

Fala galera! Todo mundo bem? Dando continuidade a um tema muito importante no mundo dos dados, falaremos hoje mais um pouco sobre Análise Exploratória de Dados com Python. Aqui no Dados ao Cubo já abordamos alguns conceitos importantes sobre o assunto, quando falamos de Estatística Descritiva Univariada e na Análise Exploratória de Dados com Python Parte I. Então, não perca tempo, dê uma lida nesses conceitos por que hoje é só código Python!!!
Para recapitular, o objetivo da Análise Exploratória dos Dados é fazer uma descoberta nos dados. Dessa forma, é possível identificar problemas nos dados ou obter insights. O Python possui um conjunto de bibliotecas prontas para realizar essa atividade.
Vamos ver algumas funções das bibliotecas Pandas, Matplotlib e Seaborn. Sobre o Pandas, é uma biblioteca bastante conhecida e de fácil manipulação, com ela é possível manipular e analisar os dados. Já as bibliotecas Matplotlib e Seaborn são ferramentas gráficas para visualização de dados.
Aqui, vamos fazer a manipulação e análise dos dados de um dataset de vendas, onde temos informações dos anos 2008 e 2009. Os dados estão disponíveis no meu GitHub. Let’s Code ao Cubo!!!
Obtendo os Dados
Para começar a brincadeira da análise exploratória dos dados com Python vamos fazer a ingestão de dados. Então, vamos importar a biblioteca Pandas para isso. Iremos aproveitar e fazer o import das bibliotecas gráficas Matplotlib e Seaborn que vamos precisar mais a frente.
# Importando bibliotecas import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
Com as bibliotecas importadas, vamos usar a função read_excel e ler os dados diretamente do repositório do GitHub de um arquivo .xlsx, como podemos ver abaixo.
# Criaando um dataframe com um arquivo excel
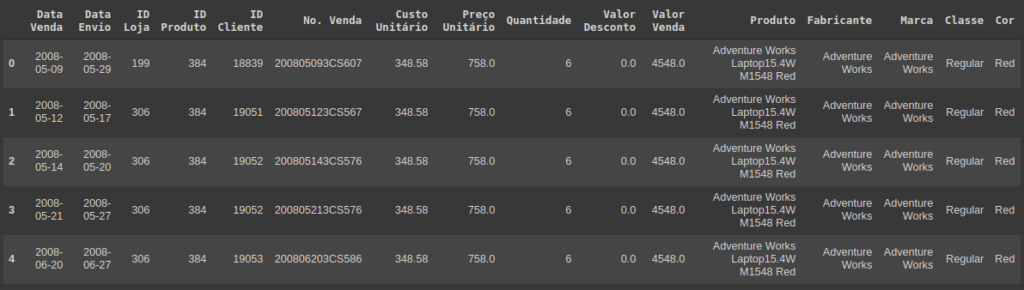
df = pd.read_excel('https://github.com/diasctiago/dio/blob/main/An%C3%A1lise%20de%20dados%20com%20Python%20e%20Pandas/AdventureWorks.xlsx?raw=true')Dados carregados, podemos visualizar os primeiros registros para garantir que deu tudo certo. Para isso vamos usar a função head.
# Exibindo os primeiros registros df.head()
Agora podemos iniciar a diversão!!! E para começar faremos uma análise da estrutura dos dados que acabamos de fazer a ingestão.
Análise da Estrutura dos Dados
Para iniciar o entendimento dos dados, iremos fazer uma verificação na estrutura dos dados carregados. Dessa forma é possível analisar os tipos de dados, o tamanho do dataset, os dados nulos entre outras validações.
O primeiro ponto de verificação é identificar as colunas carregadas, para isso usamos a função columns do pandas.
# Verificando as colunas do dataset df.columns

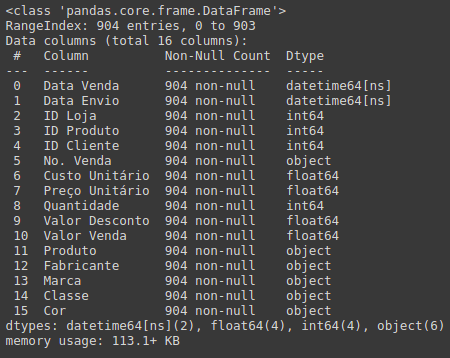
Em seguida iremos consultar os detalhes do data frame, com a função info. Aqui temos muitas informações importantes, como colunas com os tipos de dados, o range do index e a quantidade de memória utilizada.
