
Fala galera do mundo dos dados! Já pensou em usar Ciência de Dados para Mercado de Ações? Dá para tirar muitos insights e aprender muita coisa bacana sobre o assunto. Já falamos sobre esse tema por aqui no Ciência de Dados para Mercado de Ações Parte I, se não viu, confere que é sucesso.
Na primeira parte falamos sobre Crawling x Scraping, bibliotecas do Python, onde conseguir e armazenar os dados, para praticar e fechamos com um mão na massa com dados do portal Oceans14.
Então, na segunda parte, utilizaremos o portal Yahoo Finance através da biblioteca yahooquery para conseguir os dados. Na sequência analisamos a série temporal com a lib statsmodels e aplicamos um modelo de previsão de séries temporais com a sktime. Portanto, se nunca ouviu falar de uma série temporal, recomendo o conteúdo de Previsão de Séries Temporais com SKTime aqui do Dados ao Cubo.
É importante deixar bem claro que não estamos fazendo indicações de formas ou estratégias de investimento. Aqui te apresento formas para melhor analisar os dados disponíveis. As decisões sempre serão suas do melhor investimento. Então chega de conversa e partiu ao Mercado de Ações ao Cubo!!!
Instalação das bibliotecas Python
Primeiramente, vamos instalar as bibliotecas necessárias para executar a aplicação Python. A biblioteca yahooquery realizará as consultas dos dados financeiros de empresas listadas na bolsa. Já a biblioteca sktime será responsável pela criação do modelo de machine learning de previsão de uma série temporal. As demais bibliotecas já estão instaladas, caso precise instalar mais algum usar o mesmo comando pip install pacote.
pip install yahooquery pip install sktime
Depois de instalar as bibliotecas, iniciaremos o código da aplicação Python.
Importação das bibliotecas Python
Agora importamos todas as bibliotecas necessárias para nossa aplicação. temos a yahooquery com os dados financeiros a pandas para manipulação dos dados, a statsmodels para análise da série temporal a matplotlib e seaborn para criação de algumas visualizações gráficas e a sktime com as funções necessárias para a criação dos modelos de machine learning.
from yahooquery import Ticker import pandas as pd from statsmodels.tsa.seasonal import seasonal_decompose import matplotlib.pyplot as plt import seaborn as sns from sktime.forecasting.base import ForecastingHorizon from sktime.forecasting.naive import NaiveForecaster from sktime.forecasting.model_selection import temporal_train_test_split from sktime.forecasting.theta import ThetaForecaster from sktime.performance_metrics.forecasting import mean_absolute_percentage_error from sktime.utils.plotting import plot_series
Logo depois de todas as bibliotecas importadas podemos partir para o que interessa.
Yahoo Finance com Python
A biblioteca yahooquery consulta dados financeiros direto do Yahoo Finance através do Python na sequência algumas consultas de dados financeiros.
Para começar, consultaremos alguns dados financeiros das maiores Big tags do planeta. A sigla FAANG se refere às maiores empresas de tecnologia. São elas: Facebook (Meta), Amazon, Apple, Netflix e Google. Faremos isso através da função Ticker.
symbols = ['aapl', 'amzn', 'nflx', 'goog', 'meta'] faang = Ticker(symbols)
Através da função summary_profile é possível consultar um resumo do negócio. dessa forma é possível consultar algumas informações básicas como localização, site, setor, quantidade de empregados entre outros.
pd.DataFrame(faang.summary_profile)
Como podemos observar na imagem abaixo, através de um dataframe gerado com a biblioteca pandas.
