
Fala galera do mundo dos dados! Neste artigo, conheceremos o eXtreme Gradient Boosting (XGBoost) sendo um dos algoritmos de aprendizado de máquina, atualmente, mais populares e poderosos. Desde sua introdução em 2014, o XGBoost tem sido elogiado como o santo graal dos hackathons e competições de aprendizado de máquina.
Portanto, eu sempre recorro ao XGBoost como meu primeiro algoritmo de escolha em qualquer hackathon de Aprendizagem de Máquina (ML). A precisão que ele oferece de forma consistente e o tempo que economiza demonstram o quão útil ele é. Mas, como ele funciona? Qual o seu segredo? Vamos descobrir as respostas para essas perguntas em breve como também, abordaremos uma implementação prática dessa técnica em Python, onde o modelo será aplicado a um problema de classificação do mundo real. Vamos pra cima, pois temos muito a estudar e a codar.
O que é XGBoost ?
O algoritmo XGBoost foi o resultado de um projeto de investigação organizado por Carlos Guestrin e Tianqi Chen na Universidade de Washington. O XGBoost é um algoritmo de aprendizado supervisionado que implementa um processo chamado Boosting para gerar modelos precisos. O aprendizado supervisionado refere-se à tarefa de inferir um modelo preditivo a partir de um conjunto de exemplos de treinamento rotulados, ou seja, o aprendizado supervisionado pode ser considerado como o aprendizado de uma função F(X) = y que rotulará corretamente novas instâncias de entrada.
Cabe relembrar que o aprendizado supervisionado pode ser usado para resolver problemas de classificação ou regressão. Em problemas de classificação, o label y assume um valor discreto (categórico). Por exemplo, podemos desejar prever se um defeito de fabricação ocorre ou não com base em atributos registrados no processo de fabricação, como temperatura ou tempo, representados em X. Em problemas de regressão, o label de destino y assume um valor contínuo. Isso pode ser usado para enquadrar problemas, como prever temperatura ou umidade em um determinado dia.
Como Funciona o XGBoost ?
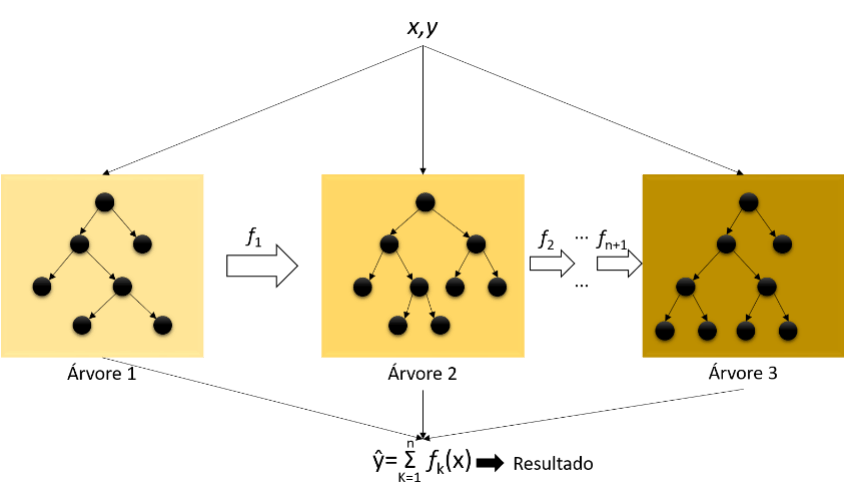
Assim como outros algoritmos de boosting, o XGBoost usa árvores de decisão para seu modelo de conjunto. Cada árvore é um aprendiz fraco. O algoritmo segue construindo sequencialmente mais árvores de decisão, cada uma corrigindo o erro da árvore anterior até que uma condição de parada seja alcançada. Inclui diferentes penalidades de regularização para evitar overfitting onde essas regularizações de penalidade produzem treinamento bem-sucedido para que o modelo possa generalizar adequadamente (Figura 1).