# Consultando detalhes do dataframe df.info()
Depois uma checagem do tamanho do conjunto de dados. A função shape vai retornar a quantidade de linhas e colunas.
# Tamanho do dataset df.shape (904, 16)
Podemos exibir de uma forma mais amigável, podemos utilizar o código abaixo.
print('O dataset possui',df.shape[0], 'registros e', df.shape[1], 'atributos.')
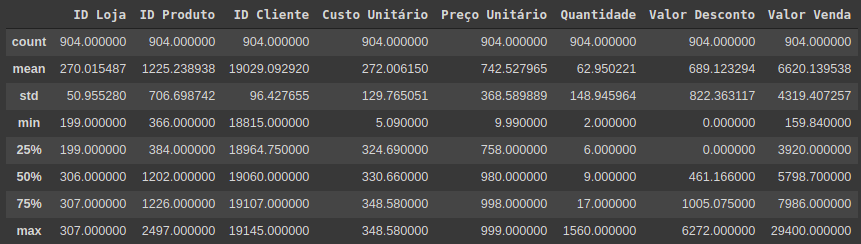
O dataset possui 904 registros e 16 atributos.Continuamos com a função describe, exibindo algumas informações estatísticas básicas das colunas numéricas.
# Descrição estatística básica das variáveis numéricas df.describe()
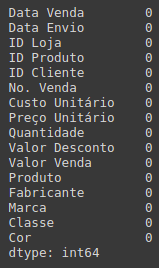
E para finalizar essa primeira etapa uma verificação dos dados nulos. Utilizando a função isna para identificar os nulos e a sum para somar a quantidade de nulos de cada coluna.
# Verificando dados nulos df.isna().sum()
Com a estrutura dos dados conhecida, podemos pensar em como enriquecer esses dados. No nosso caso, criaremos novas colunas com cálculos baseados nas colunas existentes. Mas é possível fazer outros tipos de enriquecimento, como adicionar dados externos que gerem valor ao negócio.
Análise para Enriquecimento dos Dados
Com todos os atributos que vimos acima referente às vendas dos produtos, podemos identificar novos atributos que vão enriquecer a nossa exploração dos dados. Criaremos algumas novas colunas no dataset com base nas colunas existentes.
A primeira coluna é o cálculo de dias de envio, baseada na diferença da data de envio e data da compra.
# Dias de envio da compra df['Dias de Envio'] = df['Data Envio'] - df['Data Venda']
Uma outra informação que podemos ter é o custo total. O cálculo será o produto do custo unitário com a quantidade.
# Custo total do produto df['Custo Total'] = df['Custo Unitário'] * df['Quantidade']
Se temos o valor da venda e o custo logo, pensamos em lucro. Então, faremos o cálculo com a diferença entre a venda e o custo. Assim chegamos no lucro bruto.
# Lucro bruto da venda df['Lucro Bruto'] = df['Valor Venda'] - df['Custo Total']
Refinando o cálculo do lucro, vamos subtrair do lucro bruto o valor do desconto. Sendo assim, temos o lucro líquido.
# Lucro líquido da venda df['Lucro Líquido'] = df['Lucro Bruto'] - df['Valor Desconto']
Com as colunas de lucros criadas vamos ver o percentual de lucro bruto sobre o custo.
# Percentual do Lucro bruto da venda df['% Lucro Bruto'] = ( 1 - ( df['Custo Total'] / df['Valor Venda'] ) ) * 100
Finalizando com o percentual de lucro líquido.
# Percentual do Lucro líquido da venda df['% Lucro Líquido'] = ( 1 - ( df['Custo Total'] / ( df['Valor Venda'] - df['Valor Desconto'] ) ) )*100
Agora que já conhecemos a estrutura e enriquecemos os dados, vamos a uma análise de negócio. Assim será possível ver se os dados são capazes de resolver as dores do negócio.
