

Fala galera do mundo dos dados!!! Tudo belezinha com vocês? Espero que sim! Vamos de conteúdo novo? Hoje vocês vão aprender a extrair dados do Twitter com Python! Será que essa rede social tem muito a nos oferecer? Será que o Python deixa essa atividade simples? Vou te mostrar como consumir os dados direto da API do Twitter com Python!
Fica tranquilo, que vamos ter o código no detalhe, comentado passo a passo. Assim, você pode modificar conforme sua necessidade. Fica a vontade para usar e compartilhar o nosso conteúdo. Então, vamos ao que interessa, começando a conhecer um pouco mais dessa rede social.
O que o Twitter?
Segundo o próprio Twitter, ele se define como “O melhor lugar para ver o que está acontecendo em seu mundo.”
A rede social de 15 anos é uma das plataformas mais influentes do mundo. Conta com mais de 1,3 bilhões de contas, das quais cerca de 335 milhões de usuários ativos por mês. Os usuários são assíduos onde cerca de 46% usam o site diariamente.
Falando em dados, temos cerca de 456 mil Tweets enviados por minuto, ou seja, cerca de 656 milhões de Tweets por dia. Muitos dados para analisar em? Um verdadeiro parquinho!
Você pode encontrar esses e outros números sobre o Twitter em Estatísticas e Fatos do Twitter Sobre a Nossa Rede Favorita (2021).
Biblioteca Python Tweepy
A Tweepy é uma biblioteca Python de fácil utilização para acessar a API do Twitter. Com ela é possível acessar os dados do Twitter de forma simples e via códigos Python.
Como por exemplo, exibir os trend topics, ou pesquisar sobre algum conteúdo específico. E tudo isso nós vamos ver aqui neste artigo. Mas a lib tem muitas outras possibilidades, confira a documentação oficial. Agora, já podemos brincar na API do Twitter com nossos códigos Python.
Twitter ao Cubo
Agora veremos como extrair dados do Twitter, abaixo as bibliotecas que vamos utilizar ao longo do desenvolvimento. O pacote geocoder auxiliará a obter informações geográficas de uma localidade, como latitude e longitude. Já o pacote toml será necessário para não deixar as credenciais de acesso expostas no código. O tweepy, é o dono da festa, acessará a API do Twitter. Por fim, o json e o pandas auxiliarão na manipulação dos dados.
Importando Bibliotecas
Primeiramente, importar todas as bibliotecas que iremos utilizar para extrair dados do Twitter com Python.
import geocoder import toml import tweepy import json import pandas as pd
Com as bibliotecas importadas, podemos começar. Veremos o arquivo que contém as credenciais de acesso ao Twitter.
Arquivo com as Chaves de Acesso ao Twitter
Precisamos de cinco informações para acessar os dados do Twitter. O nome do app, a chave de acesso e chave secreta do usuário e os tokens de acesso e token secreto do app.
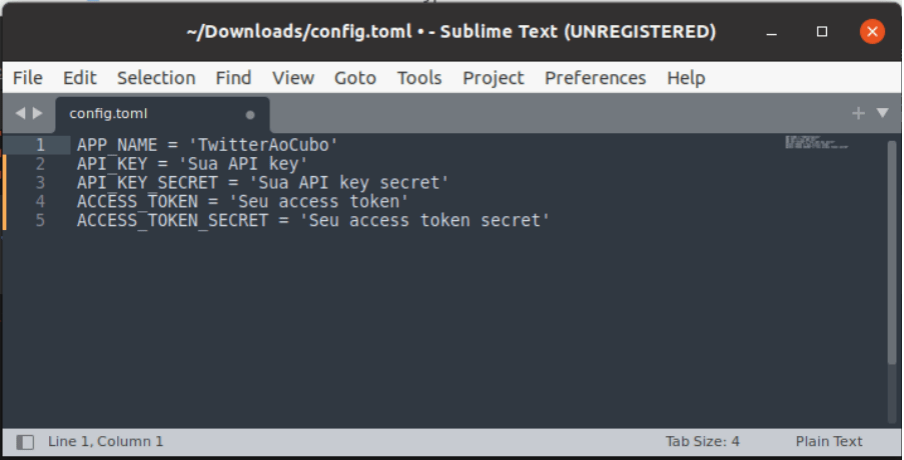
Configuramos tudo no arquivo acima para não ficarem expostos esses dados no código. Esses são dados confidenciais e dão acesso aos seus dados do Twitter.
Assim, podemos ler o arquivo e guardar todas as informações nas variáveis abaixo.
