

Fala galera do mundo dos dados! Dessa vez, o estudo é sobre modelos de machine learning com scikit-learn. Escrevi alguns artigos aqui no Dados ao Cubo, onde trago um pouco de teoria e muita prática. São quatro artigos que abordam regressão, classificação, NLP e agrupamento, todos utilizando a linguagem Python. Ficou interessado? Vem comigo conferir.
Sobre a biblioteca scikit-learn, ela é uma lib de Machine Learning para Python e temos a seguinte definição da própria biblioteca:
“Scikit-learn é uma biblioteca de aprendizado de máquina de código aberto que oferece suporte ao aprendizado supervisionado e não supervisionado. Ele também fornece várias ferramentas para ajuste de modelos, pré-processamento de dados, seleção de modelos, avaliação de modelos e muitas outras utilidades.”
Dessa forma, ela é utilizada por toda a comunidade, seja para estudos ou profissionalmente. Muito bem documentada e com uma vasta quantidade de exemplos na própria documentação. Ela disponibiliza algoritmos de regressão, classificação, clusterização, pré-processamento de dados e ainda construção de modelos de ML com pipelines.
E aí? Para quem tá começando em machine learning, a scikit-learn é um verdadeiro parque de diversões! Então, sem mais delongas, vamos ao que interessa.
Regressão com scikit-learn
Aqui você vai compreender que a regressão linear pode ser definida pela estatística como uma equação que busca estimar o(s) valor(es) de y, dados uma ou mais variáveis x. Então temos a seguinte fórmula matemática que exemplifica essa teoria.
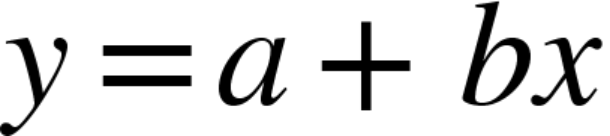
Assim y é a variável dependente de x, a é o coeficiente linear e b é o coeficiente angular. Mas calma que não é tão difícil quanto parece, na prática é bem mais simples.
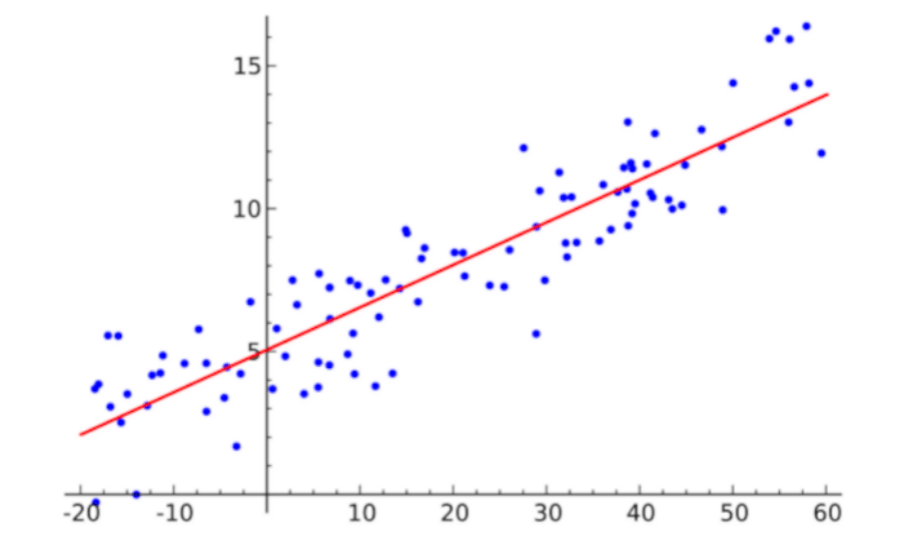
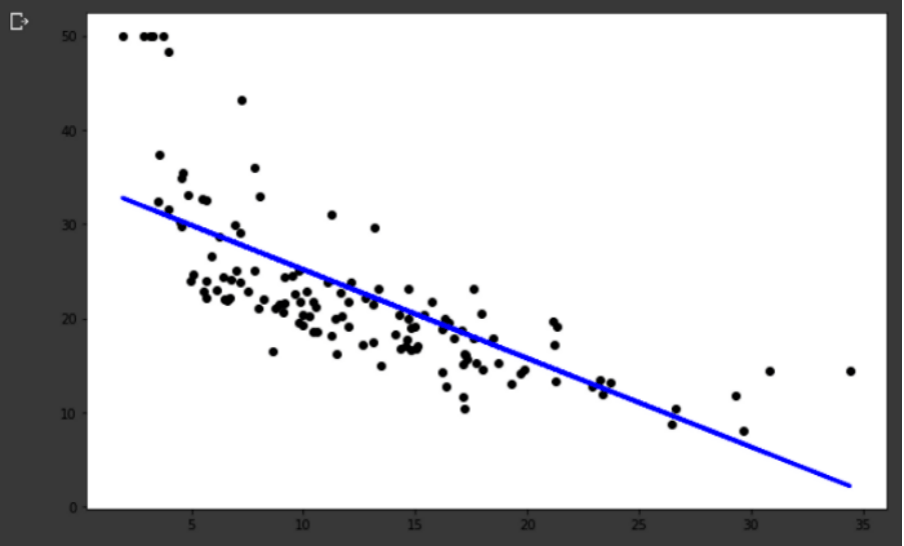
E para isso utilizaremos o famoso dataset com os preços de casas em Boston (Boston house prices), disponível na própria biblioteca do scikit-learn através da função load_boston. Aí é só alegria, criaremos um código Python para carregar e visualizar esse conjunto de dados. Depois para criar e avaliar o modelo de regressão criado e ao final veremos o resultado do nosso modelo conforme imagem abaixo.
