

Fala galera fascinada por dados! Espero que estejam todos bem e se cuidando. Sabia que o LinkedIn é um parquinho para fazer uma análise de dados? É isso mesmo, você pode solicitar os seus dados na plataforma e aí é só alegria.
Para quem não conhece o LinkedIn, vou apresentar e em seguida vou mostrar como solicitar os dados. e aí #PartiuCode com uma análise TopZeira das conexões de Tiago Dias, eu mesmo que vos escrevo.
O que é o LinkedIn?
O LinkedIn é uma rede social profissional, onde os usuários cadastram o seu perfil profissional e podem compartilhar informações com a rede. O network profissional é uma das grandes vantagens da rede. É possível fazer conexões com usuários do mundo todo. São mais de 750 milhões de usuários em mais de 200 países e territórios em todo o mundo. Uma ótima chance de compartilhar conhecimento que agregue valor para os profissionais.
Imagina mapear o perfil das suas conexões, identificar as empresas que estão mais presentes no seu network e ainda os períodos de maior aumento de contatos. São alguns dos insights que podemos obter com os dados lá disponíveis. Pense que você pode identificar se as suas conexões fazem sentido para o seu futuro profissional. Mas como conseguir esses dados para fazer alguma análise. Fácil, se liga.
Como Solicitar seu Dados no LinkedIn?
Acessando as configurações e privacidade do seu perfil. Você pode navegar até a aba de Privacidade dos dados > Obtenha uma cópia dos seus dados. Confere a tela abaixo:
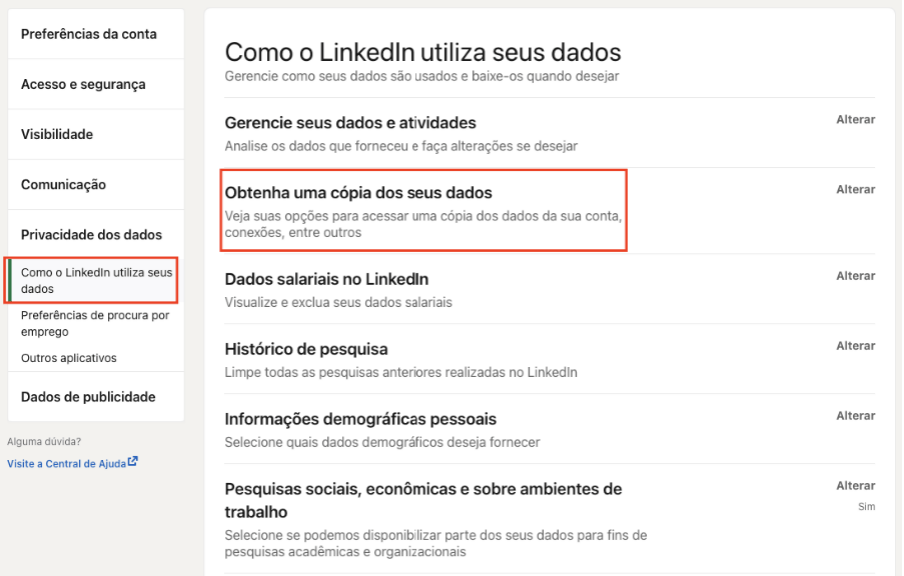
Em seguida, basta solicitar o arquivo, que pode ser completo ou apenas algo em particular. Como pode ver na imagem abaixo:
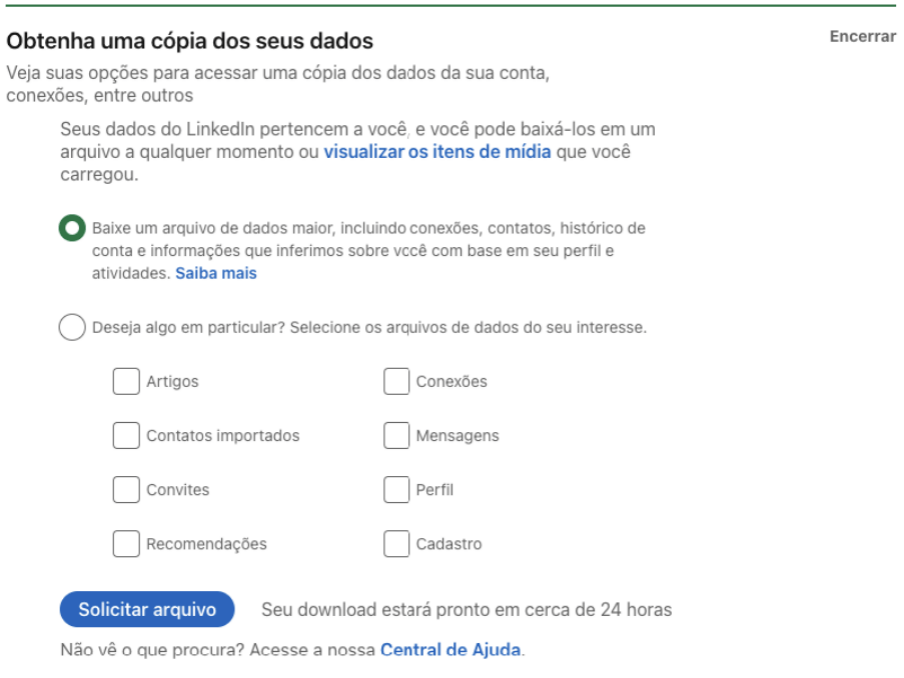
Após efetuar o download, temos o parque de diversões abaixo. Os dados representam todo o seu perfil na rede.
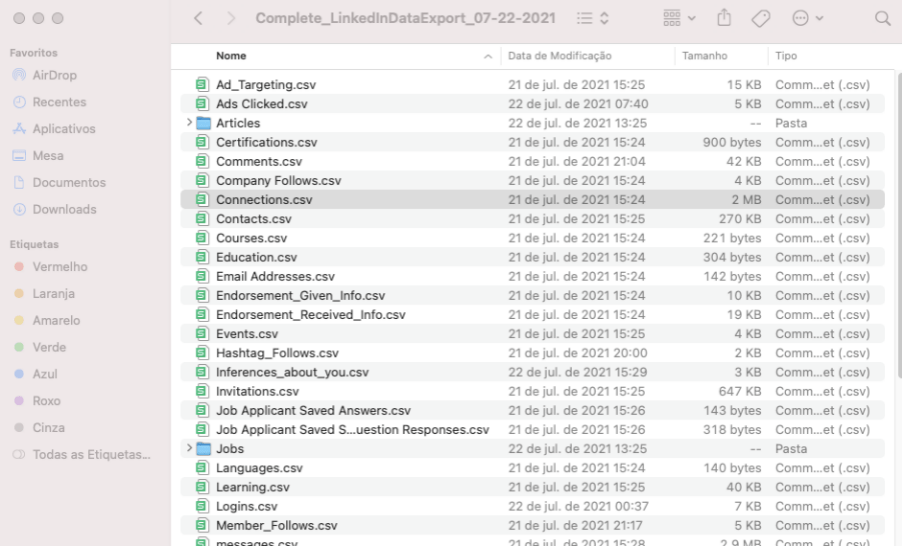
Para a análise que será feita aqui, utilizaremos apenas o arquivo Connections.csv, conforme seleção acima. Este arquivo contém informações sobre as suas conexões. Então, vamos para a melhor parte Python na veia.
Partiu Explorar Dados do LinkedIn
A tarefa de hoje é fazer uma exploração de dados do LinkedIn. Sendo assim, como parte do processo, vai haver alguns tratamentos nos dados, criação de algumas novas colunas e por fim a visualização desses dados de forma gráfica. A primeira etapa envolve o uso das bibliotecas.