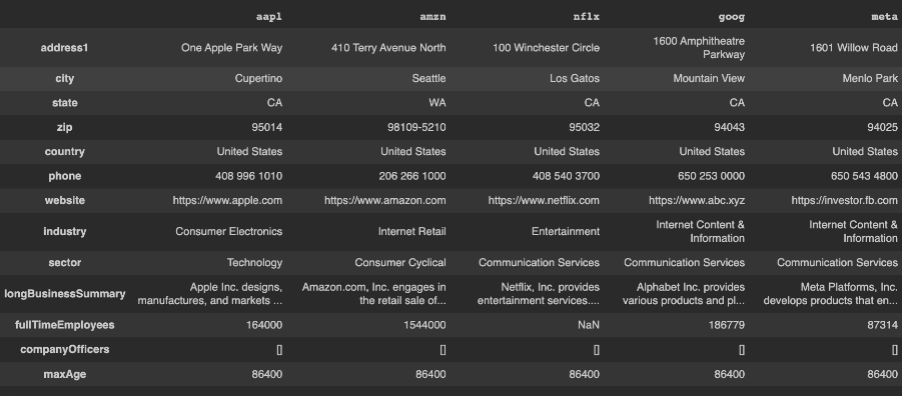
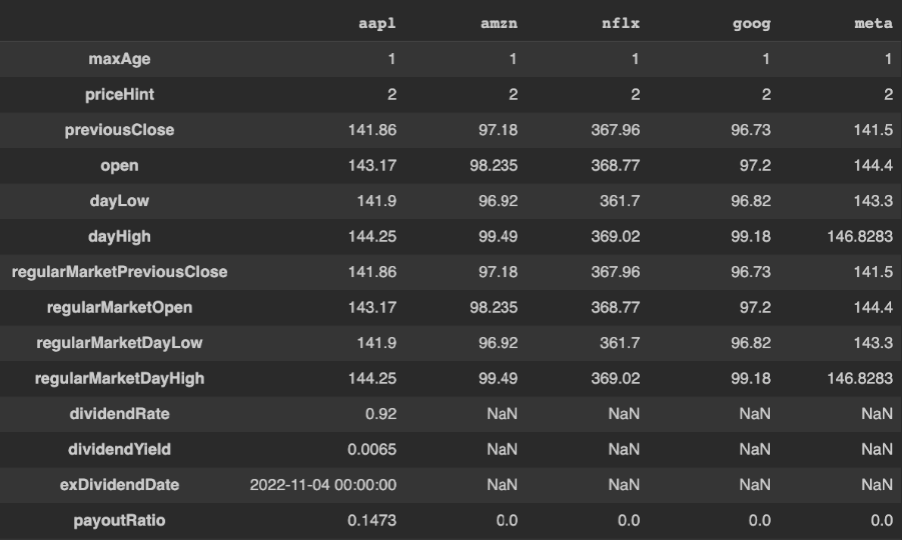
Temos também a função summary_detail que traz também um resumo, porém de uma forma mais detalhada. Aqui já temos dados financeiros sobre a empresa, são as informações disponíveis no guia Resumo no Yahoo Finance.
pd.DataFrame(faang.summary_detail)
De acordo com a imagem abaixo está o exemplo desse resumo detalhado.
Além destas informações financeiras referente a o status da empresa, podemos consultar também o seu histórico de cotação e para este exemplo vamos utilizar uma empresa nacional, a Petrobras. O código Python abaixo, seleciona a ação PETR4.
Yahoo Finance PETR4
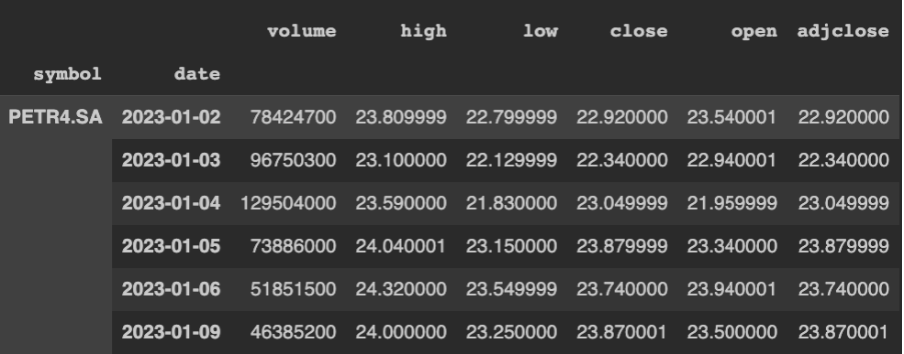
symbol = Ticker('PETR4.SA')Através da função history teremos os dados históricos de preços, de acordo com os parâmetros de start e end, que definem o período a ser consultado.
symbol.history(start="2023-01-01", end="2023-01-10")
Aqui temos, na imagem abaixo, todo histórico de valor das ações consultadas.
Para a análise, vamos selecionar um período maior, lembrando que a escolha desse período influencia diretamente na análise e no modelo de machine learning que será criado.
Observe no código Python abaixo, que além da seleção histórica do período faremos um reset do index, e selecionaremos as colunas data e fechamento.
data = symbol.history(start="2022-10-01", end="2023-01-26").reset_index()[['date','close']]
Na sequência colocamos a coluna de data como datetime e indicamos a mesma como o índice.
data = data.set_index(pd.to_datetime(data['date']))
Até aqui, tínhamos os dados em um dataframe, agora vamos transformar o mesmo em uma série onde o índice será a data e a coluna será o valor do fechamento dia a dia.
serie = data['close']
Para ficar mais claro o que estamos fazendo com os dados, Utilizaremos a função lineplot do seaborn para gerar um gráfico de linha com os valores da nossa série.
sns.lineplot(data=serie);
O gráfico de linha é perfeito para analisar séries temporais, observe na imagem abaixo onde o nosso eixo X é o período selecionado e o eixo Y é o valor do fechamento da ação.
