

Fala galera do mundo dos dados! Espero que estejam todos bem e atrás de conhecimento. Vocês irão aprender aqui como criar modelos de machine learning com pipeline do scikit-learn. Isso mesmo pipeline do sklearn para os modelos. Para esta missão escolhemos o modelo do artigo NLP com scikit-learn. A ideia é transformar todo esse modelo já criado com o pipeline do scikit-learn, será uma versão 2.0.
Se você já sabe o que é NLP, confere o artigo lá para entender a solução 1.0. Mas se está começando agora e não sabe esses conceitos, vai lá que além de conhecer a solução anterior tem alguns conceitos fundamentais que vamos utilizar aqui.
- O que é NLP?
- Para que serve a função CountVectorizer?
- O que faz a função TfidfTransformer?
- Como avaliamos o modelo?
Mas se quiser só entender o funcionamento de um pipeline do scikit-learn, aperte o cinto e vamos nessa!
Relembrando o Problema
Primeiramente, vamos dar uma relembrada geral de qual problema de negócio que vamos resolver aqui. A partir de uma base de dados mercadológica onde temos itens classificados por departamento, treinaremos o algoritmo para classificar novos produtos com os departamentos conhecidos.
Para isso utilizaremos algumas técnicas que são utilizadas para NLP. Construiremos um pipeline para deploy do modelo.
Porque Criar Modelos com Pipeline do Scikit-Learn
O objetivo do pipeline é reunir as várias etapas do processo, que podem ser validadas de forma cruzada ao definir parâmetros diferentes. Além de tornar o código mais simples e otimizar o deploy do modelo. Sendo assim, facilita desde o entendimento da solução, bem como a manutenção do código no futuro.
Pipeline do Scikit-Learn ao Cubo
Daremos início ao processo de criação do do modelo baseado no pacote Scikit-Learn ou sklearn como também é chamado. O primeiro passo é importar as bibliotecas necessárias, então vamos ao código Python.
Importando Bibliotecas
Aqui importaremos várias funções do da bibliotecas sklearn, para transformação dos dados, para criar o classificador e para construir o pipeline no sklearn. Além do sklearn, vamos também importar a biblioteca pandas, que vai auxiliar na leitura dos dados.
# lib para leitura dos dados import pandas as pd # funções transformação dos dados para input do modelo from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer # modelo de classificação from sklearn.svm import LinearSVC # funções para construção do pipeline from sklearn.pipeline import Pipeline from sklearn.base import BaseEstimator, TransformerMixin
Com as bibliotecas importadas, podemos seguir para o próximo passo, e carregar o dataset.
Carregando Dataset
Nesta etapa, o processo é bem simples, com a função read_csv, passamos o caminho do arquivo com os dados, e então, já temos o dataframe pandas carregado.
df = pd.read_csv('https://raw.githubusercontent.com/dadosaocubo/nlp/master/base_mercadologica.csv')Agora com os dados carregados, realizaremos a definição das stop words, que vão ser utilizadas na transformação dos dados mais na frente.
Stop Words
Mas afinal, o que são stop words? São palavras que podemos remover para facilitar a análise do texto, não existe uma regra universal, vai depender muito de cada problema.
Para o nosso problema, colocaremos algumas palavras muito comuns em bases mercadológicas, por exemplo: pct, kg, pt e und. A lista completa pode conferir no código abaixo.
stop_words = ['em','sao','ao','de','da','do','para','c',
'kg','un','ml','pct','und','das','no','ou',
'pc','gr','pt','cm','vd','com','sem','gfa',
'jg','la','1','2','3','4','5','6','7','8',
'9','0','a','b','c','d','e','lt','f','g',
'h','i','j','k','l','m','n','o','p','q',
'r','s','t','u','v','x','w','y','z']No próximo passo vai começar a brincadeira do nosso pipeline no sklearn. Criamos uma função de transformação dos dados para utilizar no pipeline.
Criando uma Função de Transformação
Primeiramente, vamos entender o que fazem as duas funções: BaseEstimator, TransformerMixin.
- BaseEstimator: Classe base para todos os estimadores no scikit-learn.
- TransformerMixin: Classe Mixin para todos os transformadores no scikit-learn.
Então, temos uma classe para os estimadores e uma para os transformadores. A partir delas vamos criar uma classe que vai realizar uma transformação nos dados conforme a sua necessidade. Ao criar esse classe derivada, ela vai herdar o que precisamos para realizar um fit/transform sobre os dados de input.
Nessa classe criada teremos 2 funções: fit e transform.
- fit: retornará self, assim permite pipeline fit e transform imposto pela função de transform.
- transform: Aqui está o core da transformação, receberá o input X e retornará esses dados transformado. Aqui usaremos expressão regular para remover: pontuação, caracteres especiais e números.
# Um transformador para colunas
class TColumns(BaseEstimator, TransformerMixin):
# Função de fit ds dados de entrada
def fit(self, X, y=None):
return self
# Função de transformação dos dados de entrada
def transform(self, X):
# Primeiro realizamos a cópia do DataFrame 'X' de entrada
data = X.copy()
data['descricao'] = data['descricao'].str.replace('[,.:;!?]+', ' ', regex=True).copy()
data['descricao'] = data['descricao'].str.replace('[/<>()|\+\-\$%&#@\'\"]+', ' ', regex=True).copy()
data['descricao'] = data['descricao'].str.replace('[0-9]+', '', regex=True)
# Retornamos um novo dataframe com as colunas
return data.descricaoCom a função de transformação customizada criada, partiu para o pipeline do modelo com sklearn.