Importando Bibliotecas
Como em todo código Python, é necessário importar as bibliotecas que serão utilizadas no desenvolvimento da aplicação.
import pandas as pd import random, string import matplotlib.pyplot as plt import seaborn as sns from wordcloud import WordCloud
No código acima temos a biblioteca pandas para carga e tratamento de dados. Em seguida as bibliotecas random e string para geração de string aleatórias (vamos gerar códigos aleatórios para o id das pessoas). Para finalizar, três bibliotecas gráficas matplotlib, seaborn e wordcloud, que servirão para construção dos gráficos. Podemos seguir para carga dos dados.
Importando Dados do LinkedIn
Os dados das conexões estão em um arquivo csv, e serão carregados com a função read_csv.
df = pd.read_csv('Connections.csv')Normalmente, quase sempre, após a carga dos dados utilizando a função head para exibir as primeiras linhas e verificar se os dados foram carregados corretamente. Mas, por estar analisando dados sensíveis, com dados pessoais, então, pularemos essa etapa pelo menos neste momento.
Dados Sensíveis e a LGPD
Com a vigência da lei geral de proteção de dados (LGPD), todos devem estar atentos aos dados sensíveis, ao tratamento e cuidado com os mesmos. Aqui na nossa análise dos dados do Linkedin não vai ser diferente, com auxílio da função info, podemos verificar quais colunas contêm dados sensíveis.
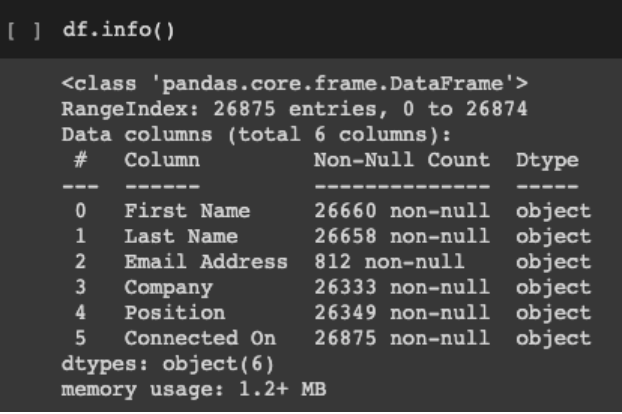
Sendo assim, vamos eliminar estas colunas do nosso dataframe, são elas: Nome, Sobrenome e Email.
# Devido a LGPD, vamos ocultar informações pessoais df.drop(columns=['First Name','Last Name','Email Address'], inplace=True) df.head()
Agora sim podemos usar a função head e visualizar os dados que foram carregados.
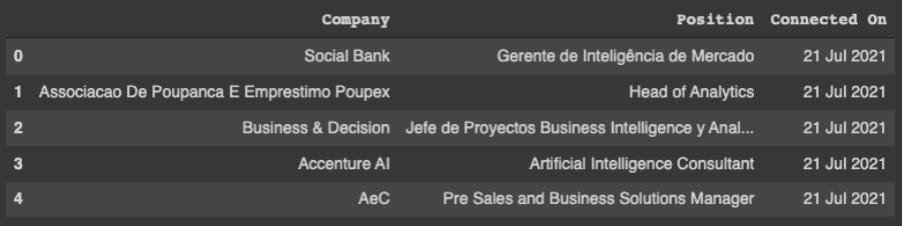
Como apagamos todos os dados pessoais, vamos criar uma coluna com um id aleatório para cada pessoa. Primeiro vamos criar um id intermediário com index que vai ser utilizado para criação do id de cada pessoa.
# Criando a coluna id intermediário com index
df.reset_index(inplace=True)
df.rename(columns={'index':'id'}, inplace=True)Em seguida vamos criar uma função que gera um id aleatório com 8 caracteres.
# Função para criar um id de 8 caracteres aleatório def get_id(): id = ''.join(random.choice(string.ascii_uppercase + string.ascii_lowercase + string.digits) for _ in range(8)) return id
Para finalizar, vamos fazer um loop for passando por cada linha do dataframe e substituindo o id intermediário pelo novo id de 8 caracteres aleatórios.
