

Fala galera do mundo dos dados! Já estamos cansados de saber que a análise de dados é uma etapa fundamental em projetos de ciência de dados e inteligência artificial. Já vimos aqui no Dados ao Cubo como fazer uma análise de dados poderosa com Polars em Python, mas sabemos que também podemos utilizar o Pandas para análise de dados. Portanto, são duas bibliotecas para manipulação e análise de dados, uma já consolidada e outra chegando com tudo. Então, vamos comparar Polars vs. Pandas e explorar as principais funções dessas bibliotecas. Dessa forma, você aprenderá como realizar tarefas comuns de análise de dados usando ambas as bibliotecas, além de identificar as diferenças entre elas.
Instalação e Importação das Bibliotecas
Primeiramente, é importante instalar as bibliotecas necessárias. Para o Polars, você pode usar o seguinte comando.
pip install polars
Para o Pandas, use o comando.
pip install pandas
Em seguida, importe as bibliotecas em seu código.
# Polar import polars as pl # Pandas import pandas as pd
Agora, faremos a carga de um conjunto de dados.
Carregando Dados
Ambas as bibliotecas possuem funções para carregar dados de diferentes fontes, como arquivos CSV ou bancos de dados. Aqui está um exemplo de como carregar um arquivo CSV com o Polars.
# Polars
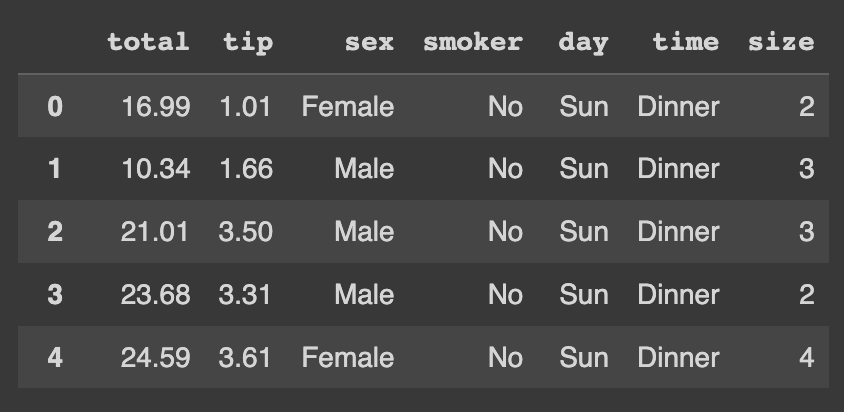
pl_df = pl.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv')E com o Pandas:
# Pandas
pd_df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv')Com os dados carregados, já podemos visualizar uma prévia deles.
Visualizando os Dados
Para visualizar os dados, o Pandas oferece a função head, que retorna as primeiras linhas do DataFrame. Já o Polars possui a função limit. Veja os exemplos de código abaixo.
# Polars pl_df.limit(5)
Como resultado da função limit é exibido na imagem abaixo.
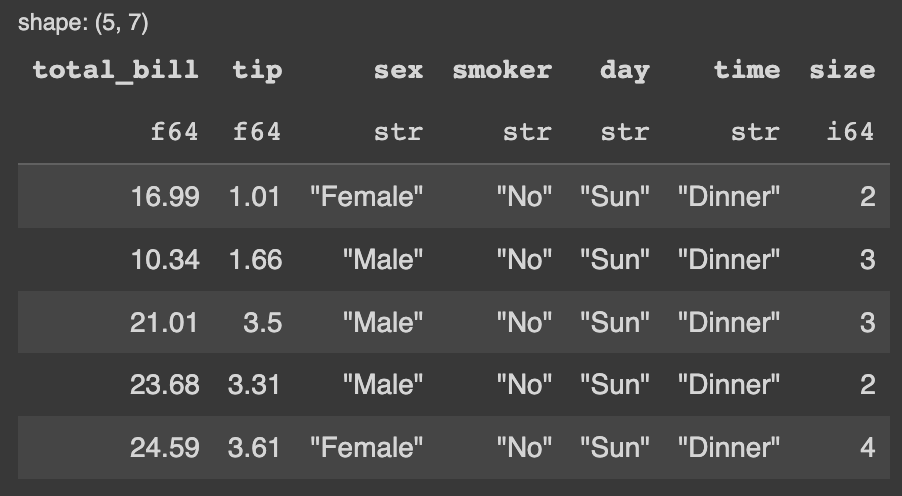
Confere a visualização no Pandas.