Análise para o Negócio
Se os dados não resolver problemas do negócio, eles não estão sendo coletados corretamente ou estamos olhando para os dados errados. Sendo assim, os dados precisam conseguir responder algumas dúvidas do negócio. Então, vamos criar algumas perguntas sobre os dados que estamos explorando. Dessa forma, conseguimos gerar valor para o negócio com a análise exploratória dos dados com Python.
Quais são os produtos?
Aqui vamos fazer uma contagem de produtos em cada venda. Dessa forma podemos observar o produto que esteve no maior número de vendas, mas será que ele é o produto mais vendido?
# Contagem de venda por produto df['Produto'].value_counts() Adventure Works Laptop15.4W M1548 Black 123 Fabrikam Trendsetter 2/3'' 17mm X100 Grey 118 Adventure Works Laptop15.4W M1548 Red 115 Fabrikam Trendsetter 2/3'' 17mm X100 Black 103 Fabrikam Trendsetter 1/3'' 8.5mm X200 Grey 94 Fabrikam Trendsetter 1/3'' 8.5mm X200 White 90 Fabrikam Trendsetter 1/3'' 8.5mm X200 Black 89 Headphone Adapter for Contoso Phone E130 Silver 87 Headphone Adapter for Contoso Phone E130 White 85 Name: Produto, dtype: int64
Então, fazendo uma análise de acordo com a quantidade vendida é possível responder a pergunta acima do produto mais vendido. Observe como a análise e a exploração dos dados é importante para ter as respostas certas.
# Contagem de produtos vendidos
df.groupby('Produto')['Quantidade'].sum().sort_values(ascending=False)
Produto
Headphone Adapter for Contoso Phone E130 Silver 25232
Headphone Adapter for Contoso Phone E130 White 25008
Adventure Works Laptop15.4W M1548 Black 1089
Fabrikam Trendsetter 2/3'' 17mm X100 Grey 1087
Adventure Works Laptop15.4W M1548 Red 1047
Fabrikam Trendsetter 2/3'' 17mm X100 Black 926
Fabrikam Trendsetter 1/3'' 8.5mm X200 Black 884
Fabrikam Trendsetter 1/3'' 8.5mm X200 Grey 845
Fabrikam Trendsetter 1/3'' 8.5mm X200 White 789
Name: Quantidade, dtype: int64Quais são as lojas? E quantas lojas?
Agora, vamos verificar as lojas presentes nas vendas. Podemos utilizar a função unique para obter essa informação.
# Lojas únicas df['ID Loja'].unique() array([199, 306, 307])
Já para contar a quantidade podemos acrescentar a função len no código acima. Com apenas 3 podemos contar rapidamente apenas olhando, mas no caso de muitas lojas dificultaria a contagem.
# Quantidade de lojas únicas len(df['ID Loja'].unique()) 3
Qual a primeira e última data de venda?
Para identificar a menor e a maior data da venda, iremos usar a função min e max. Dessa forma podemos de forma rápida identificar o período do nosso conjunto de dados.
# Menor data no conjuto de dados
df['Data Venda'].min()
Timestamp('2008-01-02 00:00:00')
# Maior data no conjuto de dados
df['Data Venda'].max()
Timestamp('2009-12-31 00:00:00')Quais os valores médios por produto?
Falando de valores médios temos a função mean que se utilizada em conjunto com a função groupby podemos fazer a agregação dos dados (No exemplo abaixo pela coluna Produto). Então, escolhemos algumas colunas e colocamos na variável valores para simplificar o código. Vejamos abaixo.
# Agrupamento dos valores médios por produtos
valores = ['Produto', 'Valor Desconto', 'Valor Venda',
'Custo Total', 'Lucro Bruto', 'Lucro Líquido',
'% Lucro Bruto', '% Lucro Líquido']
df[valores].groupby(['Produto']).mean()Quais os valores totais?
Finalizando as perguntas sobre os dados, iremos verificar a soma total de algumas variáveis. Assim, criamos as 5 variáveis que vamos ver no código abaixo.
# Somando os valores totais total_descontos = df['Valor Desconto'].sum() total_vendas = df['Valor Venda'].sum() total_custos = df['Custo Total'].sum() total_lucro_bruto = df['Lucro Bruto'].sum() total_lucro_liquido = df['Lucro Líquido'].sum()
Para exibir os valores formatados importamos a biblioteca locate e utilizamos a função currency. Veja os detalhes no código abaixo.
