sensível ao Custo. O custo se refere a penalidade relacionada a uma previsão errada.
Quando ajustamos um modelo ao conjunto de dados de treinamento, buscamos minimizar o erro, se considerados o custo da classificação correta ou incorreta, podemos otimizar o problema para minimizar o custo total da classificação incorreta (Imbalanced Learning: Foundations, Algorithms, and Applications). Esse é o objetivo do Aprendizado de Máquina Sensível ao Custo.
Podemos atribuir custos diferentes para uma classificação incorreta. Baseada na matriz de confusão, que resume as previsões corretas e incorretas para cada classe, o foco está em atribuir as penalidades para os falsos positivos e falsos negativos. A matriz custo, formulada por Elkan (2001), atribui o custo – C(previsto, real) – de cada equívoco.
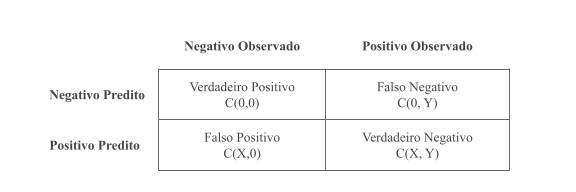
O custo total do classificador pode ser definido a partir da soma ponderada dos custos dos falsos negativos e falsos positivos. Esse será o valor a ser minimizado na modelagem. Os custos atribuídos são críticos para a modelagem, portanto devem ser feitos de forma cuidadosa e alinhada com a área de negócio.
Construir uma matriz de custos, não é uma tarefa simples. Pense em um problema de classificação de diagnóstico de uma doença grave. Qual o custo de um paciente doente não ser tratado? Em outro caso, qual o custo de um usuário detrator nas redes sociais? O cálculo pode se tornar muito complexo, mesmo para especialistas do domínio. Um bom ponto de partida ao lidar com a classificação de dados desbalanceados é usar a distribuição inversa do peso das classes.
Os Métodos de Aprendizado de Máquina Sensível ao Custo definem de forma explícita a penalização dos erros do modelo, a partir das regras de negócio.
Podemos dividir os métodos de aprendizado sensível ao custo em três grupos:
- Reamostragem: pode envolver a reamostragem dos dados de treinamento, ponderando pelo custo de cada classe. Outras abordagens são undersampling (remoção de exemplos da classe majoritária) e oversampling (duplicar ou sintetizar novos exemplos da classe minoritária).
- Algoritmo Sensível ao Custo: algoritmos existentes são alterados, passando a considerar a matriz de custos.
- Métodos Ensemble: combina modelos tradicionais que são modificados e passam a considerar a matriz de custo.
Algoritmos Sensíveis ao Custo

Entre os métodos destacados, iremos nos aprofundar nos Algoritmo Sensível ao Custo (Cost-Sensitive Algorithms). Os algoritmos, em geral, são desenvolvidos para conjuntos de dados balanceados, ou seja, não tem um bom desempenho com dados desbalanceados. Mas podemos ajustar os parâmetros do modelo e trabalharmos com os dados balanceados. Através da biblioteca Scikit-learn de Aprendizado de Máquina do Python, podemos através do parâmetro de ponderação da classe “class_weight”. Modificamos o parâmetro para levar em consideração que os dados são desbalanceados. A ponderação informada para penalizar os erros do modelo.
Os modelos abaixo foram ajustados para considerar dados desbalanceados. Utilizando as funcionalidades do scikit-learn, especificando o hiperparâmetro “class_weight” do modelo. Podemos informar a esse hiperparâmetro o dicionário, onde definimos as respectivas ponderações de cada classe, consideradas ao ajustar o modelo. Os valores considerados para ponderação podem ser definidos junto com a área de negócio, através de experimentações com diferentes opções (grid search) ou a ponderação padrão recomendada (inverso da distribuição de classe dos dados). Essa última opção pode ser especificada diretamente no modelo, definindo o hiperparâmetro como “class_weight=’balanced’”. Com essa definição o modelo busca regularizar as classes minoritárias e realizar a classificação correta.
- Regressão Logística: eficiente para classificação binária, mas por padrão não tem um bom desempenho diante de dados desbalanceados. Ajustando para minimizar a probabilidade de perda, a partir do custo de cada classe. Após o ajuste temos um melhor desempenho do modelo diante dos dados desbalanceados.
