

Estamos evoluindo no Business Intelligence – Do Problema Ao Dashboard. Então, chegou a hora de fazer uma introdução à linguagem SQL e aos bancos de dados relacionais. Mas até chegarmos aqui fizemos uma Introdução ao Business Intelligence – Do Problema ao Dashboard, preparação do Ambiente de Desenvolvimento para Business Intelligence e concluímos as Definições para Projetos de Business Intelligence. Então, vamos ver o que nos aguarda neste artigo.
Inicialmente veremos alguns conceitos dos bancos de dados relacionais e da linguagem SQL, em seguida, alguns comandos com a linguagem SQL e algumas consultas SQL no projeto de BI do Dados ao Cubo.
1. Bancos de Dados Relacionais
Primeiramente, vamos relembrar o conceito de banco de dados. Então, como já vimos na segunda etapa, quando apresentamos as ferramentas de bancos de dados a seguinte definição:
“Os bancos de dados nada mais são que um conjunto de arquivos reunidos com relações entre si ou não. Essa relação vai definir se são bancos relacionais ou não relacionais. A forma de relacionamento significa como os arquivos são armazenados e que tipo de arquivos são esses.”
Falando apenas dos bancos de dados relacionais, são dados estruturados em linhas e colunas. O armazenamento é feito através de tabelas com relacionamentos entre si. Essa estrutura é formalizada pelos termos: relação (tabela), tupla (linhas) e atributo (coluna).
Para ilustrar confere com um exemplo prático. Considere duas tabelas, cliente e tipo_cliente, conectadas por meio da coluna id_tipo_cliente, um relacionamento lógico. Esta relação é estabelecida pela chave primária (pk) e chave estrangeira (fk). Observe a imagem abaixo para ficar mais claro esses conceitos.

No exemplo acima, temos duas tabelas (cliente e tipo_cliente), a tabela cliente tem três colunas (id_cliente, id_tipo_cliente e nome_cliente) já a tabela tipo_cliente tem duas colunas (id_tipo_cliente e tipo_cliente). Observe que as duas tabelas tem a coluna id_tipo_cliente em comum, na tabela cliente ela é uma chave estrangeira e na tabela tipo_cliente ela é uma chave primária e forma a ligação entre as duas tabelas. Para finalizar, vamos ter os registros com as linhas de cada tabela.
Agora que já sabemos os conceitos básicos dos bancos de dados relacionais, vamos ver como manipulamos os dados dessas tabelas.
2. Linguagem SQL a Comunicação dos Bancos de Dados Relacionais

A Standard Query Language em tradução livre Linguagem de Consulta Estruturada ou simplesmente SQL (para os íntimos). É a linguagem de consulta padrão em banco de dados relacionais. Com comandos SQL é possível fazer as manipulações necessárias nos bancos relacionais. Podemos, manipular, definir e controlar dados além de controlar as transações. Vamos ver em detalhes cada uma das categorias de instruções SQL.
3. Comandos SQL
Os comandos SQL são divididos em 4 categorias de instruções. Conhecidos pelas siglas DML, DDL, DCL e TCL, vamos ver exemplos de cada uma delas.
3.1. Data Manipulation Language (DML)
Os comandos DML, são operações de manipulação de dados, vamos pensar na seguinte tabela de clientes para os exemplos dos comandos abaixo:
| id_cliente | nome_cliente |
|---|---|
| 1 | Tiago Dias |
| 2 | Dados ao Cubo |
- INSERT – Realiza a inserção de dados no banco. Vamos usar a tabela clientes para o exemplo:
INSERT INTO clientes VALUES (3, 'Tiago ao Cubo')
O que o comando faz? Insere na tabela clientes o registro (3, ‘Tiago ao Cubo’)
| id_cliente | nome_cliente |
|---|---|
| 1 | Tiago Dias |
| 2 | Dados ao Cubo |
| 3 | Tiago ao Cubo |
- SELECT – Realiza uma seleção de dados no banco. Para o exemplo vamos usar a tabela após o INSERT:
SELECT nome_cliente FROM clientes
O que o comando faz? Selecione a coluna nome_cliente da tabela clientes
| nome_cliente |
|---|
| Tiago Dias |
| Dados ao Cubo |
| Tiago ao Cubo |
- UPDATE – Realiza uma atualização de dados no banco. Exemplo:
UPDATE clientes SET nome_cliente = 'Tiago Costa' WHERE nome_cliente = 'Tiago ao Cubo'
O que o comando faz? Atualize a tabela clientes na coluna nome_cliente com o valor ‘Tiago Costa’ onde a coluna nome_cliente for igual a ‘Tiago ao Cubo’
| id_cliente | nome_cliente |
|---|---|
| 1 | Tiago Dias |
| 2 | Dados ao Cubo |
| 3 | Tiago Costa |
OBS: Muito cuidado, pois o UPDATE sem a cláusula WHERE, vai realizar uma atualização na tabela INTEIRA, se esse não for o seu objetivo defina os filtros.