Classificação com scikit-learn
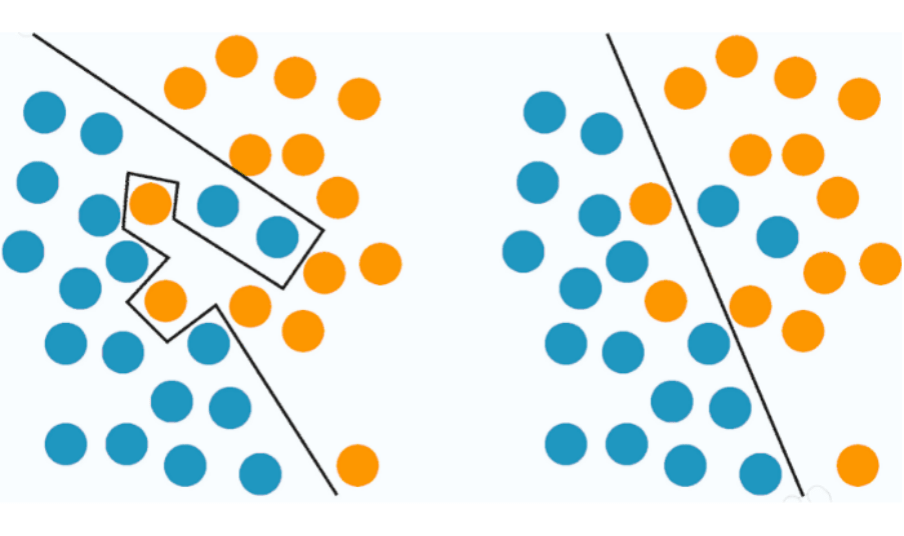
Outro problema clássico resolvido com machine learning é a classificação. De uma forma resumida é uma tarefa de atribuição de classe dada uma observação de dados.
Vejamos, se temos um conjunto de dados, cada exemplo que temos seria uma observação. Já a classe desse exemplo seria a classificação do mesmo. Por exemplo, se temos um conjunto de fotos de gatos e cachorros, e queremos fazer a classificação das fotos que são gatos. Cada foto será uma observação e a nossa classe será gato. Para resolver o nosso problema vamos classificar cada observação em positiva e negativa (O que vai ser positivo e negativo depende da narrativa do problema). Portanto temos uma classificação binária.
Mas poderia ter outro tipo de classificação? Claro, pegamos o mesmo problema acima e acrescentamos fotos de coelho. Assim, podemos ter um novo problema e queremos fazer a classificação por animal. Neste caso temos 3 classes de animais para fazer a classificação, gato, cachorro e coelho. Dessa forma teríamos uma classificação multiclasse.
Para trazer esses conceitos para o mundo prático, temos o problema clássico onde temos 3 espécies da flor íris para fazer sua classificação dada algumas de suas características.
Então, veremos como avaliar modelos de classificação e quais são as métricas mais utilizadas. Em seguida, como lidar com dados desbalanceados, algo muito comum em problemas de classificação. E finalizamos com a criação de alguns modelos, o que vai nos permitir a comparação e escolha do melhor modelo.
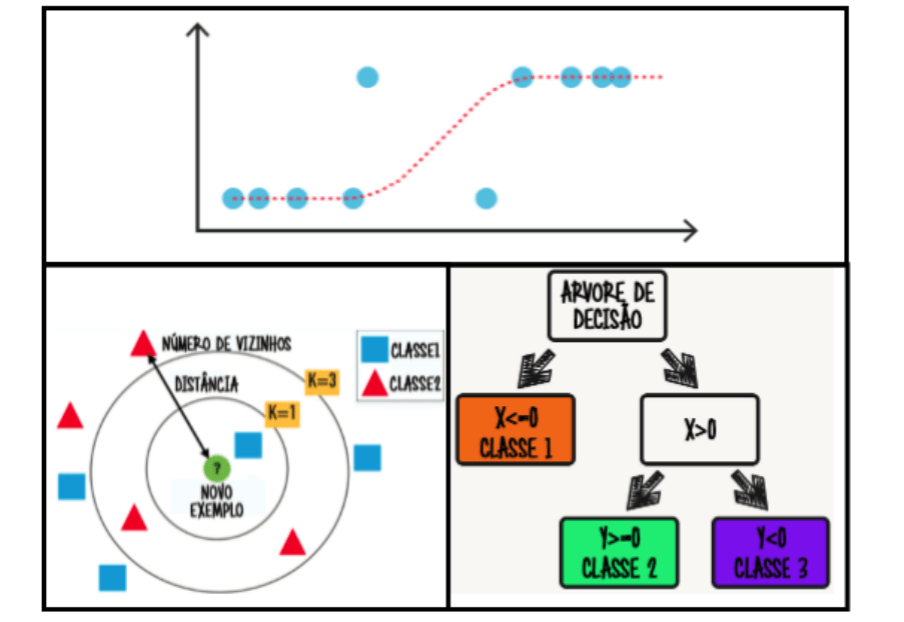
NLP com scikit-learn

Esse tema é conteúdo para muitos livros. Mas vou tentar te introduzir no tema de uma forma bem objetiva.