Ademais, cabe destacar que o XGBoost performa muito bem para classificação, mas pode ser aplicado aos problemas de regressão também, para prever os valores de uma variável contínua.
Por fim, o XGBoost foi integrado a uma ampla variedade de outras ferramentas e pacotes, como scikit-learn para entusiastas de Python e caret para usuários de R. Além disso, o XGBoost é integrado a estruturas de processamento distribuído como Apache Spark e Dask.
Vantagens do XGBoost ?
O XGBoost é considerado um dos modelos mais poderosos para dados tabulares para classificação, entretanto pode ser utilizado em uma vasta gama de aplicações para resolver problemas de previsão, ranking, classificação e regressão definidos pelo utilizador.
Além disso, o algoritmo XGBoost é baseado na mesma ideia-chave do Gradient Boosting (melhoria gradual através da introdução de árvores adicionais), mas com algumas melhorias consideráveis.
Por fim, acrescemos também, como principais vantagens:
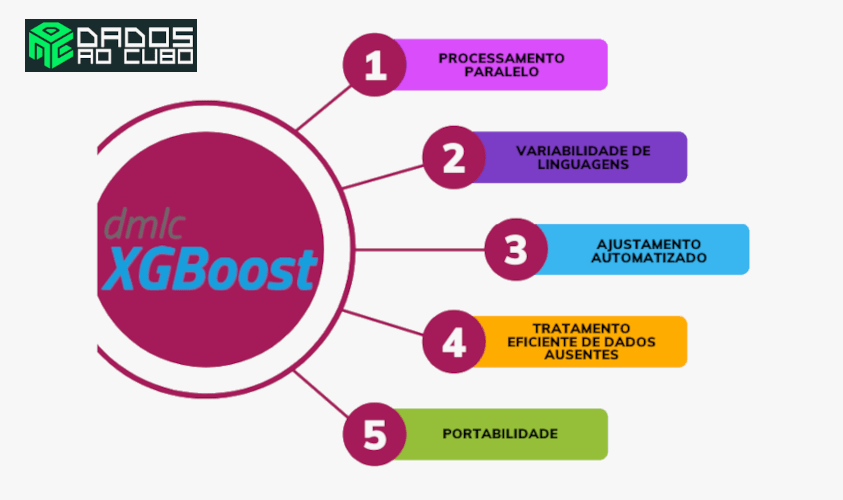
- Portabilidade: funciona em diversos SO.
- Variabilidade de línguas: suporta a maioria das linguagens de programação incluindo, Julia, Scala, Java, R, Python, C++.
- Processamento paralelo: ajuda a reduzir o tempo de treinamento.
- Recursos integrados: permite lidar com os valores ausentes nos dados usados para treinamento e teste.
- Ajustamento automatizado: quando os parâmetros não são ajustados corretamente.
Desvantagens do XGBoost?
E quanto às desvantagens, há algumas características não positivas no uso do algoritmo? Sim, podemos destacar como principais desvantagens:
- Tempo de treinamento maior em comparação com outros modelos de reforço.
- O XGBoost não funciona tão bem em dados esparsos e não estruturados.
- O método geral dificilmente é escalável. Isso ocorre porque os estimadores baseiam sua correção em preditores anteriores, portanto, o procedimento envolve muita dificuldade para simplificar.
- O Gradient Boosting é muito sensível a outliers.
Implementação Prática do XGBoost com Python
Até agora temos um bom entendimento do XGBoost e nesta seção veremos como ele pode ser aplicado a problemas de classificação utilizando o algoritmo XGBClassifier. Sendo assim, nesta implementação, vamos aplicar o classificador XGBoost para resolver o problema de classificação binária onde nossa tarefa é prever se um determinado indivíduo pode ter adquirido diabete ou não. Para isso, estamos considerando um conjunto de dados que contém informações sobre o nível de glicose, pressão sanguínea, espessura da pele, insulina, índice de massa corporal, histórico familiar de diabetes, idade, etc.
Portanto, agora vamos dar os seguintes passos para implementar este problema de classificação binária.