# Pandas pd_df.head
O resultado da função head é exibido na imagem abaixo.
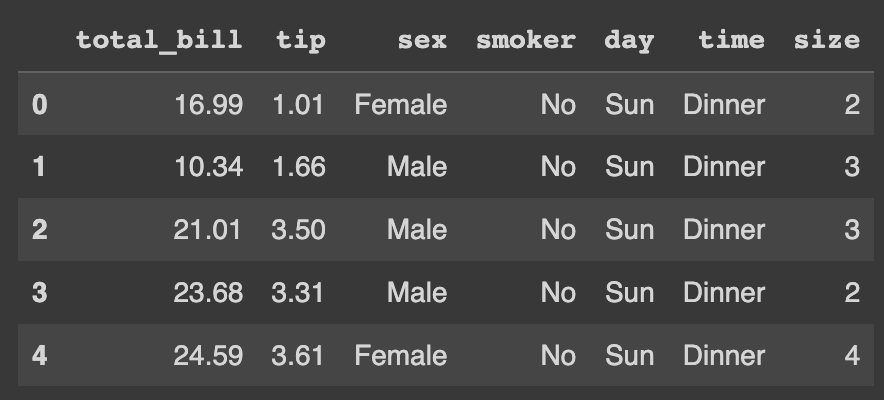
Assim, visualizamos todas as colunas. E como selecionar algumas colunas?
Selecionando Colunas
Ambas as bibliotecas permitem selecionar colunas específicas de um DataFrame. Com o Pandas, você pode usar a sintaxe de colchetes [], enquanto com o Polars é possível usar a função select. Veja o exemplo abaixo.
# Polars
pl_df.select('total_bill')Confere o resultado da seleção do Polars na imagem abaixo.

Seleção de colunas no Pandas.
# Pandas pd_df['total_bill']
Confere o resultado da seleção do Pandas na imagem abaixo.
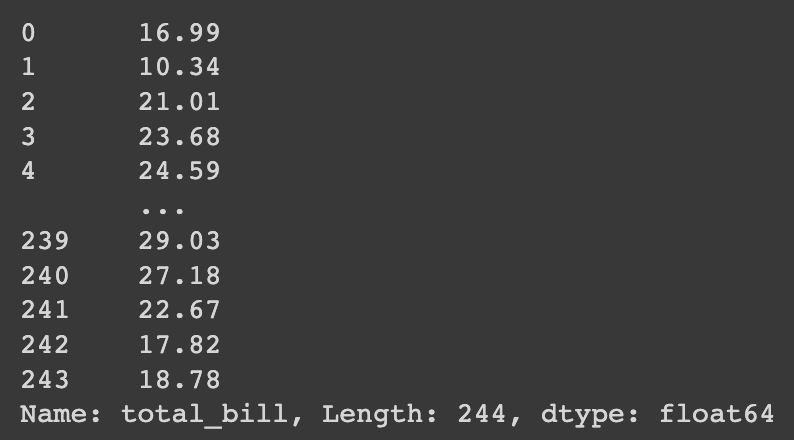
Dessa forma, fizemos a seleção de linha. E como filtrar linhas específicas?
Filtrando Dados
Para filtrar dados com base em condições, o Pandas usa a sintaxe de colchetes [] combinada com uma expressão booleana. O Polars oferece a função filter. Veja o código Pyhon a seguir.
# Polars
pl_df.filter(pl.col('total_bill') > 50)Dados filtrados com o Polars.

O filtro no Pandas.
# Pandas pd_df[pd_df['total_bill'] > 50]
Dados filtrados com o Pandas na imagem abaixo.

Na sequência a agregação de dados.
Agregando de Dados
Ambas as bibliotecas oferecem funcionalidades para realizar agregações de dados, como soma, média e contagem. Veja o exemplo da soma abaixo.
