

Fala galera do mundo dos dados! Dando continuidade a trilogia API com Python, o céu é o limite. Quando fizemos a ingestão de dados da API, nos deparamos com o seguinte problema: para conseguir o detalhe de cada agente público precisamos fazer uma requisição individual na API com a sua identificação. Dessa forma, como temos 513 deputados federais atualmente, precisamos fazer 513 requisições na API. Então, realizar essa operação de forma sequencial irá levar um certo tempo. Será que o processamento paralelo com Python pode nos auxiliar?
Antes de responder essa pergunta, vamos compreender o que é processamento paralelo e as vantagens de se utilizar essa forma de processamento. Conheceremos a biblioteca multiprocessing, que irá nos auxiliar nessa operação e por fim veremos na prática como pode ser implementado o paralelismo em Python.
O que é Processamento Paralelo?
O processamento paralelo, é a forma de computação onde os cálculos são realizados ao mesmo tempo ou em outras palavras trabalham de forma concorrente. Dessa forma, é possível realizar tarefas ao mesmo tempo para otimizar tempo de processamento.
Vejamos a definição de computação paralela do livro Ciência da computação escrito por Nell Dale, John Lewis:
“Arquiteturas paralelas oferecem diversas formas para aumentar a velocidade de execução. Por exemplo, um dado passo em um programa pode ser separado em múltiplos pedaços e estes pedaços podem ser executados simultaneamente em vários processadores individuais.”
Com as definições acima em mente, vamos relembrar o nosso problema. Precisamos fazer diversas requisições na API, o que pode ser um processo bem lento. Mas, se utilizarmos o processamento paralelo podemos ganhar tempo na execução da tarefa.
Porque utilizar o Processamento Paralelo?
Utilizando processamento paralelo, conseguimos aumentar a velocidade de execução da tarefa, otimizando o tempo de processamento. Assim, as tarefas que levariam horas, podem ser executadas em minutos se utilizarmos a computação paralela.
A Biblioteca Multiprocessing
O pacote de multiprocessamento permite a execução em paralelo com o Python. Para o processamento são utilizados subprocessos ao invés de threads, dessa forma ele evita o bloqueio do interpretador no momento da execução. Permitindo ao programador a utilização de todos os núcleos de processamento em uma determinada máquina (roda em Unix e Windows). É a programação paralela com Python acontecendo! A biblioteca pode ser instalada utilizando o comando abaixo:
pip install multiprocessing
Uma grande vantagem da biblioteca Multiprocessing é a utilização do processamento em Pool. Esta tarefa permite que uma função receba vários valores de entradas, que são distribuídas para os processos que são executados paralelamente, realizando um paralelismo de dados. É justamente esse tipo de processamento o que vamos exemplificar logo abaixo.
Processamento Paralelo com o Dados ao Cubo
Iniciamos importando as bibliotecas necessárias para o desenvolvimento do nosso código Python.
import requests import json import pandas as pd from tqdm import tqdm from time import sleep, time from multiprocessing.pool import ThreadPool import seaborn as sns import matplotlib.pyplot as plt
As bibliotecas requests e json vão auxiliar na extração dos dados da API. O pacote pandas vai realizar a estruturação de dados. As bibliotecas tqdm e time vão ajudar a monitorar os tempos de execução. Para o processamento paralelo em Python, temos o pacote multiprocessing. E por fim, seaborn e matplotlib vão auxiliar na parte gráfica na análise dos dados.
Requisição Sequencial de Dados da API com Python
Vamos relembrar a requisição dos dados na API. Para isso Utilizaremos a função request do pacote requests, passando o método (GET), a url (https://dadosabertos.camara.leg.br/api/v2/deputados). Com o resultado da requisição utilizaremos a função loads da biblioteca json para obter os dados em um formato de dicionário.
# Requisição dos dados dos Deputados
url = 'https://dadosabertos.camara.leg.br/api/v2/deputados'
parametros = {}
resposta = requests.request("GET", url, params=parametros)
objetos = json.loads(resposta.text)
dados = objetos['dados']Essa requisição vai servir para fazer outra consulta para buscar o detalhe de cada deputado. Para isso, vamos colocar na variável id todos os ids dos deputados acima.
