

Fala galera do mundo dos dados! Se o Descartes dizia, “Penso, logo existo.”, podemos dizer… Pensamos em análise de dados, logo Python existe. Brincadeiras à parte, o Python é a linguagem de programação atualmente mais utilizada para análise de dados. E uma biblioteca que faz toda a diferença nesse universo é o Pandas. Então, nosso assunto de hoje é análise de dados com Pandas Python. Será que dá para fazer muita coisa com esse tal de Pandas? Ou só estamos falando de um bichinho fofo? 🐼? Chega mais e confere aqui o Pandas ao cubo. 🐼🚀🎲3️⃣!!!
A Biblioteca Pandas Python
O Pandas é uma das bibliotecas Python mais populares para análise de dados. Essa ferramenta robusta permite importar, manipular e analisar dados de diversas fontes. Neste post, vamos explorar as principais funções da biblioteca Pandas Python com exemplos de código e explicações detalhadas.
Formatos de Dados da Biblioteca Pandas Python
O Pandas oferece uma estrutura poderosa para lidar com dados tabulares, destacando-se pelas “Series” e “DataFrames”.
Series na Biblioteca Pandas
Uma “Series” é uma estrutura unidimensional que lembra uma coluna em uma planilha ou uma matriz em linguagens tradicionais. Composta por elementos de dados e rótulos de índice associados, as “Series” armazenam e manipulam dados unidimensionais eficientemente, aceitando diversos tipos, como números, texto e datas.
DataFrame na Biblioteca Pandas
O “DataFrame” é a estrela do Pandas, assemelhando-se a uma tabela de banco de dados ou planilha. Cada coluna em um “DataFrame” é uma “Series”, proporcionando um rótulo de índice exclusivo. Ideal para armazenar e analisar dados bidimensionais, o “DataFrame” oferece funcionalidades poderosas para limpeza, transformação, agregação e visualização de dados.
Em resumo, o Pandas fornece um ambiente robusto para trabalhar com dados, permitindo a você organizar, manipular e analisar informações de maneira eficaz. Sendo assim, faremos a importação dos dados nesse formato de dados da biblioteca pandas.
Importando Dados com Pandas Python
A primeira etapa da análise de dados é importar os dados para a sua análise. A biblioteca pandas oferece diversas funções para a importação de dados. Vamos conferir como executar algumas dessas funções.
Como importar a biblioteca Pandas Python?
# Importando a biblioteca pandas import pandas as pd
Depois de importar a biblioteca pandas, faremos a leitura dos dados de diversas fontes. Para isso vamos utilizar a base de dados de exemplo da imagem abaixo. Assim, começamos com o arquivo CSV.
Como ler um arquivo CSV com o Pandas Python?
# Lendo dados de um arquivo CSV
df = pd.read_csv('example.csv', delimiter=';')
df.head(3)Com a utilização da função read_csv, fazemos a importação dos dados e exibimos com a função head conforme a imagem abaixo.

Utilizando o mesmo conjunto de dados porém desta vez no formato xlsx.
Ler arquivo XLSX com o Pandas Python?
# Lendo dados de um arquivo Excel
df = pd.read_excel('example.xlsx')
df.head(3)Agora utilizamos a função read_excel, realizando a importação dos dados e exibindo também com a função head conforme a imagem abaixo.

Para concluir a importação faremos a leitura desses dados a partir de um banco de dados do tipo sqlite. Na imagem abaixo é possível ver o select realizado no banco de dados, apresentando o dataset que será importado.
Fazer leitura de uma tabela do banco de dados SQLITE com o Pandas Python?
# Lendo dados de um banco de dados SQL
import sqlite3
con = sqlite3.connect('example.db')
df = pd.read_sql_query('SELECT * FROM clientes', con)
df.head(3)Aqui primeiramente, criamos a conexão com o sqlite3 e sua função connect e em seguida, utilizamos a função read_sql_query, fazendo a importação dos dados através de uma consulta SQL simples e exibimos mais uma vez com a função head conforme a imagem abaixo.