# Polars pl_df['total_bill'].sum()
Dessa forma, no Polars, temos como resultado o valor resultante da soma de: 4827.7699999999995
# Pandas pd_df['total_bill'].sum()
Dessa forma, no Pandas, temos como resultado o valor resultante da soma de: 4827.77
Também, podemos fazer agregações mais complexas utilizando a função groupby em ambas as bibliotecas. Confere os exemplos de código.
# Polars
pl_df.groupby('sex').agg(pl.col('total_bill').mean)Agregação do groupby no Polars.
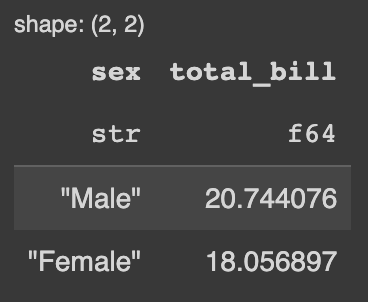
Utilizando o groupby no Pandas.
# Pandas
pd_df.groupby('sex').agg({'total_bill': 'mean'})Agregação do groupby no Pandas.
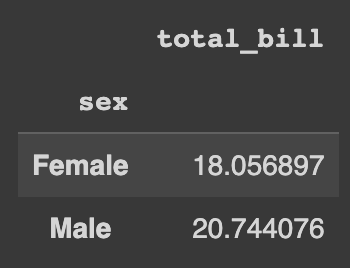
Da agregação para a alteração do nome das colunas.
Renomeando colunas
Ambas as bibliotecas possuem a função rename. Aqui está um exemplo de como renomear colunas tanto no Polars, quanto no Pandas.
# Polars
pl_df.rename({'total_bill':'total'})Na imagem abaixo já temos a primeira coluna renomeada, conforme código Python.

Função rename no Pandas.
# Pandas
pd_df.rename(columns={'total_bill':'total'})Agora com o Pandas, também temos a primeira coluna renomeada, conforme código Python.
Depois de renomear, na sequência, como ordenar o conjunto de dados.
Ordenando os dados
Para ordenar os dados, o Pandas oferece a função sort_values, ordenando pela coluna informada do DataFrame. Já o Polars possui a função sort, que trabalha da mesma forma. Veja os exemplos de código abaixo.
# Polars
pl_df.sort('total_bill')A imagem abaixo é o resultado da ordenação da coluna total_bill pelo Polars.
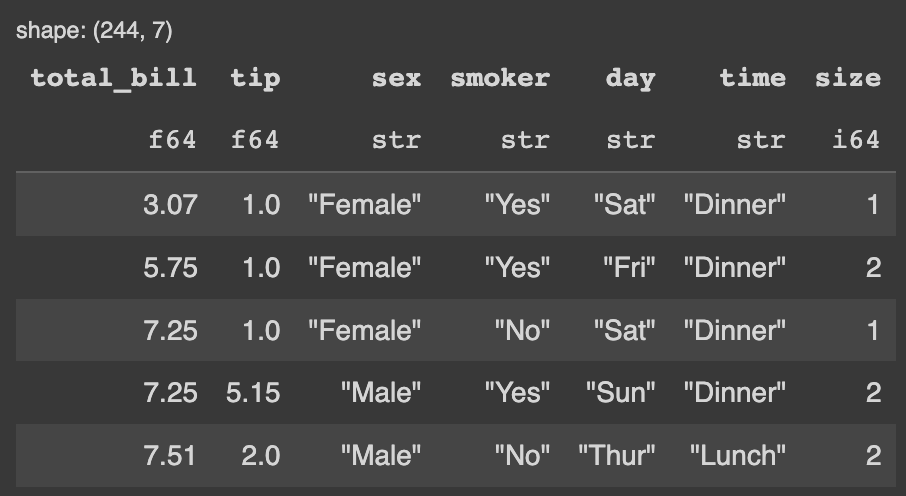
Confere a função de ordenação do Pandas.
# Pandas
pd_df.sort_values('total_bill')Como resultado da ordenação da coluna total_bill pelo Pandas temos a imagem abaixo.