# Ajustando os id com a função get_id for r in range(df.shape[0]): df['id'].iloc._setitem_with_indexer(r, get_id())
Observe na imagem abaixo que agora identificamos cada pessoa com um ID aleatório. Dessa forma, a identidade das conexões está protegida em cumprimento a LGPD.
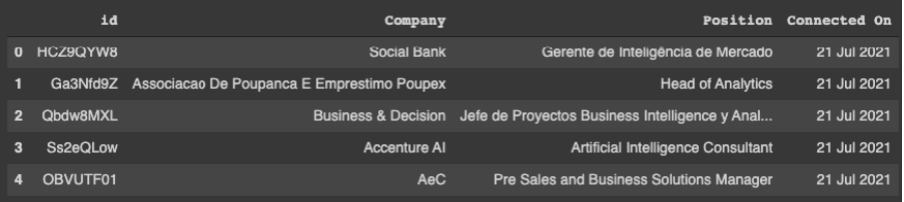
Seguimos com a análise dos dados.
Análise Inicial do Dado do LinkedIn
Um número interessante, pode ser o total de conexões e conseguimos facilmente através do número total de linhas com auxílio da função shape.
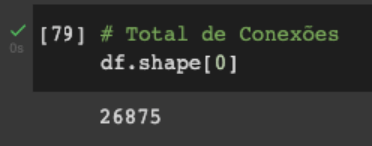
Ainda pensando no número de conexões podemos obter o total por empresa com a função values_counts.
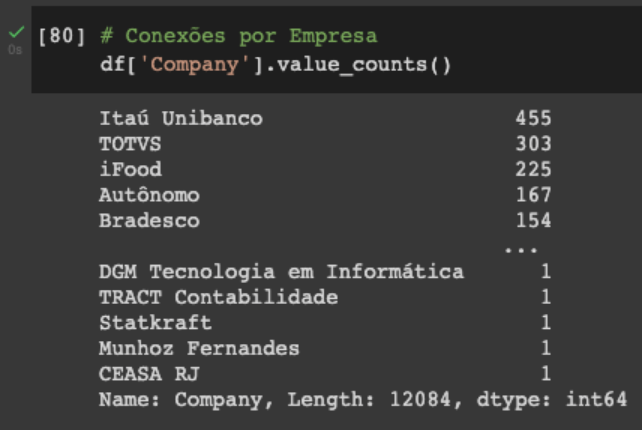
Ainda se pode pensar no número de conexões por cargo e por data de conexão, mas deixo essa brincadeira para vocês. Seguimos para o tratamento de dados para aprofundar nossas análises.
Tratamento dos Dados do LinkedIn
O primeiro tratamento será para deixar todo o texto das colunas com padrão de caixa alta. Seguido de remoção de pontuação, caracteres especiais e espaços duplos.
# Transformando tudo em UPPERCASE
df = df.apply(lambda x: x.astype(str).str.upper())
# Removendo pontuação
df['Position'] = df['Position'].str.replace('[,.:;!?]+', '', regex=True).copy()
# Removendo caracteres especiais
df['Position'] = df['Position'].str.replace('[/<>()|\+\-\–$%&#@\'\"]+', '', regex=True).copy()
# Removendo espaço duplo
df['Position'] = df['Position'].str.replace(' ', ' ', regex=True).copy()O segundo tratamento de dados padronizará a descrição dos cargos. Por exemplo, cientista de dados pleno mudará para cientista de dados ou analista de dados Júnior para analista de dados e assim para os demais cargos do conjunto de dados. Duas funções foram criadas, uma que altera baseada em uma descrição exata do cargo e a outra baseada em um pedaço do cargo.
# Função que altera o cargo baseado em uma string exata
def change_position(position,new_position):
df['Position'].iloc[df.query('Position == @position').index] = new_position
# Função que altera o cargo que contenha a string
def change_position_full(position,new_position):
df['Position'].iloc[df.query('Position.str.contains(@position)', engine='python').index] = new_positionEm seguida, a aplicação das funções criadas acima. Aqui só trouxe apenas um exemplo para cada função, mas o tratamento deve ser realizado para todos os cargos.