1ª Interação com o XGBoost
Etapa 1 : carregar as bibliotecas iniciais para o desafio
A comunidade ML distribuída desenvolve e mantem o XGBoost. Primeiramente, é preciso instalá-lo utilizando o comando pip conforme código abaixo.
# Instalar o pacote ! pip install xgboost
Carregar as bibliotecas
# carregando as bibliotecas necessárias ao desafio
try:
import pandas as pd
from IPython.core.display import display, HTML
from xgboost import XGBClassifier
# bibliotecas para visualização
import matplotlib.pyplot as plt
import seaborn as sns
display( HTML( '<style>.container { width:100% !important; }</style>') )
# maximiza o número de colunas e linhas para impressão
# quando do uso da função head() do Pandas
pd.options.display.max_columns = 15
pd.options.display.max_rows = 50
# Ignorar warnings
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
print("Bibliotecas carregadas com sucesso!")
except:
print("Problemas ao carregar as bibliotecas!")Bibliotecas carregadas com sucesso!
Etapa 2 : carregar os dados
# carrega base de dados do GitHub (link + '?raw=true')
git_url = "https://github.com/plotly/datasets/blob/master/diabetes.csv?raw=true"
df_diabetes = pd.read_csv(git_url)
# apresenta cabecalho
display(HTML('<h3><b>BASE DE DADOS DIABETES</b></h3><hr/>'))
# CONSTANTES
NUM_POPULACAO = df_diabetes.shape[0]
NUM_ATRIBUTOS = df_diabetes.shape[1]
# carregando 10 amostras aleatórias
display(df_diabetes.head(10))
display(HTML('<hr/><h3><b>População : </b>' +
str(NUM_POPULACAO) +
' | Número de atributos : ' +
str(NUM_ATRIBUTOS) +'</h3>'))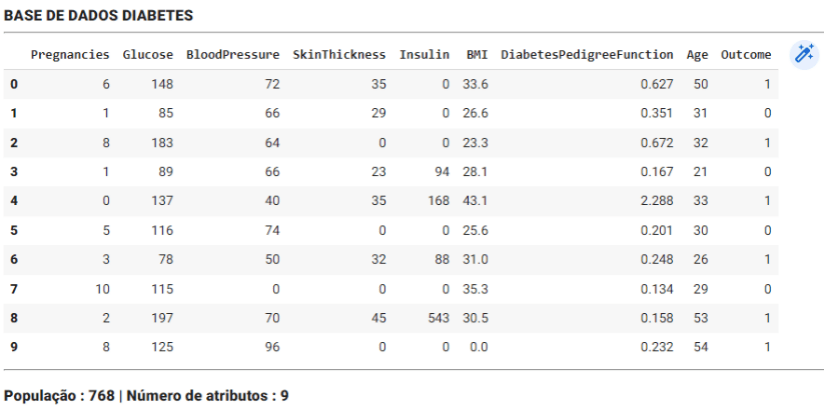
Vamos traduzir as nossas variáveis
# traduzindo toda as colunas
LISTA_ATRIBUTOS_BR = ['gravidez','glicose','pressao_sanguinea',
'espessura_pele','insulina','imc',
'historico_familiar_diabetes',
'idade','resultado']
df_diabetes.columns = LISTA_ATRIBUTOS_BR
df_diabetes.head()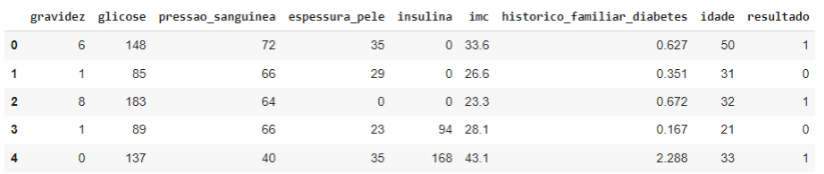
Como vemos, há um total de 9 recursos ou atributos, dos quais os 8 primeiros serão nossos recursos de entrada para o modelo e o último é o recurso de saída ou alvo. Temos um total de 768 registros, posteriormente dividiremos esses registros para fins de treinamento e teste.