Definindo o Pipeline do Modelo de Machine Learning
Finalmente o pipeline com sklearn! Criaremos a instância de cada etapa, e no final incluiremos todas elas no pipeline.
O pipeline construído, possui 4 etapas: tco (Transformador de colunas customizado, que criamos anteriormente, cvt (Transformador de textos em vetores numéricos), tfi (Transformador dos vetores numéricos usando a função estatística Tf-idf) e clf (Modelo de classificação do tipo LinearSVC).
# Criando uma instância do transformador das colunas
tco = TColumns()
# Criando uma instância do CountVectorizer
cvt = CountVectorizer(strip_accents='ascii', lowercase=True, stop_words=stop_words)
# Criando uma instância do TfidfTransformer
tfi = TfidfTransformer(use_idf=True)
# Criando uma instância do modelo LinearSVC
clf = LinearSVC()
# Criando a Pipeline, adicionando o nosso transformador seguido de um modelo de classificação
skl_pipeline = Pipeline(steps=[('Transformer', tco),
('CountVectorizer', cvt),
('TfidfTransformer', tfi),
('Model', clf)])Agora que temos o modelo com sklearn pronto, partiu treinamento.
Treinando o Modelo
Para treinar o modelo do pipeline, utilizaremos a função fit, passando o input definido como a variável entrada e a variável target (label do classificador) definida como a variável saida.
E então, o que acontece no pipeline? Por debaixo dos panos é executado cada etapa (step) do pipeline, na ordem definida: 1 – Transformer, 2 – CountVectorizer, 3 – TfidfTransformer e 4 – Model. Dessa forma, é armazenado na variável skl_pipeline toda essa lógica para ser utilizada na função predict e realizar a classificação de novos inputs.
# Executando Pipeline entrada = df[['descricao']] saida = df['departamento'] skl_pipeline.fit(entrada, saida)
E agora? Só correr para o abraço e utilizar o modelo criado. Cabe lembrar, que uma etapa muito importante não foi apresentada aqui, a avaliação do modelo. Isso porque é uma evolução do modelo criado no artigo NLP com sklearn, no qual fizemos toda essa análise e você pode conferir esses detalhes por lá.
Utilizando o Modelo
Finalizando com um loop para obter a classificação dos produtos a partir do modelo criado no pipeline do sklearn. Lógica bem simples, solicita para o usuário informar o item ou -1 para encerrar a aplicação. Com o input do usuário, transformamos em um dataframe para servir de input ao modelo e utilizamos a função predict para obter a resposta, em seguida exibimos a classificação na tela do usuário.
# loop para utilização do pipeline
fim = '0'
while (fim != '-1'):
descricao = input('Informe o item para classificar ou -1 para encerrar o programa: ')
fim = descricao
if fim != '-1':
df_predict = pd.DataFrame([descricao], columns=['descricao'])
print('O item {} está na seção {}\n'.format(descricao.upper(), skl_pipeline.predict(df_predict)[0]))
else:
print('Obrigado! Volte sempre!!!')Na figura abaixo temos um exemplo da aplicação rodando. E logo podemos observar, que o mundo não é só flores. Temos vários itens classificados corretamente, mas para um nome de significado ambíguo ele se perde, mas o próprio português apronta dessa com a gente. Quem nunca confundiu um item do mercado pelo nome que deixe o primeiro comentário hahaha.
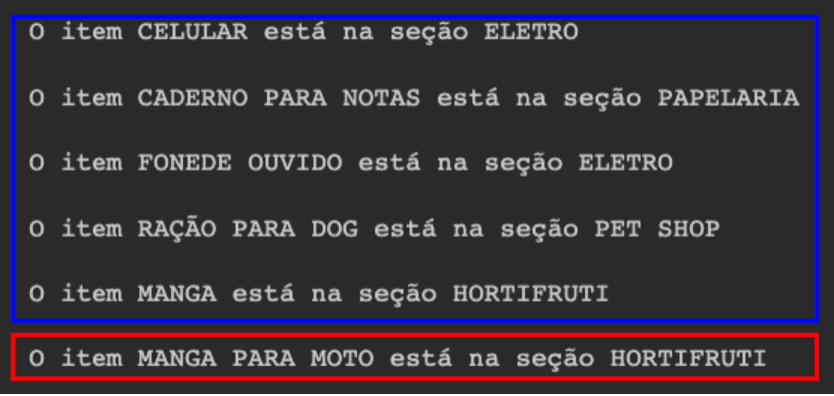
E então finalizamos a construção do pipeline sklearn para um modelo de machine learning.
Pipeline do Sklearn ao Cubo
Portanto, aprendemos a construir com a biblioteca sklearn um pipeline para um modelo de machine learning. Sendo assim, relembramos a construção de um modelo de machine learning para fazer o deploy do modelo em um pipeline do sklearn.
Assim concluímos o conteúdo de hoje, espero que curtam bastante! Compartilha com os amigos, utilizem o código para resolver o seu problema de classificação (se fizer sentido claro). E aquele feedback sempre bem vindo para a gente continuar produzindo os melhores conteúdos para vocês. No GitHub do Dados ao Cubo você encontra o notebook completo, um abraço e até a próxima.
Conteúdos ao Cubo
Se curtiu, lá no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar por lá, sempre falando sobre o mundo dos dados.
- Linguagem de Programação Python do Zero
- Manipulando Dados em PostgreSQL com Python
- Análise Exploratória de Dados com Python Parte I
- Modelos em Produção com Streamlit
- Classificação com scikit-learn
- ETL com Pentaho
- Visualização de Dados com Plotly Python
- Tableau + Python = PyGWalker
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Mas, não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