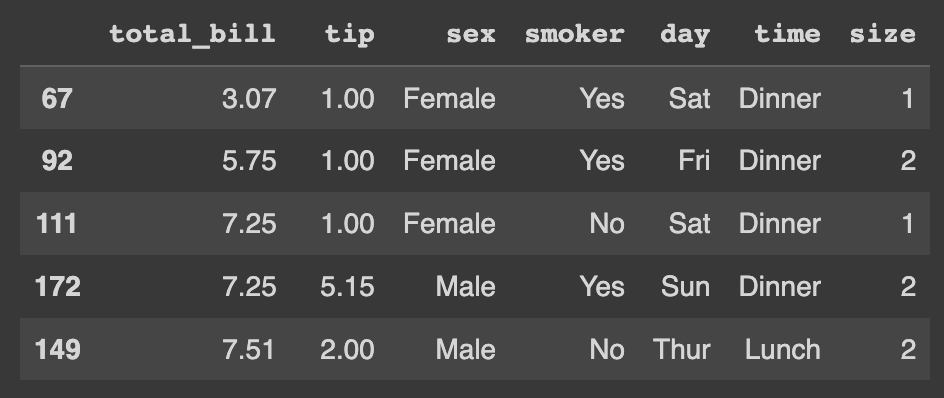
Dados ordenados, confere como deletar linhas duplicada.
Removendo duplicatas
Ambas as bibliotecas permitem remover dados duplicados em um DataFrame. Com o Pandas, você pode usar a função drop_duplicates, enquanto com o Polars é possível usar a função unique. A seguir exemplos das funções.
Código Polars para remover dados duplicados.
# Polars pl_df.unique()
E o código Pandas para remover dados duplicados.
# Pandas pd_df.drop_duplicates()
Depois dos duplicados, agora o tratamento de dados nulos.
Preenchendo valores nulos
Para preencher valores nulos, primeiramente vamos identificar as colunas e quantidades de dados nulos e depois podemos fazer o preenchimento. Assim, no Pandas usa a função fillna para identificar os nulos e a função fillna para preencher valores nulos. Similarmente o Polars oferece a função null_count e a função fill_null para preencher valores nulos. Veja os códigos Pyhon a seguir.
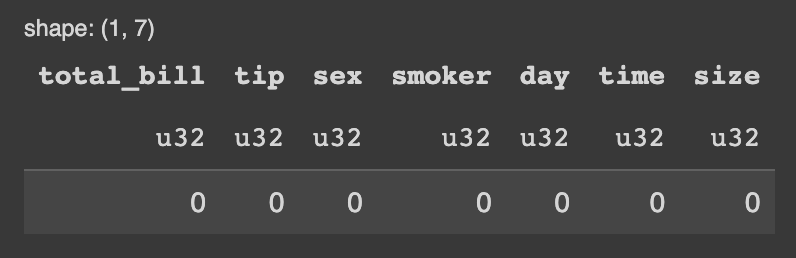
# Polars pl_df.null_count()
Na imagem abaixo a contagem dos dados nulos de todas as colunas no Polars.
Se houver necessidade de substituição de dados nulos, podemos utilizar o código Python abaixo.
# Polars pl_df.fill_null(value='novo_valor')
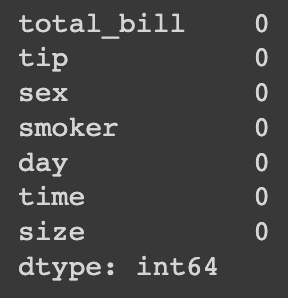
Contagem dos dados nulos com o Pandas.
# Pandas pd_df.isna.sum()
A imagem mostra o resultado, bem semelhante ao Polars, só muda o formato dos dados.
Para o Pandas, se houver necessidade de substituição de dados nulos, podemos utilizar o código Python abaixo.
# Pandas
pd_df.fillna('novo_valor')Agora vamos ver, como aplicar funções em colunas do conjunto de dados.
Aplicando uma função a uma coluna
Para aplicar função em uma coluna, o Pandas oferece a função apply, e o Polars possui a função de mesmo nome. Veja os exemplos de código abaixo.
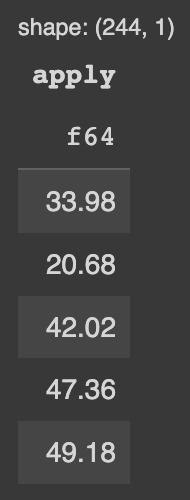
# Polars
pl_df.select('total_bill').apply(lambda x: x[0] * 2)A imagem a seguir mostra a função sendo aplicada na coluna total_bill do dataframe Polars.