# Selecionando todos os ids dos deputados
id = []
for i in range(len(dados)):
id.append(str(dados[i]['id']))Em seguida uma função que vai extrair os detalhes de cada deputado para isso passamos o id do deputado no endereço da url.
# Requisição dos dados detalhes dos Deputados
def detalhe_deputado(id):
url = 'https://dadosabertos.camara.leg.br/api/v2/deputados/' + id
parametros = {}
resposta = requests.request("GET", url, params=parametros)
objetos = json.loads(resposta.text)
dados = objetos['dados']
return dadosVamos chamar a função detalhe_deputado passando um id de um deputado para verificar o retorno dos dados.
detalhe_deputado('204554')Podemos ver o dicionário com todas as informações do deputado informado na função.

Vamos mensurar o tempo de resposta para a execução da função detalhe_deputado para apenas 1 id. A função time, retorna o tempo naquele momento, então criamos duas variáveis inicio_processo e fim_processo depois subtraímos o fim – inicio para obter o tempo de execução.
inicio_processo = time()
deputado = detalhe_deputado('204521')
fim_processo = time()
processamento_individual = fim_processo - inicio_processo
print('Processamento individual por id:', round( (processamento_individual), 1 ), 'segundos')
Processamento individual por id: 0.6 segundosTemos assim, um tempo médio de 0,6 segundos para cada deputado. Selecionamos os 100 primeiros ids para medir o tempo de processamento sequencial, para isso usaremos o código abaixo.
ids = id[:100]
Utilizaremos novamente a função time, como fizemos acima. E a função tqdm para monitorar o tempo de processamento em tempo real. O loop for, vai ser responsável por fazer o sequenciamento de todos os ids, e armazenaremos a resposta da API na variável lista_api, que ao final do loop, irá constar dos detalhes dos 100 deputados.
inicio_processo = time()
lista_api = []
for i in tqdm(ids):
resultado_individual = detalhe_deputado(i)
lista_api.append(resultado_individual)
fim_processo = time()
processamento_sequencial = fim_processo - inicio_processo
print('Processamento sequencial por id:', round( (processamento_sequencial), 1 ), 'segundos')
100%|██████████| 100/100 [01:02<00:00, 1.61it/s]Processamento sequencial por id: 62.2 segundosChegamos a um tempo médio de 62,2 segundos para os 100 deputados informados. Será que podemos otimizar o processamento das requisições da API?
Requisição Paralela de Dados da API com Python
A resposta para a pergunta acima, é sim!!! Faremos requisições paralelas na API com Python. Novamente, utilizaremos as funções time e tqdm para mensurar a execução. Para que o processamento aconteça de forma paralela, criaremos grupos de 10 processos com a função ThreadPool do pacote multiprocessing, informando a quantidade de processos desejada. Em seguida, com a função apply_async também do pacote multiprocessing montaremos as requisições paralelas informando qual função vamos paralelizar (detalhe_deputado). Para finalizar, precisamos aplicar a função get em cada grupo de subprocesso e salvar os dados na variável lista_api_paralela. Veja os detalhes no código abaixo:
# Subprocessos para requisição em paralelo na API
inicio_processo = time()
subprocessos = []
pool = ThreadPool(processes=10)
for i in tqdm(ids):
resultado_paralelo = pool.apply_async(detalhe_deputado, (i, ))
subprocessos.append(resultado_paralelo)
lista_api_paralela = [result.get(timeout=120) for result in tqdm(subprocessos)]
fim_processo = time()
processamento_paralelo = fim_processo - inicio_processo
print('Processamento paralelo dos id:', round( (processamento_paralelo), 1 ), 'segundos')
100%|██████████| 100/100 [00:00<00:00, 5617.20it/s]
100%|██████████| 100/100 [00:20<00:00, 4.89it/s]Processamento paralelo dos id: 20.5 segundosEntão, exibimos o resultado do processamento, que foi de 20,5 segundos para os 100 deputados. E para finalizar analisaremos os dados dos processamento e fazer um comparativo.