Aqui estamos lidando com um problema de classificação. Para isso, devemos verificar como os rótulos das classes estão distribuídos ao longo de 768 registros.
# contagem da classe alvo
contagem = df_diabetes['resultado'].value_counts()
print(f"População sem diabetes: {contagem[0]}")
print(f"População com diabetes: {contagem[1]}")População sem diabetes: 500
População com diabetes: 268
# plotar gráfico de barras para as Classes
sns.countplot('resultado', data=df_diabetes);
print('0 - pacientes sem diabetes | 1 - pacientes com diabtes\n')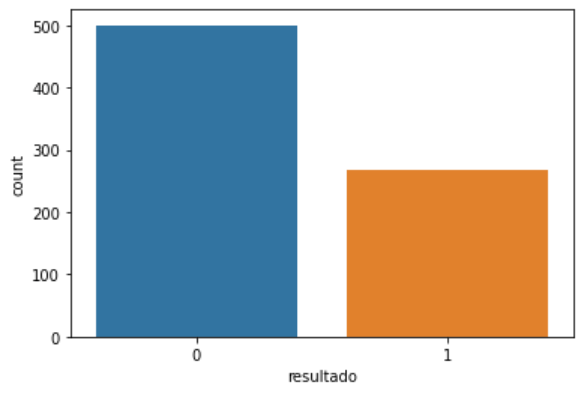
observação : pelos resultados apresentados, podemos constatar que o nosso dataset está desbalanceado.
# porcentagem de cada classe alvo presente
print(f"População sem diabetes: {contagem[0]}")
print(f"População com diabetes: {contagem[1]}")População sem diabetes: 65.1%
População com diabetes: 34.9%
De um total de 768 registros, 500 ou 65,10% registros pertencem à classe 0 (sem diabetes) e 268 ou 34,90% registros pertencem à classe 1 (com diabetes). Como podemos ver, a distribuição das classes é desequilibrada, o que significa que ao fazer previsões há uma grande chance de o resultado estar mais concentrado na classe 0 (sem diabetes). Verificaremos como o classificador se comportará nesse tipo de distribuição de classes quando avaliarmos o modelo no passo X.
Agora vamos avançar com os procedimentos para a construção do modelo.
Etapa 3 : verificar existência de outliers
# plotar um boxplot para analisar presença de outliers no dataset colunas = df_copia.columns.to_list() plt.figure(figsize=(15,8)) df_copia.boxplot(column = colunas[:-1]) plt.show()
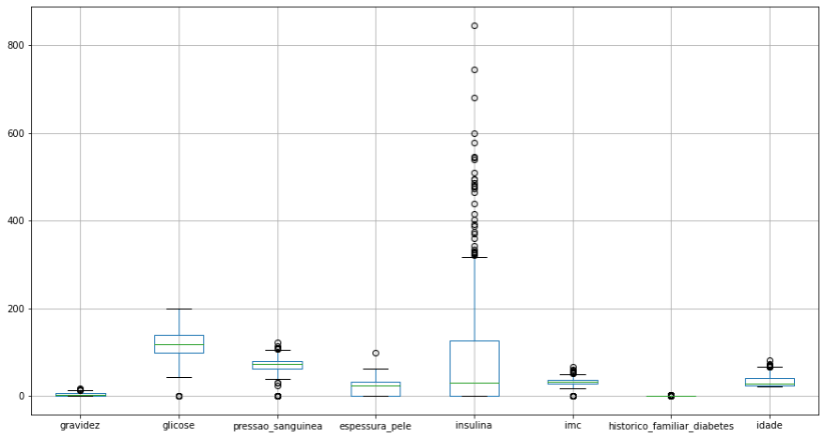
Há possibilidade de outliers, entretanto iremos continuar com o dataset intacto e se for o caso, na próxima iteração removeremos algumas instâncias.