# Usando a função currency da biblioteca locale para formatar o valor
import locale
locale.setlocale(locale.LC_MONETARY, 'en_US.UTF-8')
# Mostrando os valores totais
print('Total de descontos foi ---->',locale.currency(total_descontos))
print('Total de vendas foi ------->',locale.currency(total_vendas))
print('Total de custos foi ------->',locale.currency(total_custos))
print('Lucro bruto foi ----------->',locale.currency(total_lucro_bruto))
print('Lucro líquido foi --------->',locale.currency(total_lucro_liquido))
Total de descontos foi ----> $622967.46
Total de vendas foi -------> $5984606.14
Total de custos foi -------> $2486783.05
Lucro bruto foi -----------> $3497823.09
Lucro líquido foi ---------> $2874855.64E para complementar a análise de negócio, vamos à análise gráfica dos dados. Assim podemos ver de forma visual o resultado da análise exploratória de dados.
Análise Gráfica dos Dados
Nada mais claro para entender os dados e gerar insights do que visualizações gráficas. Então vamos criar alguns gráficos para continuar a nossa análise exploratória dos dados com Python. Agora as bibliotecas gráficas do Python vão ser muito úteis. Aqui vamos utilizar a Matplotlib e Seaborn que importamos lá no início do código.
Antes de começar criar os gráficos vamos fazer uma configuração básica dos tamanhos do gráfico e fontes.