# CIÊNCIA DE DADOS
change_position_full('CIENTISTA DE DADOS' ,'CIENTISTA DE DADOS')
change_position('DATA SCIENCE MANAGER' ,'LÍDER CIENTISTA DE DADOS')Função aplicada também para as conexões sem cargos informados. Dessa forma, deixamos a informação explícita.
# SEM CARGO INFORMADO
change_position('NAN' ,'SEM CARGO INFORMADO')Aplicando a função dos cargos mais relevantes do dataset, temos o seguinte top 10 cargos das conexões.

Finalizando o tratamento de dados, partindo para criação de outras colunas para incrementar a análise.
Criação de Novas Colunas
Uma análise interessante, é o agrupamento dos cargos por área. Dessa forma, podemos ter uma visão macro das áreas das conexões.
Para começar vamos criar uma coluna de nome Area no dataframe, em seguida atribuímos OUTRAS para todos os cargos. À medida que formos definindo as áreas dos cargos ajustamos o valor de cada área.
# Criação da coluna Area df['Area'] = 'OUTRAS'
Para esta classificação de área vamos criar duas funções, que recebe o valor do cargo e atribui uma área para o mesmo, da mesma forma que tratamos os cargos, vamos ter duas funções, uma que altera a área baseada em uma descrição exata do cargo e a outra baseada em um pedaço do cargo.
# Função que altera a área baseado em uma string exata
def change_area(position,new_area):
df['Area'].iloc[df.query('Position == @position').index] = new_area
# Função que altera a área que contenha a string exata
def change_area_full(position,new_area):
df['Area'].iloc[df.query('Position.str.contains(@position)', engine='python').index] = new_areaAplicando a função acima, temos o seguinte exemplo: para todo cargo que contém a palavra DADOS será atribuída à área DADOS, para todo cargo que contém a palavra DATA será atribuída à área DADOS e para todo cargo que contém a palavra ANALYTICS será atribuída à área DADOS. Conforme o exemplo apresentado, deve ser feito o mesmo tratamento para demais áreas.
change_area_full('DADOS' ,'DADOS')
change_area_full('DATA' ,'DADOS')
change_area_full('ANALYTICS' ,'DADOS')Outras colunas que criamos são referentes a data de conexão. Através da coluna Connected On criamos uma coluna de dia, uma de mês, uma de ano e uma com valor Ano Mês.
# Criar as colunas dia, mês e ano a partir da Connected On df['Connected Day'] = df['Connected On'].dt.day df['Connected Month'] = df['Connected On'].dt.month df['Connected Year'] = df['Connected On'].dt.year df['Connected YearMonth'] = df['Connected Year'].apply(str) + df['Connected Month'].apply(str).apply(lambda x: x.zfill(2))
Portanto, agora temos o dataset com os dados tratados e com mais algumas informações acrescentadas para nossa análise final. Dessa forma, podemos fazer uma análise mais completa das conexões.
Análise Final dos Dados do LinkedIn
Começando a análise, com a função head observe como ficaram os dados após as tranformações.
Preparando para gerar os gráficos, algumas configurações para melhor visualização dos mesmos. Como tamanhos das legendas, dos gráficos, título entre outras.