Etapa 4 : carregar os dados
Agora que entendemos e identificamos os recursos, aqui vamos vincular os recursos de entrada à variável X e o recurso de saída à variável y, esta etapa é necessária, pois o modelo recebe os dados na forma X e y.
# tirando uma cópia para preservar o DataFrame original df_copia = df_diabetes.copy() # definindo os recuros de entrada(X) e saida(y) X = df_copia.iloc [: , :-1].values y = df_copia.iloc[ : , -1].values
Após delimitar os dados, vamos agora criar um par de conjuntos de treinamento e teste usando a função train_test_split() da biblioteca SKLearn para usar na fase de treinamento e teste, respectivamente.
# separando os dados de treino e teste
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.30,
shuffle=True,
random_state = 0)
# verificando a dimensão dos dados de treino e teste
print(f'Dados para Treino: {X_train.shape[0]} amostras')
print(f'Dados para Teste: {X_test.shape[0]} amostras')Dados para Treino: 537 amostras
Dados para Teste: 231 amostras
Etapa 5: inicializando e treinando o classificador de aumento de gradiente eXtremely
Aconselho que você visite o site do XGBOOST, previsto na referência, para entender cada parâmetro adotado.
Iniciando o modelo e o seu treinamento.
clf = XGBClassifier(n_estimators = 650,
max_depth = 10,
learning_rate = 0.01,
subsample = 1,
random_state=0)
# Training the XGB classifier
clf.fit(X_train, y_train)XGBClassifier(learning_rate=0.01, max_depth=10, n_estimators=650)
Etapa 6: prevendo e avaliando o classificador
Após treinar com sucesso o classificador nesta seção, primeiro faremos as previsões nos dados de teste para compararmos a previsão com os dados reais.
# fazendo a predição com os dados de teste
y_pred = clf.predict(X_test)
# Cobinando os valores encontrados com os valores atuais
pd.DataFrame(data={'Rótulo Atual': y_test, 'Rótulo Predito': y_pred}).head()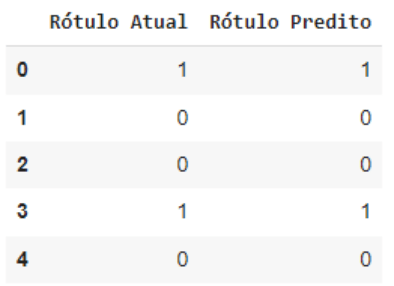
A partir da comparação acima, cada rótulo real está sendo previsto com precisão, mas pode haver alguns casos em que o modelo fez previsões imprecisas. Vamos revelar tudo isso usando a matriz de confusão.
Lembrando que a matriz de confusão é uma tabela que representa os acertos e erros de uma classificação. Dessa forma, com os resultado obtidos é possível fazer cálculos de desempenho.
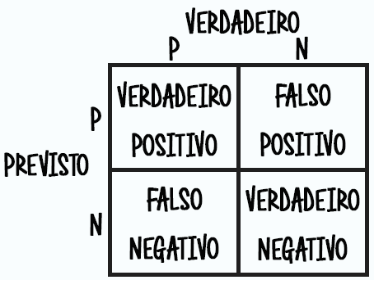
# apresentando os resultados pela Matriz de COnfusão from sklearn.metrics import plot_confusion_matrix plot_confusion_matrix(clf, X_test, y_test, cmap='Blues')
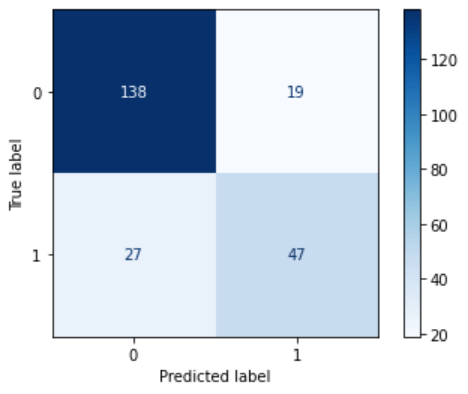
Agora vamos obter a precisão do teste do classificador.