- DELETE – Realiza uma deleção de dados no banco. Exemplo utilizando a tabela após o INSERT:
DELETE from clientes WHERE nome_cliente = 'Tiago Costa'
O que o comando faz? Deleta o registro da tabela clientes onde a coluna nome_cliente for igual a ‘Tiago Costa’
| id_cliente | nome_cliente |
|---|---|
| 1 | Tiago Dias |
| 2 | Dados ao Cubo |
OBS: Muito cuidado, pois para o DELETE sem a cláusula WHERE, vai deletar TODOS os dados da tabela, se esse não for o seu objetivo defina os filtros.
3.2. Data Definition Language (DDL)
Os comandos DDL, são operações de definições de dados:
- CREATE – O comando é usado para criar novas entidades (tabelas), por exemplo CREATE TABLE cria uma nova tabela, vejamos como a tabela utilizada nos exemplos acima foi criada:
CREATE TABLE clientes (
id_cliente integer ,
nome_cliente varchar(40) )O que o comando faz? Cria a tabela clientes com as colunas id_cliente (com valores do tipo inteiro) e nome_cliente (com valores do tipo texto de tamanho 40 caracteres).
- ALTER – O comando é usado para alterar as entidades existentes, por exemplo ALTER TABLE altera uma tabela existente, vamos usar a tabela criada acima para o exemplo:
ALTER TABLE clientes ADD COLUMN endereco varchar(30)
O que o comando faz? Altera a tabela clientes, adicionando uma coluna endereco (com valores do tipo texto de tamanho 30 caracteres).
- TRUNCATE – Esvaziar uma ou mais tabelas, eliminando todos os registros, vamos ao exemplo:
TRUNCATE TABLE clientes
O que o comando faz? Elimina todos os registros da tabela clientes.
- DROP – O comando é usado para deletar entidades existentes, por exemplo DROP TABLE, deleta uma tabela existente, vamos para o exemplo:
DROP TABLE clientes
O que o comando faz? Deleta a tabela clientes da base de dados.
3.3. Data Control Language (DCL)
Os comandos DCL, são operações de controle de dados:
- GRANT – Define os privilégios de acesso, vamos ao exemplo:
GRANT INSERT ON clientes TO PUBLIC
O que o comando faz? Concede privilégios a todos os usuários para a tabela clientes.
- REVOKE – Remove os privilégios de acesso, vamos ao exemplo:
REVOKE ALL PRIVILEGES ON clientes FROM tiago;
O que o comando faz? Remove todos os privilégios na tabela clientes do usuário tiago.
3.4. Transactional Control Language (TCL)
Os comandos TCL, são operações de controle de transações:
- COMMIT – Salva a transação efetuada, vamos de exemplo:
COMMIT
O que o comando faz? Efetiva a transação efetuada.
- ROLLBACK – Restaura o banco de dados para o último estado salvo, vamos ao exemplo:
ROLLBACK
O que o comando faz? Aborta todas as alterações no banco.
A sintaxe dos comandos SQL pode sofrer alguma variação de acordo com o banco de dados utilizado. Sua principal referência deve sempre ser a documentação oficial. Como estamos utilizando o PostgreSQL 13.1 Documentation, esse é o link da documentação.
Agora que vimos uma introdução bem básica da linguagem SQL. Já dá para fazer algumas consultas e começar a explorar a base de dados do projeto de BI do Dados ao Cubo.
4. Exemplos de SQL no Projeto de Business Intelligence do Dados ao Cubo
Como vimos no post anterior, no mapeamento das fontes de dados da empresa parceira Florestas ao Cubo. Identificamos que na base de dados Florestas Plantadas – IBGE – 2014-2016 temos informações sobre área de floresta plantada no Brasil por região, estados, municípios e espécie florestal. Vamos dar uma checada em algumas informações com umas consultas SQL que aprendemos por aqui.
Na figura abaixo podemos ver os detalhes de cada coluna da tabela rf_florestasplantadas_ibge, quem vai ser a base para o projeto.

Então não esquece dela, por que todas as consultas SQL que veremos a seguir, serão com base nessa tabela e suas colunas. Let’s CODE!