# configura parametros de tamanho dos gráficos sns.set_theme(style="whitegrid") plt.rcParams['figure.figsize'] = (20,10) plt.rcParams['xtick.labelsize'] = 10 plt.rcParams['ytick.labelsize'] = 10 plt.rcParams['font.size'] = 15 plt.rcParams['axes.titlesize'] = 20
Análise de Cargos dos Dados do Linkedin
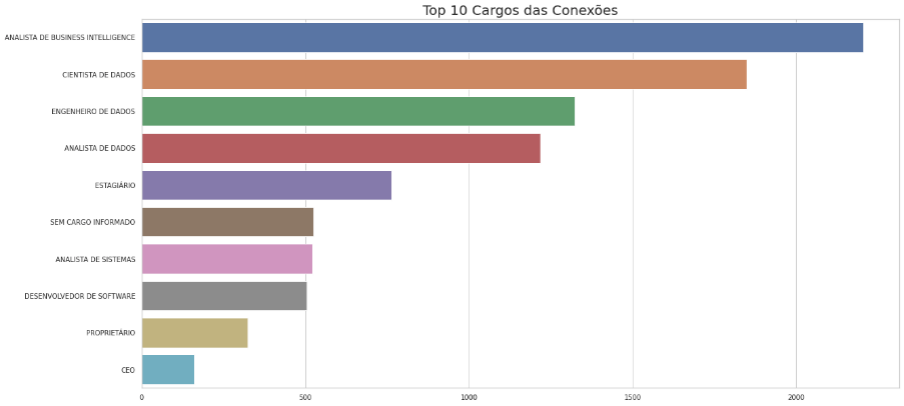
O primeiro gráfico é o top 10 cargos das conexões, com a função barplot do pacote seaborn.
# Gráfico com top 10 cargos das conexões
x = df['Position'].value_counts().head(10).values
y = df['Position'].value_counts().head(10).index
sns.barplot(x=x, y=y)
plt.title('Top 10 Cargos das Conexões')
plt.show()Observe que os quatro primeiros cargos são da área de dados. Se a minha área fosse recursos humanos seriam as minhas melhores conexões? Talvez, se eu fosse um recrutador especializado na área de dados. No final das contas o importante é fazer sentido para você, então, fica a pergunta. Será que está escolhendo as melhores conexões? Para mim a resposta é sim.
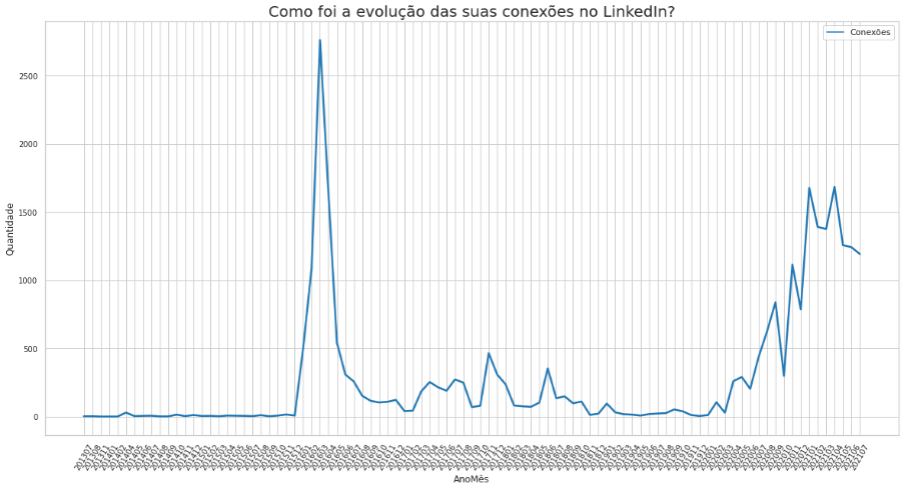
A segunda visualização apresentada, é uma evolução do número de conexões ao longo do tempo. Para tal utilizamos a função lineplot do pacote seaborn.
YearMonth = pd.DataFrame(pd.DataFrame(df['Connected YearMonth'].value_counts())).rename(columns={'Connected YearMonth': 'Conexões'}).sort_index()
# Gráfico de linha com evolução das conexões
sns.lineplot(data=YearMonth,
palette="tab10",
linewidth=2.5,
estimator='sum')
plt.title('Como foi a evolução das suas conexões no LinkedIn?')
plt.xlabel('AnoMês')
plt.xticks(rotation = 60)
plt.ylabel('Quantidade')
plt.show()Análise de Conexões dos Dados do Linkedin
É notável alguns picos de conexões ao longo do tempo. Isso pode ser explicado por alguns motivos, por exemplo, busca por novas oportunidades ou intensidade de utilização da plataforma.