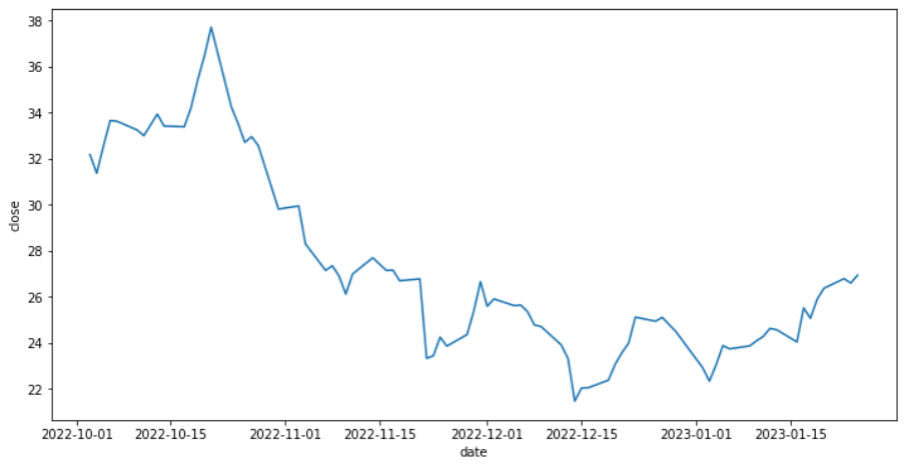
Para um estudo mais específico utilizaremos a biblioteca StatsModels para analisar a série temporal.
Série Temporal com StatsModels
A biblioteca StatsModels contém funções que são úteis para análise de séries temporais. Aqui faremos a análise a partir da decomposição da série temporal, através da função seasonal_decompose.
Um parâmetro opcional é o período padrão da série, neste caso utilizaremos a quantidade de meses para definir o nosso período conforme o código Python abaixo.
period=int(len(serie)/4)
Com código Python abaixo, faremos a decomposição da série através da função seasonal_decompose, passando como parâmetros a nossa série e o período padrão.
serie_dec = seasonal_decompose(serie, period=period)
Podemos visualizar a decomposição a partir dos dados ou de forma visual. No código abaixo mostramos como exibir essa decomposição através da função plot, que gera um gráfico com a série, a tendência, a sazonalidade e o resíduo.
serie_dec.plot();
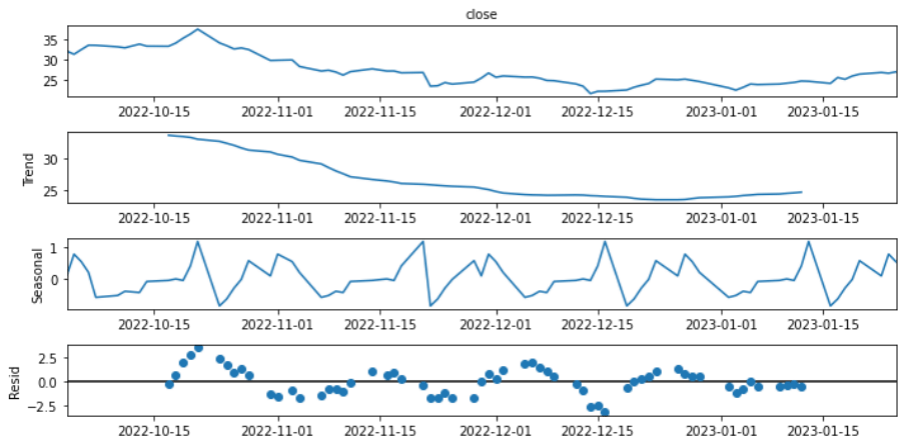
Os componentes da série temporal exibidos no gráfico acima são definidos como:
- Tendência – O comportamento da série, se ela cresce, decresce ou é estável, além da velocidade dessas mudanças
- Sazonalidade – São as oscilações da série em períodos específicos analisadas ao longo das séries
- Resíduo – É o que não pode ser previsto em uma série, também conhecido como ruído, é o que sobra da série após a retirada da Tendência e Sazonalidade
Após análise da série temporal utilizaremos a mesma para criar um modelo de machine learning similar ao que foi feito no conteúdo de Previsão de Séries Temporais com SKTime.