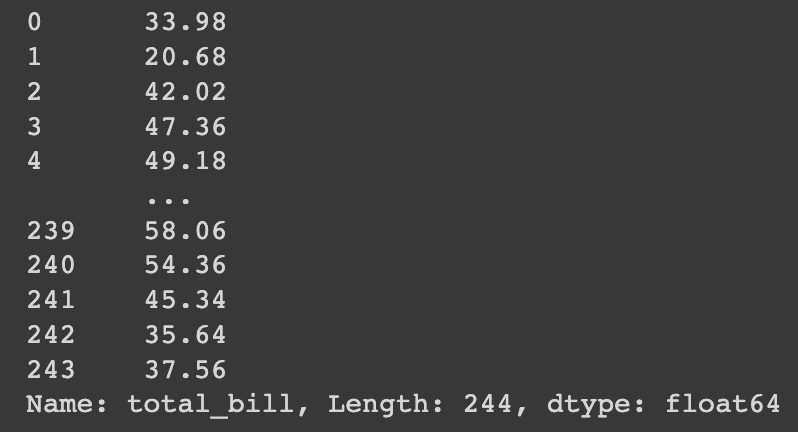
A mesma função apply, agora no Pandas.
# Pandas pd_df['total_bill'].apply(lambda x: x * 2)
Da mesma forma a função sendo aplicada na coluna total_bill do dataframe Pandas.
A seguir, algumas estatísticas básicas do conjunto de dados.
Estatísticas descritivas
Ambas as bibliotecas oferecem funcionalidades para estatísticas descritivas dos dados, exibindo os principais indicadores através da função describe. Confere os exemplos a seguir.
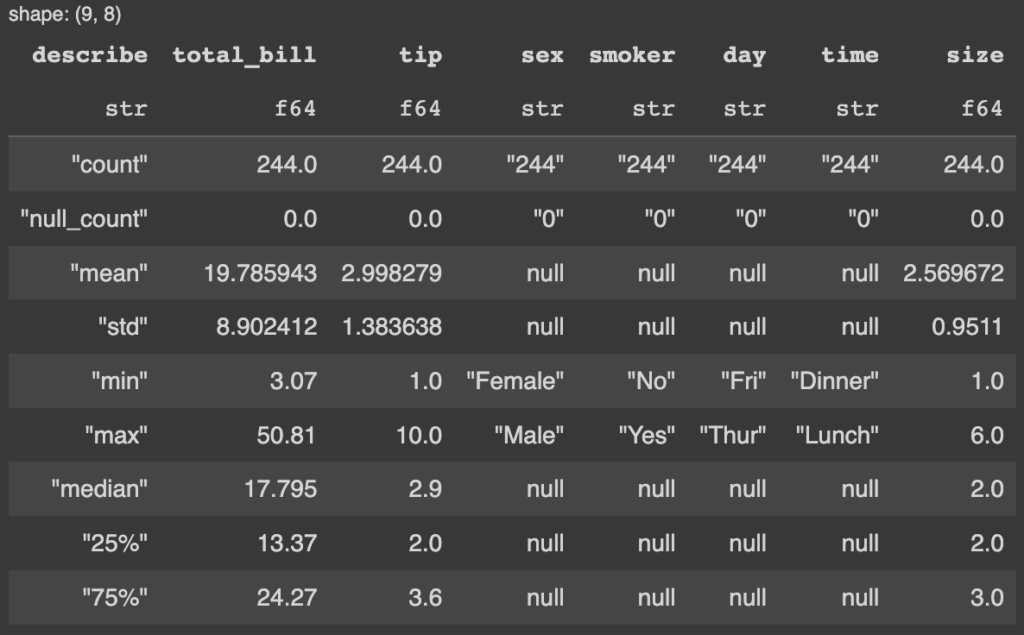
# Polars pl_df.describe()
Esse é o resultado da função describe no dataframe Polars.
Agora a estatística descritiva no Pandas.