# abrir o arquivo com as credenciais de acesso
with open('config.toml') as config:
# ler o arquivo e salvar as chaves nas variáveis
config = toml.loads(config.read())
APP_NAME = config['APP_NAME']
API_KEY = config['API_KEY']
API_KEY_SECRET = config['API_KEY_SECRET']
ACCESS_TOKEN = config['ACCESS_TOKEN']
ACCESS_TOKEN_SECRET = config['ACCESS_TOKEN_SECRET']Com todas as chaves e tokens configurados vamos fazer a autenticação na API do Twitter.
Autenticando no Twitter com Python
A função OAuthHandler faz a autenticação das chaves de usuários, depois passamos os tokens com a função set_access_token e por fim passamos os dados na função API.
# função para autenticação do usuário auth = tweepy.OAuthHandler(API_KEY, API_KEY_SECRET) # função para acesso ao app com os tokens auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) # autenticação na API do Twitter api = tweepy.API(auth)
Com a autenticação na API realizada já podemos consultar os top trends.
Top Trends Twitter com Python
Primeiramente, precisamos verificar as localização disponíveis para o trends com a função trends_available.
# Verificando as localizações disponíveis para o trends available_loc = api.trends_available() df = pd.json_normalize(available_loc) df.head(3)
O resultado está sendo exibido no formato de dataframe, onde a coluna name são as localizações disponíveis.

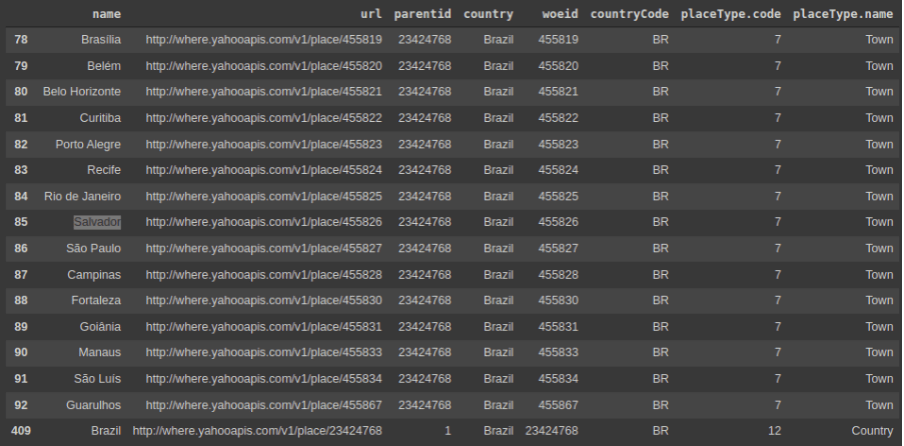
Fazendo um filtro nos dados, apenas no Brasil, temos quase todas as capitais disponíveis para consulta de trends topics.
# Filtrando Brasil nas localizações disponíveis
df.query('country == "Brazil"')Abaixo o resultado detalhado da consulta acima.
Lembra da lib geocoder? Utilizaremos ela para conseguir os dados de lat e long do Brasil.
# Definindo a localização
loc = geocoder.osm('Brazil')
print(loc)
<[OK] Osm - Geocode [Brasil]>Através da função trends_closest, vamos identificar o ID e assim conseguir os trends topics daquela localização.
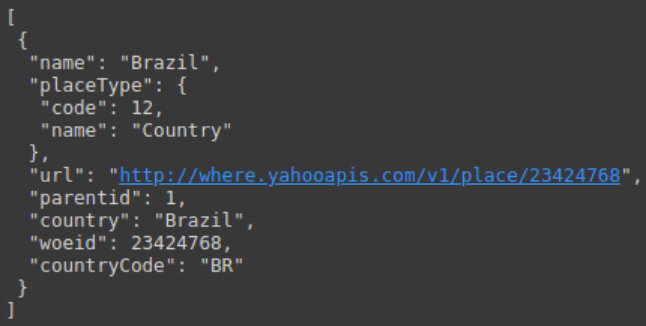
# Buscando o id da localização baseado na lat e long closest_loc = api.trends_closest(loc.lat,loc.lng) print(json.dumps(closest_loc,indent=1))
Observe abaixo a resposta da função trends_closest no formato JSON.
Com o ID do campo woeid, chamamos a função trends_place e então temos os trends topics daquela localização.
# Montando dataset do Top trends da localização informada trends = api.trends_place(closest_loc[0]["woeid"])
Por fim, só precisamos estruturar os dados em um dataframe.