Modelo de Série Temporal com SKTime
Para criação de um modelo de machine learning, é preciso ter o input dos dados corretos. E é isso que vamos fazer no código Python abaixo. Primeiro faremos uma transformação do Index da série para periodicidade diária assim sendo possível realizar o input nos modelos que vamos criar na sequência.
serie = pd.DataFrame(serie).set_index(data.index.to_period('D'))['close']Modelo de Série Temporal ThetaForecaster
O primeiro modelo criado será o ThetaForecaster. E para testar o mesmo faremos uma divisão no conjunto de dados entre treino e teste com a função temporal_train_test_split. Já para avaliar o modelo utilizaremos a função mean_absolute_percentage_error, onde quanto mais próximo de zero teremos o modelo com melhor performance.
y_train, y_test = temporal_train_test_split(serie) fh = ForecastingHorizon(y_test.index, is_relative=False) forecaster = ThetaForecaster(sp=29) forecaster.fit(y_train) y_pred_theta = forecaster.predict(fh) mean_absolute_percentage_error(y_test, y_pred_theta) 0.0710056511594885
Após realizar o fit do modelo nos dados de treino e fazer uma predição com os dados de teste, obtemos o valor de 0.071.Que também pode ser interpretado como aproximadamente 7,1% de erro ou 92,9% de confiança no modelo.
Modelo de Série Temporal NaiveForecaster
Agora o segundo modelo criado será o NaiveForecaster. E para testar faremos o mesmo do modelo anterior.
forecaster = NaiveForecaster(strategy='last', sp=20) forecaster.fit(y_train) y_pred_naive = forecaster.predict(fh) mean_absolute_percentage_error(y_test, y_pred_naive) 0.054354722067450824
Aplicando o fit no modelo nos dados de treino e fazer uma predição com os dados de teste, obtemos o valor de 0.054. Que também pode ser interpretado como aproximadamente 5,4% de erro ou 94,6% de confiança no modelo.
Comparando Modelos de Séries Temporais
E então, para uma comparação visual faremos um plot da série com os dados reais e com as previsões realizadas por ambos os modelos.
plot_series(y_train, y_test, y_pred_theta, y_pred_naive,
labels=["y_train", "y_test", "y_pred_theta", "y_pred_naive"]);De acordo com o gráfico, podemos perceber o quão próximo temos ambos os modelos dos conjuntos de dados reais. Vale ressaltar que os modelos de machine learning buscam uma melhor previsão dado um input de dados e não valor exato sem erros.
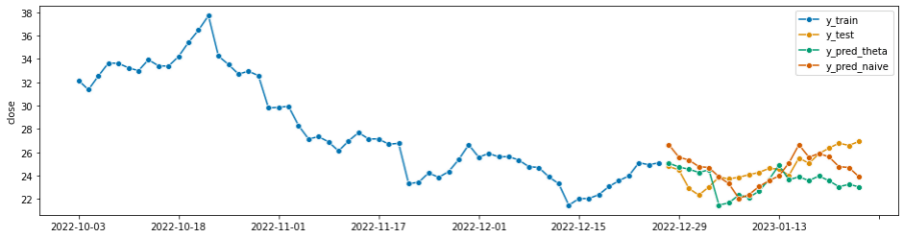
Sendo assim, mais uma vez reforço que não estamos fazendo indicações de formas ou estratégias de investimento. Estamos apresentando mais uma ferramenta para análise de dados e uma melhor tomada de decisão.
Ciência de Dados para Mercado de Ações ao Cubo
Então, aqui vimos algumas formar de utilizar a ciência de dados para o mercado de ações e obter alguns insights para ter decisões baseadas em dados nos investimentos. Dessa forma, Espero que vocês tenham gostado do conteúdo, não esquece de mandar aquele feedback para nós e compartilhar o conteúdo com a comunidade. Um abraço e até a próxima
Conteúdos ao Cubo
Portanto, se você curtiu o conteúdo, lá no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar por lá, sempre falando sobre o mundo dos dados.
- Conectar Banco de Dados MySQL com Python
- Manipular Dados no MySQL com Pandas
- Introdução à Gramática dos Gráficos com plotnine
- Compreendendo Agile BI – Parte I
- Agile BI na Prática – Parte II
- BI do Problema ao Dashboard
- Análise de Imagens com OpenCV
- Geração de Relatórios em PDF com Python
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo, escrever o próximo artigo e ter divulgação para toda a comunidade de dados no LinkedIn.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