# Configurações dos gráficos plt.rcParams['figure.figsize'] = (15,10) plt.rcParams['xtick.labelsize'] = 10 plt.rcParams['ytick.labelsize'] = 10 plt.rcParams['font.size'] = 15 plt.rcParams['axes.titlesize'] = 20
Configurações prontas vamos ao primeiro gráfico. O gráfico do tipo boxplot podemos identificar os quartis e os outliers de uma variável, no exemplo abaixo utilizamos os valores de venda.
# Identificando outliers nos valores de vendas sns.boxplot(x = df['Valor Venda']) plt.show()
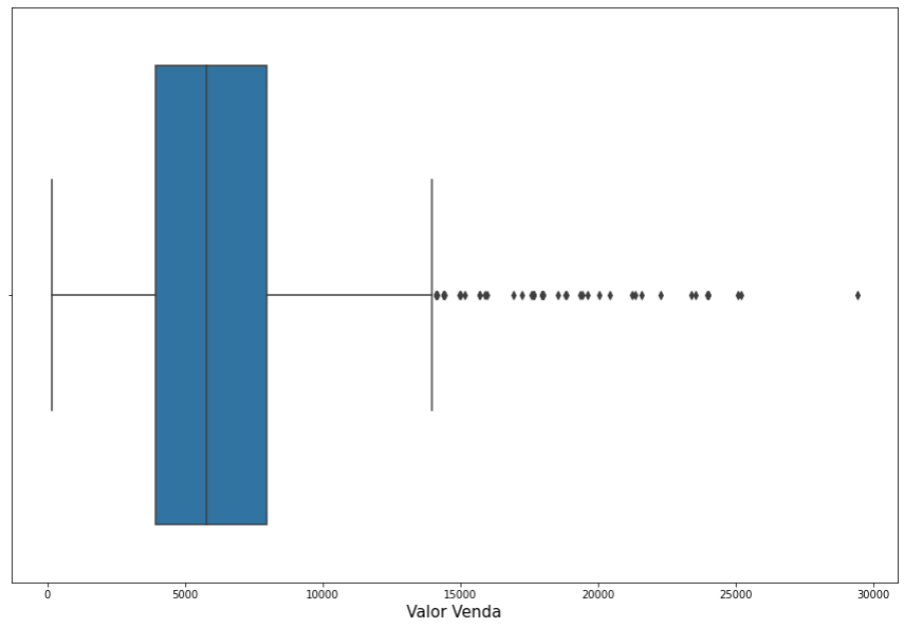
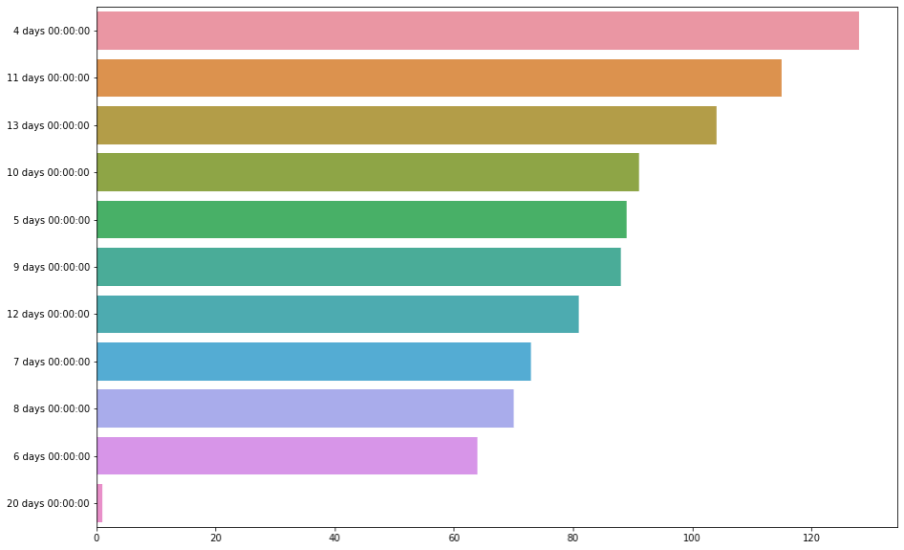
Uma segunda análise possível é com o gráfico do tipo barras, utilizado para fazer comparações entre os valores de uma variável. Utilizamos no gráfico abaixo os dias de envio.
# Identificando as quantidades dos dias de envio x = df['Dias de Envio'].value_counts().values y = df['Dias de Envio'].value_counts().index sns.barplot( x=x, y=y ) plt.show()
Que fique claro que correlação não é causalidade! Mas analisar a correlação das variáveis é importante para entender como as variáveis se relacionam entre si.
# Mapa de correlação das variáveis numéricas sns.heatmap(df.corr(), annot=True, cmap="PiYG") plt.show()
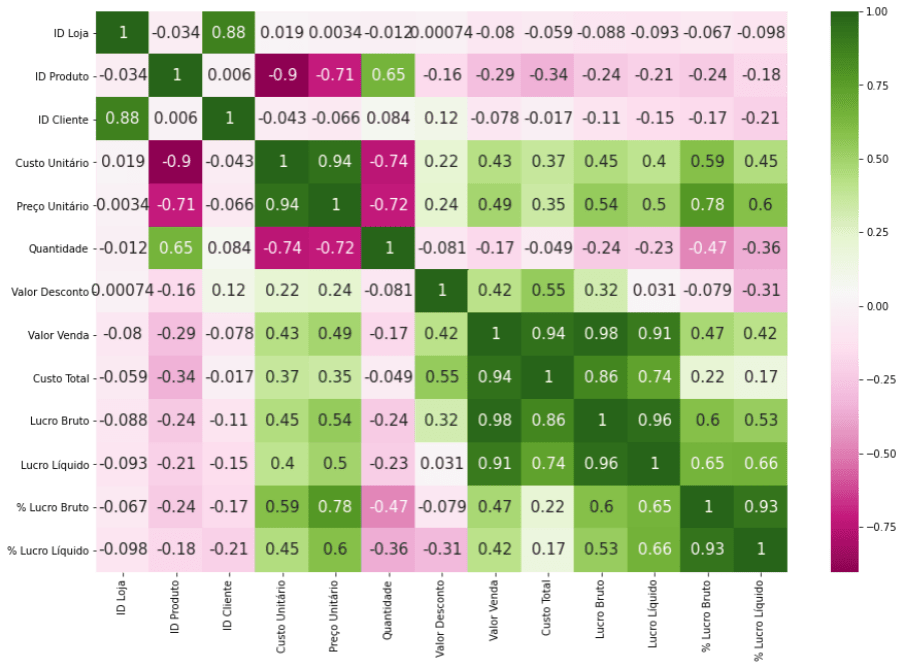
E para finalizar, um gráfico comparativo do tipo linhas. Aqui separamos os dados em dois conjuntos (2008 e 2009) para exibir a evolução do lucro bruto ao longo de cada ano. Plotando no mesmo gráfico podemos fazer um comparativo dos anos mês a mês.