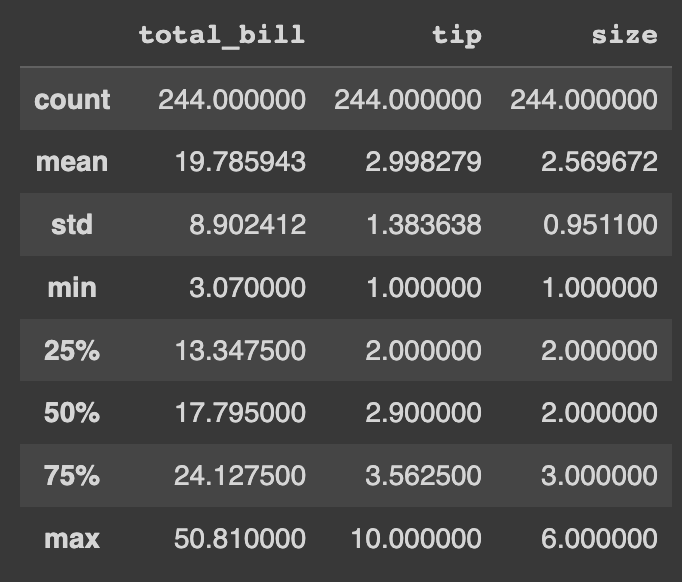
# Pandas pd_df.describe()
Já no Pandas, temos esse resultado da função describe, que é bem similar.
E para encerrar nossas comparações, como contar a frequência dentro do conjunto de dados.
Contando de valores únicos
Para cotar valores únicos no DataFrames, o Pandas possui a função value_counts, e o Polars oferece a função de mesmo nome. Veja o exemplo abaixo.
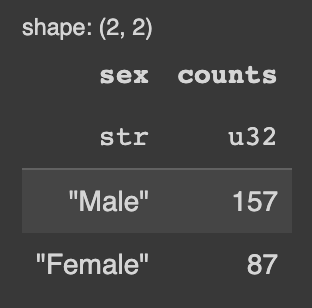
# Polars
pl_df.select('sex').to_series.value_counts()Na imagem a seguir a frequência da coluna sex no dataframe Polars.
Utilizando a mesma função value_counts no Pandas.
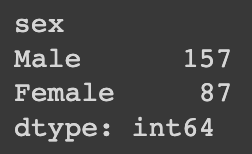
# Pandas
pd_df.value_counts('sex')E no Pandas, não é muito diferente, confere a imagem abaixo.
E assim finalizamos essa comparação de algumas funções do Polars vs. Pandas.
Polars vs. Pandas ao Cubo
Sendo assim, tanto Polars, quanto Pandas são bibliotecas poderosas para análise de dados em Python. Ambas possuem uma ampla gama de funções e métodos para manipulação e análise de DataFrames. No entanto, existem algumas diferenças sutis entre as duas.
Polars vs. Pandas, o Polars se destaca por sua capacidade de processamento paralelo e execução eficiente em grandes conjuntos de dados. Ele também oferece uma sintaxe expressiva e familiar para quem já está acostumado com o Pandas. Por outro lado, o Pandas é amplamente utilizado e possui uma vasta quantidade de recursos e funcionalidades avançadas. É uma escolha popular para análise de dados em tarefas de menor escala ou quando a velocidade de execução não é uma preocupação crítica.
Experimente as diferentes funcionalidades de cada biblioteca, explore a documentação e os exemplos de código, e escolha a que melhor atenda às suas necessidades e objetivos de análise de dados. Com o conhecimento adequado e a prática contínua, você se tornará um especialista em análise de dados com Python. O importante é estar sempre atualizado, então para ficar sempre ligado nas novidades assine a nossa Newsletter. Um abraço e até a próxima!!!
Conteúdos ao Cubo
Se você curtiu o conteúdo, aqui no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar. Sempre falando sobre o mundo dos dados!
- Time de Dados na Prática
- Etapas para Análise de Dados
- Tipos de Análise de Dados
- Dicas para Visualização de Dados
- Análise de Dados com Airbyte e Metabase
- Importar CSV no PostgreSQL com o DBeaver
- Manipular Dados no MySQL com Pandas
- Google Analytics e o Dados ao Cubo
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