- Árvore de Decisão: a divisão da árvore busca separar dois grupos distintos, diante de dados desbalanceados os exemplos da classe minoritária podem ser ignorados. A ponderação das classes busca corrigir esse problema, reduzindo ou aumentando a pontuação de pureza de um nó.
- Random Forest: a amostra via bootstrap pode ter pouca ou nenhuma observação da classe minoritária, prejudicando o desempenho do modelo. Com a ponderação resolvemos a tendenciosidade do modelo no sentido da classe majoritária.
- XGBoost: robusto mesmo diante de dados desbalanceados e oferece o hiperparâmetro específico para ponderação. O hiperparâmetro “scale_pos_weight” ajusta dados desbalanceados.
A divisão do conjunto de dados deve ser de forma aleatória, buscando manter a mesma distribuição de classe em cada subconjunto. Obtemos essa divisão aplicando a amostragem estratificada, tendo a classe como variável controle do processo de estratificação. Dessa forma, cada um dos exemplos da classe minoritária tem oportunidade de está no conjunto de treino e teste. Outro ponto é o uso da validação cruzada, recomendada para trabalhar com dados extremamente desbalanceados, fornece resultados mais confiáveis. Para realizar essa divisão podemos usar a função StratifiedKFold do Scikit-Learn. Com a validação cruzada estratificada, garantimos que todas as amostras possuem dados das duas classes.
Avaliação do modelo

Em um problema com dados desbalanceados a tendência para a classe majoritária pode ser transferida para o modelo. Por exemplo, suponha que em 100 exemplos, temos 1 caso positivo e 99 casos negativos, podemos ter 99% de acurácia apenas classificando tudo como negativo (Harrison, 2019). Sendo assim, para esses casos não olhamos para outras métricas para avaliar o modelo, como a AUC, precisão e recall.
Para a interpretação dos resultados do modelo, podemos usar as curvas ROC e AUPRC (Precision-Recall Curve). Criamos gráficos para cada uma das curvas e calculamos a pontuação média total, para auxiliar na comparação dos modelos. Essas métricas são definidas a partir das células da matriz de confusão.
- Curvas ROC: Gráfico da taxa de falso positivo (x) vs. taxa de verdadeiro positivo (y). Resume o desempenho do modelo de classificação na classe positiva. O melhor modelo será aquele com coordenadas mais próximas de (0, 1) e a pontuação mais próxima de 1.
- Taxa de Falso Positivo = Falso Positivos/ (Falso Positivos + verdadeiro Negativos)
- Taxa de Verdadeiro Positivo = Verdadeiro Positivos / (Verdadeiro Positivos + Falso Negativos)
- AUPRC: Gráfico de recall (x) vs. precisão (y). Suas métricas base estão focadas na classe minoritária. O melhor modelo será aquele com coordenadas mais próximas de (1, 1) e a pontuação mais próxima de 1.
- Precisão = Verdadeiros Positivos/(Verdadeiro Positivo + Falso Positivo).
- Recall = Verdadeiro Positivos/ (Verdadeiro Positivo + Falso Negativos).
As duas métricas respondem bem a problemas com dados desbalanceados, mas para casos extremamente desbalanceados como o que iremos tratar mais a frente, a recomendação é a métrica AUPRC. A métrica ROC pode ser otimista em classificações muito desbalanceadas, onde um número pequeno de classificações corretas ou incorretas pode causar uma grande mudança da curva ou na pontuação. Já a AUPRC possui um foco na classe minoritária, fazendo um diagnóstico mais eficaz diante de dados extremamente desbalanceados.
Agora que já sabemos como podemos trabalhar com a classificação de dados desbalanceados, vamos trabalhar no próximo artigo com um problema de detecção de fraude de cartão de crédito.
Referência
- Machine Learning Pocket Reference – Matt Harrison (2019)
- Cost-Sensitive Learning for Imbalanced Classification
- ROC Curves and Precision-Recall Curves for Imbalanced Classification
- How to Use ROC Curves and Precision-Recall Curves for Classification in Python
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Inteligência Artificial em Ressonância Magnética
- Ciência de Dados para Mercado de Ações Parte I
- Ciência de Dados para Mercado de Ações Parte II
- Profissão: Cientista de Dados Parte I
- Profissão: Cientista de Dados Parte II
- Álgebra Linear com NumPy
- O Guia do XGBoost com Python
- Análise de Dados com Pandas Python
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Uma pessoa curiosa, que gosta de sempre aprender algo novo. Mestra em Demografia, Estaticista, Mestranda em Ciências no momento.