#Selecionando apenas as vendas de 2008
df_2008 = df[df["Data Venda"].dt.year == 2008]
#Selecionando apenas as vendas de 2009
df_2009 = df[df["Data Venda"].dt.year == 2009]
# Comparativo de lucro bruto por mês
df_2008.groupby(df_2008["Data Venda"].dt.month)["Lucro Bruto"].sum().plot(color='red', label='Ano 2008')
df_2009.groupby(df_2009["Data Venda"].dt.month)["Lucro Bruto"].sum().plot(color='green', label='Ano 2009')
plt.title("Lucro x Mês")
plt.xlabel("Mês")
plt.ylabel("Lucro Bruto")
plt.legend()
plt.show()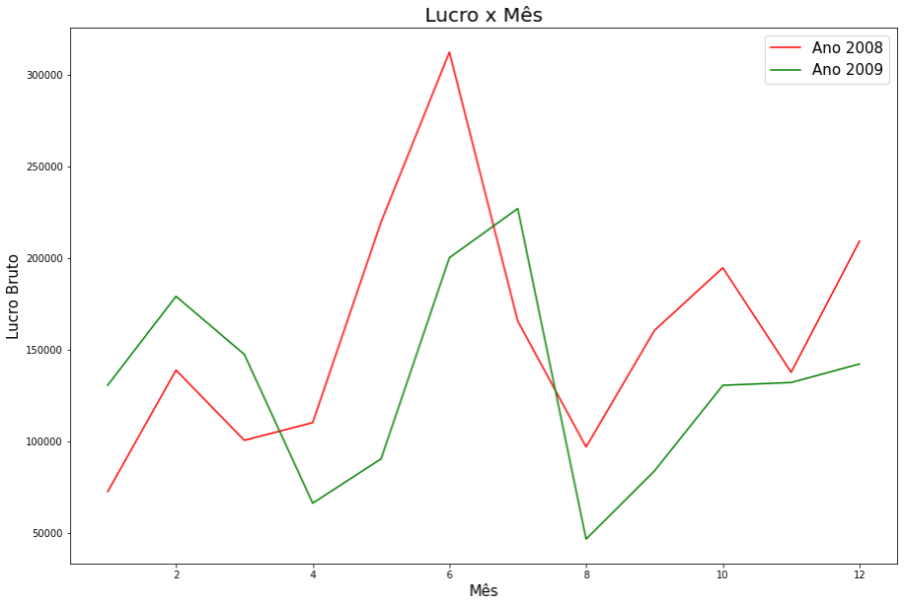
Bastante coisa né? Mas isso é só o começo, a análise exploratória de dados é um mundo e o Python ajuda e muito nessa atividade.
Análise Exploratória de Dados com Python ao Cubo
A atividade de análise exploratória dos dados é uma das etapas mais importantes na área de ciência de dados. Deve ser realizada da forma mais completa possível, a fim de entender os dados e gerar valor para o negócio.
O Python e suas bibliotecas para ciência de dados facilitam e muito essa atividade, com ferramentas cada vez mais completas e poderosas. É um processo trabalhoso muito importante e nunca deve ser negligenciado.
O que vimos aqui é só a pontinha do iceberg, a criatividade é o limite na análise exploratória dos dados. Go Go Go EDA! O notebook completo você pode fazer o download no meu GitHub, um abraço e até a próxima.
Conteúdos ao Cubo
Abaixo algumas sugestões de posts anteriores também do Dados ao Cubo, sempre falando sobre o mundo dos dados.
- DataViz com Power BI
- Entre Vieses e Causalidades: Como (não) ser Enganado pelos Dados
- Introdução à Gramática dos Gráficos com plotnine
- Storytelling com Dash e Plotly
- Boas Práticas de Visualização de Dados Parte I
- Alterar Dados com Streamlit e o PostgreSQL
- Análise de Dados com Numpy Python
- Visualizar Dados do PostgreSQL no Metabase
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀

1 Comment
hloliveira
20 de novembro de 2022achatamento (kurtosis). Quais são os parâmetros que definem a forma da distribuição sendo analisada? Até que valor pode ser considerada simétrica? A partir de que valor é considerada assimetrica? Há valores nominais ou ordinais para classificar a assimetria? A mesma pergunta vale para o achatmento. Parabéns pelo artigo, que venham outros, adorei!