# Score da Acurácia
from sklearn.metrics import accuracy_score
print(f'Precisão do modelo: {round(accuracy_score(y_test, y_pred)*100,3)}%')Precisão do modelo: 80.087%
Para a avaliação final do classificador vamos usar o relatório de classificação que avalia o modelo em vários parâmetros, e observando a pontuação podemos concluir o desempenho do modelo.
# Relatório da Classificação from sklearn.metrics import classification_report print(classification_report(y_test, y_pred))
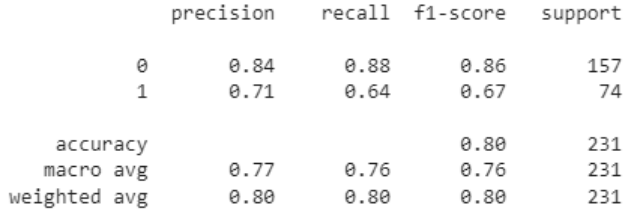
Na primeira iteração, trabalhamos com a distribuição das classes desequilibrada o que poderia nos levar a pensar que a previsão se concentraria no rótulo da classe 0 (sem diabetes). Mas, pelo relatório de classificação acima, podemos dizer que o classificador XGBoost lidou bem com o conjunto de dados desequilibrado. Entretanto, a acurácia não foi muito satisfatória.
2ª Interação com o XGBoost
Nessa 2ª Iteração, iremos balancear o nosso dataset para verificar se haverá melhora na acurácia do modelo XGBClassifier. Nesse balanceamento, iremos adotar a técnica de oversampling.
# instala a biblioteca para balanceamento ! pip install imbalanced-learn # carrega a bibliotecas necessárias para a 2ª iteração from imblearn.over_sampling import SMOTE from collections import Counter
Ambiente, preparado! Agora é partir para o balanceamento.
# executa o balanceamento usando a técnica SMOTE oversample = SMOTE() X, y = oversample.fit_resample(X, y) # realiza a contagem das classes contagem = Counter(y) print(contagem)
Counter({1: 500, 0: 500})
Agora que nossas classes estão balanceadas, vamos separar o nosso conjunto de treinamento e testes (manteremos a proporção da iteração 1).
# separando os dados de treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.30,
shuffle=True,
random_state = 0)Separado os nossos dados, iremos criar o nosso novo modelo.
clf2 = XGBClassifier(n_estimators = 650,
max_depth = 10,
learning_rate = 0.01,
subsample = 1,
random_state=0)
# Training the XGB classifier
clf2.fit(X_train, y_train)XGBClassifier(learning_rate=0.01, max_depth=10, n_estimators=650)
Modelo criado, passaremos a treinar o modelo.
# fazendo a predição com os dados de teste
y_pred = clf2.predict(X_test)
# Cobinando os valores encontrados com os valores atuais
pd.DataFrame(data={'Rótulo Atual': y_test, 'Rótulo Predito': y_pred}).head()
Modelo treinado, agora iremos ver como o nosso modelo está performando. Para isso, usaremos a matriz de confusão novamente, e iremos plotar um relatório com o resultado das principais métricas.