O processamento de linguagem natural ou NLP é a área de estudo que busca fazer com que a máquina possa compreender e simular a linguagem humana. Em outras palavras, é fazer o computador receber uma frase e ter uma “opinião” sobre ela.
Na ciência de dados e inteligência artificial a NLP tem áreas de estudos específicas, além disso é tratada com muito carinho pois é a chave para resolução de muitos problemas atuais. As soluções vão desde classificação de textos, até soluções mais complexas de análises de sentimentos.
Chatbots e assistentes virtuais são outras soluções que estão em alta relacionadas a NLP. Os chatbots podem ter soluções simples, como respostas prontas relacionadas a um manual técnico de instruções, até soluções mais complexas de interações de diálogos com seres humanos, como o famoso Watson da IBM. Dessa mesma forma estão os assistentes virtuais com reconhecimento de voz e interações dos mais diversos temas, por exemplo, a Siri do iPhone ou a Alexa da Amazon.
Aqui criaremos uma solução de NLP com scikit-learn. A partir de uma base de dados mercadológica onde temos itens classificados por departamento, treinaremos o algoritmo para classificar novos produtos com os departamentos conhecidos.
Para que isso seja possível veremos algumas técnicas que são utilizadas para NLP. Construiremos um processo para chegar a solução desse problema, utilizando a linguagem python. Confere que a solução ficou TOP!

Agrupamento com scikit-learn

E para fechar com chave de ouro, o assunto será clusterização, também conhecido como agrupamento.
O modelo de agrupamento ou clusterização, nada mais que a divisão dos dados em grupos, que pode ser definido também como clusters. Essa separação dos dados se dá devido às características dos mesmos, ou seja, dados com características semelhantes tendem a ficar juntos.
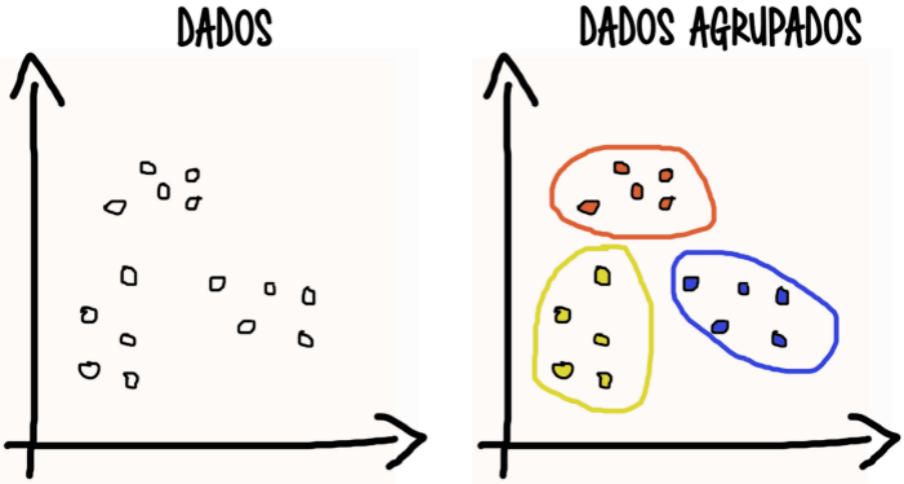
Aí vou te apresentar os 3 tipos mais comuns: os grupos exclusivos, sobrepostos e hierárquicos. Depois o k-means, um algoritmo que separa os dados k grupos e as observações vão se agrupar ao k mais próximo da sua distância média. E finalizando com algumas métricas para avaliar o modelo criado.
Sucesso em? Em cada tópico você encontra o link para o conteúdo completo de cada modelo! Depois me conta o que achou? O que faltou? O que não gostou? Um abraço e até a próxima.
Conteúdos ao Cubo
Se você curtiu o conteúdo, lá no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar por lá, sempre falando sobre o mundo dos dados.
- Boas Práticas de Visualização de Dados Parte I
- Boas Práticas de Visualização de Dados Parte II
- Machine Learning com ML.Net no Jupyter Notebook
- Análise Exploratória com ML.Net e Jupyter Notebook no Ubuntu
- ML.Net – Modelos em Produção com WebApi e Docker
- AutoML (Automated Machine Learning) com ML.Net
- Extraindo Dados do Twitter com Python
- Pipeline de Dados Airbyte com PostgreSQL
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo, escrever o próximo artigo e ter divulgação para toda a comunidade de dados no LinkedIn.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