4.1. Contando os Registros da Tabela
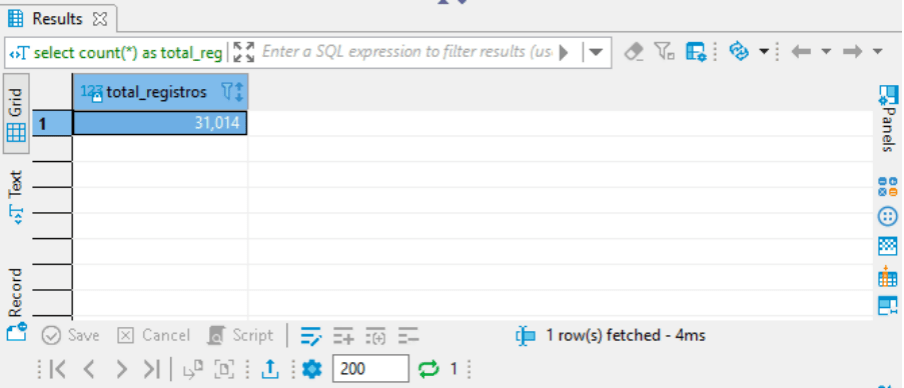
select count(*) as total_registros from rf_florestasplantadas_ibge
A função count, conta as linhas, o * quer dizer todas. Então, faz a seleção de todas as colunas, e conta o número de linhas da tabela rf_florestasplantadas_ibge.
4.2. Verificando os Valores Únicos de uma Coluna
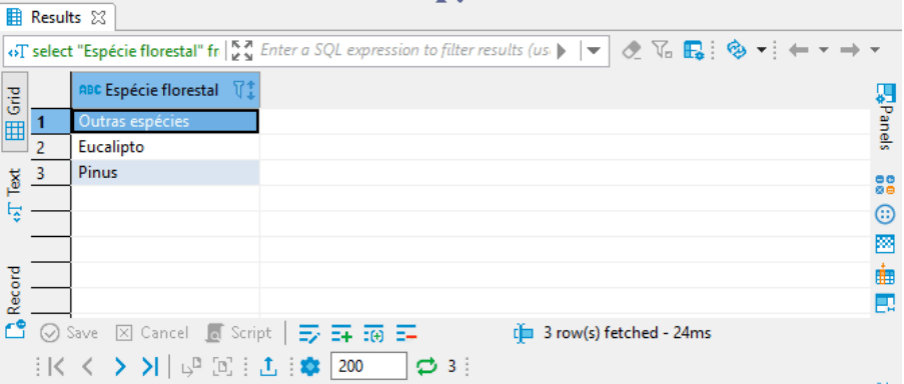
select "Espécie florestal" from rf_florestasplantadas_ibge group by "Espécie florestal"
A função group by faz um agrupamentos de registros, de acordo com os argumentos, retornando os valores únicos. Então temos, seleção da coluna “Espécie florestal” da tabela rf_florestasplantadas_ibge e agrupe as linha pela coluna “Espécie florestal”.
4.3. Consulta com Vários Filtros
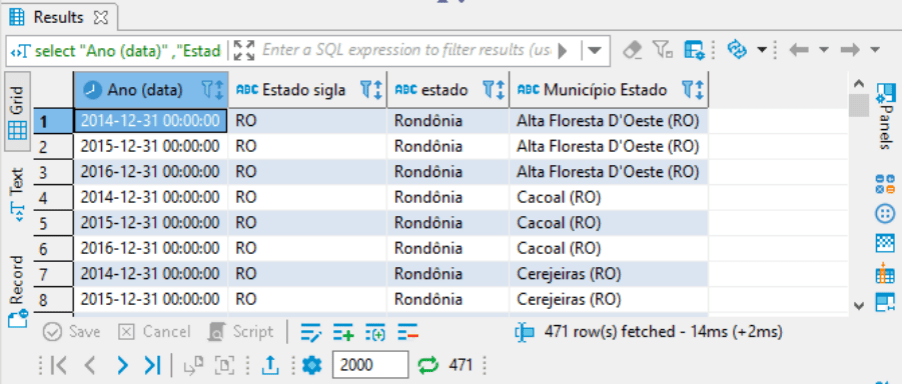
select "Ano (data)" ,"Estado sigla" ,estado ,"Município Estado" from rf_florestasplantadas_ibge where "Espécie florestal" = 'Pinus' and região = 'Norte'
A função where faz filtros, de acordo com os argumentos informados. Então vamos lá, seleção das colunas “Ano (data)” ,“Estado sigla” ,estado e “Município Estado” da tabela rf_florestasplantadas_ibge filtrando as colunas “Espécie florestal” pelo valor ‘Pinus’ e região pelo valor ‘Norte’.