# Exibindo os Top Trends Brasil df_trends = pd.json_normalize(trends[0]['trends']) df_trends.head()
E então, temos o Top 5 assuntos mais comentados no Twitter no momento que escrevo esse post para vocês.

Muito bom em!!! Mas Tiago, só o assunto é pouco, quero os detalhes kkkkk!!! Então vamos lá extrair os tweets do assunto desejado.
Extraindo Dados do Twitter com Python
Para tal atividade, utilizaremos a função search, onde passamos uma string e ela retorna os tweets sobre determinado assunto. Então, o assunto do momento é o Cuca.
# Realizando uma busca de dados pelo Top Trend
results = api.search(q='Cuca')
# Organizando os dados
users = []
tweets = []
for tweet in results:
users.append(tweet.user.name)
tweets.append(tweet.text)
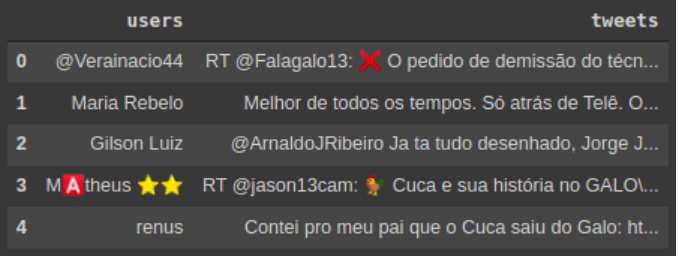
print(f'User: {tweet.user.name} | Tweet: {tweet.text}')Separamos os resultados em duas listas: users e tweets, que contêm o nome do usuário e texto do tweet respectivamente. Resultado exibido na imagem abaixo.
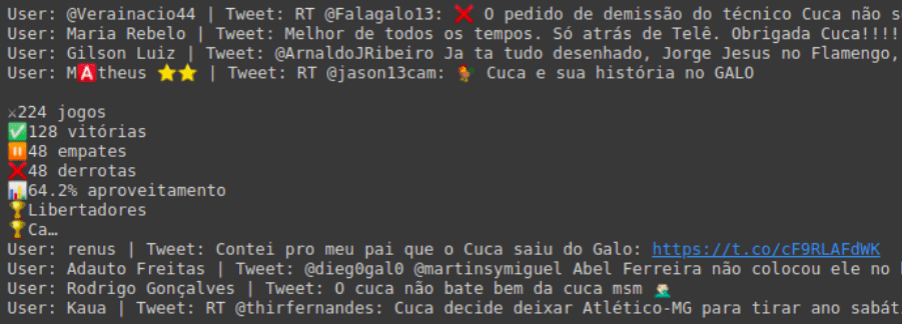
Para trabalhar melhor os dados acima, podemos estruturar em um dataframe pandas para fazer a análise que desejarmos.
# Montando um dataset com os tweets extraidos do Twitter df_tweets = pd.DataFrame() df_tweets['users'] = users df_tweets['tweets'] = tweets df_tweets.head()
Olha o nosso resultado!!! Agora é só começar a se divertir.
E então, chegamos ao fim de como extrair dados direto da API do Twitter utilizando o Python.
Dados do Twitter com Python ao Cubo
Portanto, vimos como brincar como os dados do Twitter com Python. Sendo assim tivemos exemplos de como autenticar no Twitter, como extrair o top trends e o tweets direto da API do Twitter.
Por hoje é somente tudo isso! Se você curtiu o conteúdo do Dados ao Cubo, não deixe de compartilhar, de mandar o seu comentário, sugestão, crítica e o que mais desejar. Um forte abraço e até a próxima.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Como Criar um Chatbot com Rasa Open Source
- Analisando Dados do LinkedIn
- Velocidade da Internet com a Biblioteca SpeedTest Python
- Reconhecimento de Voz com a Biblioteca SpeechRecognition Python
- Analisando Dados do Brasileirão Série A
- Inserir Dados com Streamlit e o PostgreSQL
- Visualização de Dados com Altair Python
- Pipeline de Dados Airbyte com PostgreSQL
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Mas, não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀

3 Comments
MIlton Sergio do Nascimento
15 de dezembro de 2022api.trends_available() , tem erro nessa linha:AttributeError: ‘API’ object has no attribute ‘trends_available’
Tiago Dias
16 de dezembro de 2022Obrigado Milton, vou verificar o erro!
Tiago Dias
16 de dezembro de 2022https://docs.tweepy.org/en/stable/api.html#tweepy.API.available_trends
Changed in version 4.0: Renamed from API.trends_available
Precisa verificar a versão, para utilizar a função correta!
Vlw pelo comentário Milton!!!