# apresentando os resultados pela Matriz de Confusão from sklearn.metrics import plot_confusion_matrix plot_confusion_matrix(clf2, X_test, y_test, cmap='Blues')
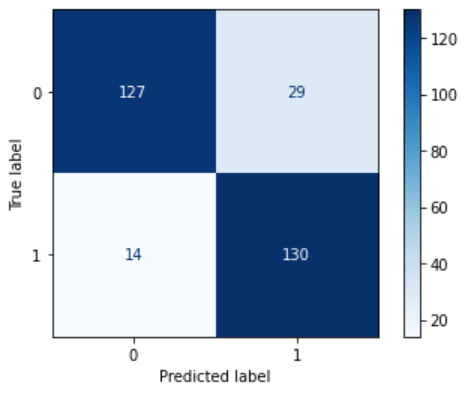
# Score da Acurácia
from sklearn.metrics import accuracy_score
print(f'Precisão do modelo : {round(accuracy_score(y_test, y_pred)*100,3)}%')Precisão do modelo : 85.0%
# Relatório da Classificação from sklearn.metrics import classification_report print(classification_report(y_test, y_pred))
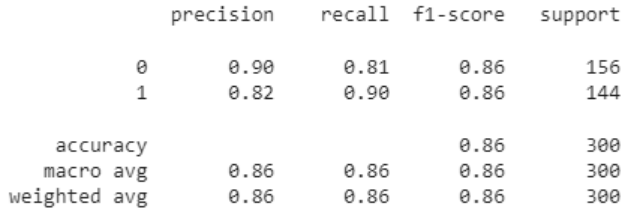
Na segunda iteração, com as classes balanceadas, pudemos atestar, pelos resultados apresentados, uma melhora na acurácia do modelo, saindo dos 80,087% para 85.0%. Portanto, atingimos o objetivo.
XGBoost ao Cubo
Cobrimos, ao longo deste post, alguns aspectos do XGBoost, começando de um ponto de vista teórico até um caminho mais prático com a aplicação do algoritmo XGBClassifier em Python.
Como desafio, acredito que vale a pena realizar uma 3ª iteração para aplicar a técnica de oversampling com a remoção dos possíveis outliers, com o propósito de analisar a acurácia do novo modelo gerado.
Muito grato pela sua leitura, espero que tenham gostado e nos vemos num próximo post.
Como sempre, deixarei algumas referências úteis abaixo, para que você possa expandir ainda mais seu conhecimento e melhorar suas habilidades de codificação.
Referências
- Chen, T. & Guestrin, C. (2016), XGBoost: A Scalable Tree Boosting System., in Balaji Krishnapuram; Mohak Shah; Alexander J. Smola; Charu Aggarwal; Dou Shen & Rajeev Rastogi, ed., ‘KDD’ , ACM, , pp. 785-794 .
- Jerome H. Friedman. “Greedy function approximation: A gradient boosting machine..” Ann. Statist. 29 (5) 1189 – 1232, October 2001. https://doi.org/10.1214/aos/1013203451
- Google Cloud. Al Plataform- Visão geral do ajuste de hiperparâmetro. https://cloud.google.com/ml-engine/docs/hyperparameter-tuning-overview?hl=pt-br. Acessado em 18 de abril de 2022.
- Introdução ao XGBOOST como uma implementação em um aplicativo iOS. https://heartbeat.fritz.ai/introduction-to-xgboost-with-an-implementation-in-an-ios-application-cdfaa8f9930b. Acessado em 20 de abril de 2022.
- MORDE, V. and SETTY, Anurag. XGBoost Algorithm: Long May She Reign. https://www.kdnuggets.com/2019/05/xgboost-algorithm.html. Acessado em 22 de abril de 2022.
Conteúdos ao Cubo
Se curtiu, lá no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar por lá, sempre falando sobre o mundo dos dados.
- Linguagem de Programação Python do Zero
- Manipulando Dados em PostgreSQL com Python
- Análise Exploratória de Dados com Python Parte I
- Modelos em Produção com Streamlit
- Classificação com scikit-learn
- Métodos de Classificação para Classes Desbalanceadas
- Visualização de Dados com Seaborn Python
- Tableau + Python = PyGWalker
Para finalizar, se torne também Parceiro de Publicação Dados ao Cubo. Escreva o próximo artigo e compartilhe conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Oficial do Exército Brasileiro e um aficionado por Ciência de Dados. Mestrando em Governança, Tecnologia e Inovação pela UCB; Pós-graduado em Ciências Militares, Bases Geo-Históricas, Educação a Distância, Engenharia de Sistemas, Ciência de Dados e Inteligência Artificial; possui MBA Gestão de Projetos e MBA Gestão Imobiliária; possuidor das seguintes certificações SAAC™, Kanban-ASC™, SFPC™, SFC™, SMC™, DEPC, ISPA Netowork e ISPA Linux.