4.4. Consulta Ordenando Valores
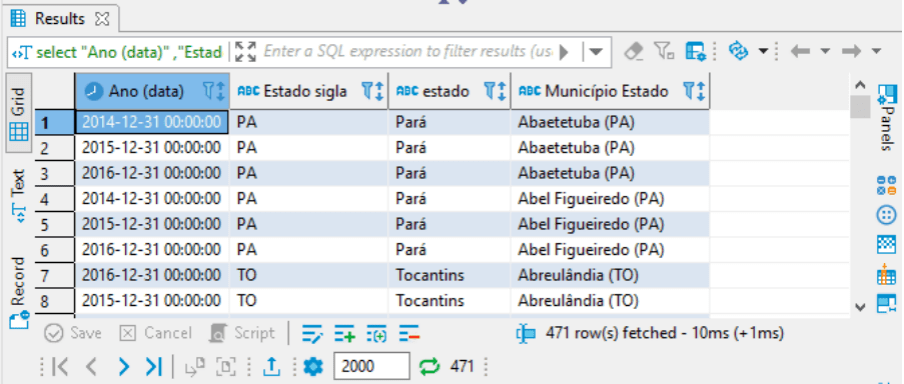
select "Ano (data)" ,"Estado sigla" ,estado ,"Município Estado" from rf_florestasplantadas_ibge where "Espécie florestal" = 'Pinus' and região = 'Norte' order by "Município Estado"
A função order by, faz a ordenação de acordo com os argumentos informados. Então, vamos usar a mesma consulta anterior, mas desta vez os registros serão ordenados pela coluna “Município Estado”.
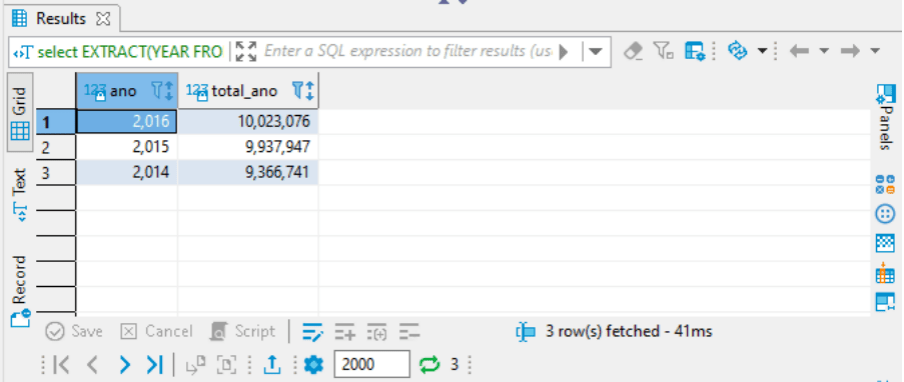
4.5. Somando Valores por Ano
select
extract(year from "ano (data)") as ano
,sum("área (ha)") as total_ano
from rf_florestasplantadas_ibge
group by extract(year from "ano (data)")A função extract retorna subvalores de um campo de data e a sum faz uma soma de valores (pode ser necessário usar uma função de agregação em alguns casos, onde soma os valores das linhas). Então temos, seleção do ano da coluna “ano (data)” e a soma da coluna “área (ha)”, da tabela rf_florestasplantadas_ibge agrupando pelo ano da coluna “ano (data)”.
E assim finalizamos mais uma etapa do Business Intelligence – Do Problema Ao Dashboard, aqui entendemos conceitos importantes dos bancos de dados relacionais e da linguagem SQL.
Bancos de Dados Relacionais ao Cubo
Portanto, após essa breve introdução de conceitos de banco de dados relacionais e da linguagem SQL, espero ter sido claro e objetivo. Por que, são conceitos importantes para projetos de BI, e vamos utilizar nas próximas etapas.
Sendo assim, se já exploramos os nossos dados de origem e eles conseguem resolver os problemas apresentados na etapa anterior, então a próxima, é fazer a modelagem desses dados. Então, espero que estejam curtindo o conteúdo de BI do Dados ao Cubo. Mas, não esqueça de curtir e compartilhar, para alcançar o maior número de pessoas que querem aprender BI. Um grande abraço e até a próxima.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Velocidade da Internet com a Biblioteca SpeedTest Python
- Reconhecimento de Voz com a Biblioteca SpeechRecognition Python
- Análise Exploratória de Dados com Python Parte I
- Análise Exploratória de Dados com Python Parte II
- Processamento de Linguagem Natural com TensorFlow
- Trabalhar com Arquivo de Texto em Python
- Análise de Dados com Scikit Learn Python
- Visualizar Dados do Snowflake no Metabase
Portanto, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