Agora que já temos os dados importados, veremos algumas funções para fazer a manipulação dos mesmos
Manipulação de Dados com Pandas Python
Após importar os dados, é comum precisar manipulá-los de alguma forma. A biblioteca pandas oferece diversas funções para manipulação de dados. Confere na sequencia, algumas das principais funções para manipulação de dados.
Selecionar somente uma coluna do DataFrame Pandas?
Apenas informando o DataFrame e o nome da coluna.
# Selecionando uma coluna coluna = df['nm_cliente']
Como selecionar várias colunas do DataFrame Pandas?
Aqui informamos o DataFrame e os nomes das colunas.
# Selecionando várias colunas colunas = df[['cd_cliente','nm_cliente']]
Filtrar linhas do DataFrame Pandas?
Para filtrar linhas, informamos o DataFrame com a coluna e a condição de filtro, também é possível fazer de outras formas.
# Filtrando linhas filtrado = df[df['cd_cliente'] > 14]
Como ordenar dados do DataFrame Pandas?
Temos a função sort_values que recebe a coluna para ordenação e o tipo (crescente ou decrescente).
# Ordenando os dados
ordenado = df.sort_values('cd_cliente',ascending=False)Aplicar uma função em uma coluna do DataFrame Pandas?
Para funções temos o método apply, que permite aplicar funções em uma coluna ou em todo o DataFrame.
# Aplicando uma função a uma coluna df['cd_cliente_new'] = df['cd_cliente'].apply(lambda x: x+1000)
Então, manipulações simples de dados apresentadas, podemos dar um passo adiante na análise de dados utilizando pandas.
Análise de Dados com Pandas Python
Uma vez que os dados estejam manipulados, é possível realizar a análise de dados propriamente dita. A biblioteca pandas oferece diversas funções para análise de dados. Portanto, conferimos algumas delas.
Gerar um resumo estatístico com o Pandas com a função describe?
Podemos visualizar um conjunto de métricas estatísticas no DataFrame com a função describe.
# Resumo estatístico dos dados resumo = df.describe()
Realizar uma contagem de ocorrências com o Pandas?
Existe algumas formas para contar ocorrências, uma delas é com o value_counts.
# Contando o número de ocorrências de um valor contagem = df['nm_cliente'].value_counts()
Calcular a correlação entre as colunas com o Pandas?
Dá para calcular a correlações entre as variáveis numéricas do DataFrame através da função corr.
# Calculando a correlação entre colunas correlacao = df.corr()
Realizar agrupamentos de dados com o Pandas?
Também podemos agrupar os dados utilizando a função groupby.
# Agrupando dados
agrupado = df.groupby('cd_cliente').mean()E não pense que para por aí, o pandas permite também criar algumas visualizações de dados simples.
Visualização de Dados com Pandas Python
Por fim, é possível visualizar os dados de forma mais clara e intuitiva. A biblioteca pandas oferece algumas funções para visualização de dados, mas a biblioteca mais comumente utilizada é a matplotlib. Em seguida algumas visualização de dados da biblioteca pandas.
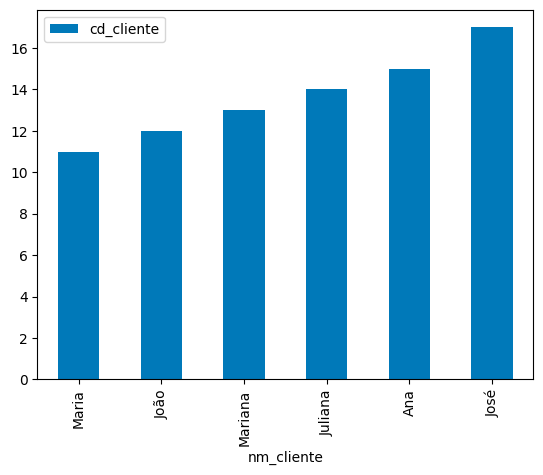
Criar um gráfico de barras com o Pandas?
A função bar, gera um gráfico de barras no Pandas informando as variáveis x e y.
# Gráfico de barras df.plot.bar(x='nm_cliente', y='cd_cliente');
Fazer um gráfico de dispersão com o Pandas?
Aqui usamos a função scatter, para um gráfico de dispersão no Pandas também informando as variáveis x e y.
# Gráfico de dispersão df.plot.scatter(x='cd_cliente', y='cd_cliente_new');
Plotar um gráfico de linha com o Pandas?
Para fechar, o gráfico de linhas com a função line.
# Gráfico de linha df.plot.line(x='nm_cliente', y='cd_cliente')
E assim, temos uma visão geral da análise de dados com Pandas.
Pandas Python ao Cubo
A biblioteca pandas Python é uma ferramenta poderosa para análise de dados. Sendo assim, apresentamos as principais funções da biblioteca pandas com exemplos de código e uma explicação detalhada. Com Pandas, você pode importar, manipular, analisar e visualizar dados de forma eficiente e produtiva. Para mais conteúdo sobre a biblioteca Pandas, confere aqui no Dados ao Cubo a Análise Exploratória de Dados com Python Parte I, Análise Exploratória de Dados com Python Parte II e Manipular Dados no MySQL com Pandas.
E então, está é uma das diversas bibliotecas Python para análise de dados. Na sequência, o Dados ao Cubo trará algumas outras bibliotecas para você que está começando no mundo de análise de dados com Python. Então, fica ligado aqui nas novidades com a nossa Newsletter. Um abraço e até a próxima!!!
Conteúdos ao Cubo
Se você curtiu o conteúdo, aqui no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar. Sempre falando sobre o mundo dos dados!
- Time de Dados na Prática
- Etapas para Análise de Dados
- Tipos de Análise de Dados
- Dicas para Visualização de Dados
- Análise de Dados com Airbyte e Metabase
- Importar CSV no PostgreSQL com o DBeaver
- O Guia do XGBoost com Python
- Como Criar um Chatbot com Rasa Open Source
Portanto, finalizo com um convite para você se tornar um expert em análise de dados seja Parceiro de Publicação Dados ao Cubo e escreva o próximo artigo, compartilhando conhecimento para toda a comunidade de dados.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀

1 Comment
José Hilário Alves Neto
17 de julho de 2023Excelente resumo sobre Pandas