Analisando os Dados das Requisições em Paralelo do Python
Vamos exibir os tempos individual, sequencial e paralelo
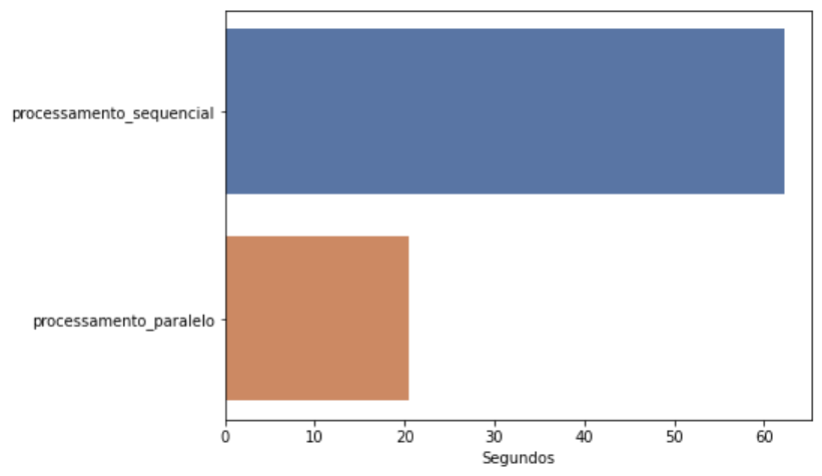
print(round( processamento_individual, 1 ), 'segundos foi o tempo de processamento de 01 requisição na API') print(round( processamento_sequencial, 1 ), 'segundos foi o tempo de processamento de 100 requisições sequenciais na API') print(round( processamento_paralelo, 1 ), 'segundos foi o tempo de processamento de 100 requisições paralelas na API') 0.6 segundos foi o tempo de processamento de 01 requisição na API 62.2 segundos foi o tempo de processamento de 100 requisições sequenciais na API 20.5 segundos foi o tempo de processamento de 100 requisições paralelas na API
Podemos observar, que o processamento paralelo utilizou apenas 34% do tempo do processamento sequencial.
print ('O processamento paralelo utilizou apenas {0:.0%}'.format(processamento_paralelo/processamento_sequencial),
'do tempo do processamento sequencial!')
O processamento paralelo utilizou apenas 34% do tempo do processamento sequencial!Podemos comparar também de forma gráfica, construímos um gráfico de barras, com a função barplot do seaborn.
# Análise comparando processamento sequencial x paralelo
x = [processamento_sequencial,processamento_paralelo]
y = ['processamento_sequencial','processamento_paralelo']
plt.figure(figsize = (7, 5))
sns.barplot(x=x, y=y, palette="deep")
plt.xlabel('Segundos')
plt.plot()Fica claro o quanto de tempo de processamento podemos otimizar utilizando o processamento paralelo com Python.
É preciso sempre avaliar o ganho de performance para implementar o processamento paralelo. Nem sempre essa pode ser a melhor opção, mas nos casos em que é uma solução, possível e viável, fica bem clara a vantagem da sua implementação. Aqui ficou claro como o paralelismo com Python foi a melhor opção!
Processamento Paralelo com Python ao Cubo
Chegamos ao final do nosso segundo artigo extraindo dados de uma API. O objetivo foi mostrar a possibilidade do processamento paralelo com Python e como ele pode ser um aliado na ingestão de dados via API. E o mais importante, tenha o paralelismo com Python uma solução alternativa para seu problema de performance.
E agora temos mais uma prova de que API com Python, o céu é o limite. O código completo você pode conferir no GitHub do Dados ao Cubo. Já vimos como fazer a ingestão de dados de uma API, utilizar processamento paralelo e para fechar persistiremos dados em um banco relacional.
Esperamos que esteja curtindo nosso conteúdo sobre API. Se gostou compartilhe, vamos para fortalecer as comunidades de dados aqui no Brasil. Não esqueça também de compartilhar seu feedback conosco, um grande abraço e até a próxima.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Bem Vindos ao Dados ao Cubo: Uma Introdução a Ciência de Dados
- Storytelling com Dash e Plotly
- Parceiro de Publicação D³
- Entre Vieses e Causalidades: Como (não) ser Enganado pelos Dados
- Deploy de Modelos com Heroku
- O Guia do XGBoost com Python
- Análise de Dados com Pandas Python
- Visualizar Dados do PostgreSQL no Metabase
Para finalizar, se torne também Parceiro de Publicação Dados ao Cubo. Escreva o próximo artigo e compartilhe conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