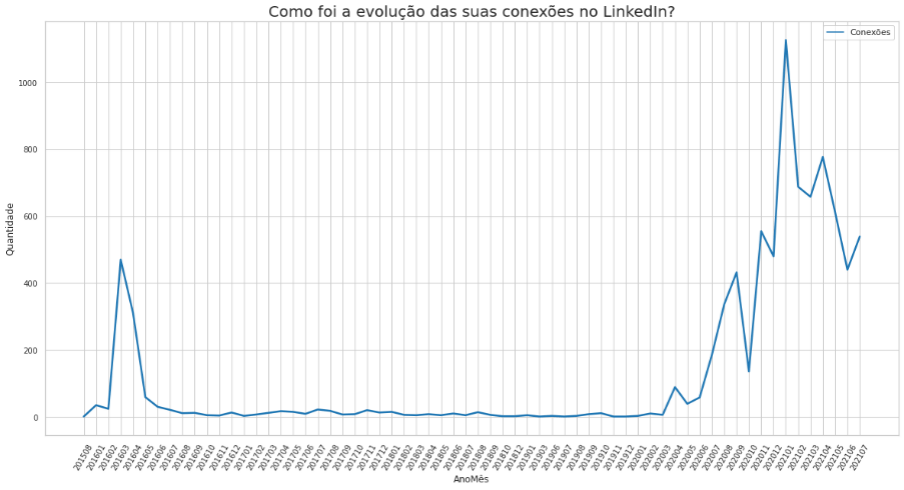
Se aplicamos algum filtro por cargo, empresa ou área podemos ter outras variações e uma mudança completa do número de conexões ao longo do tempo. Observe este outro gráfico abaixo, onde fizemos um filtro pela área de DADOS.
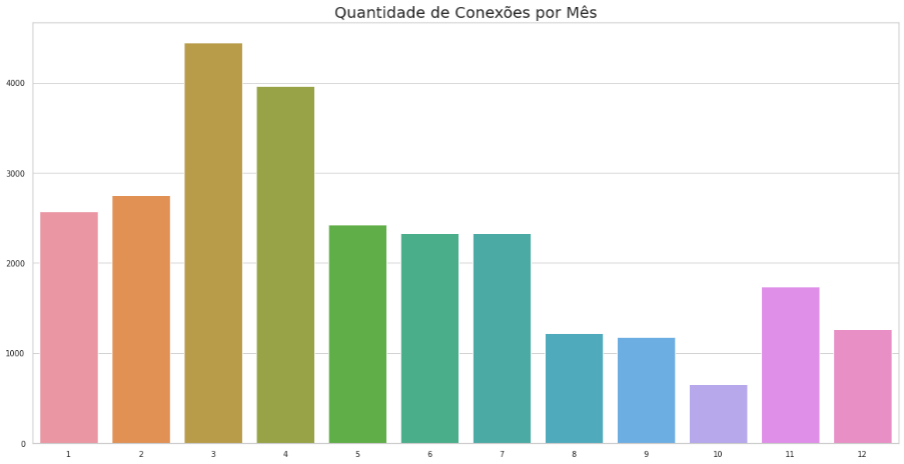
Seguimos para mais uma análise, desta vez o número de conexões em cada mês do ano. É importante ressaltar que nenhum ano foi filtrado. Novamente com a função barplot do pacote seaborn, mas desta vez, invertendo o eixo para barras verticais.
# Gráfico quantidade de conexões por mês
x = df['Connected Month'].value_counts().index
y = df['Connected Month'].value_counts().values
sns.barplot(x=x, y=y)
plt.title('Quantidade de Conexões por Mês')
plt.show()Aqui observamos os meses onde adicionamos mais ou menos conexões. Confesso que não encontrei nenhuma explicação lógica para o mês de março ser o mês com mais conexões e o mês de outubro com menos conexões.
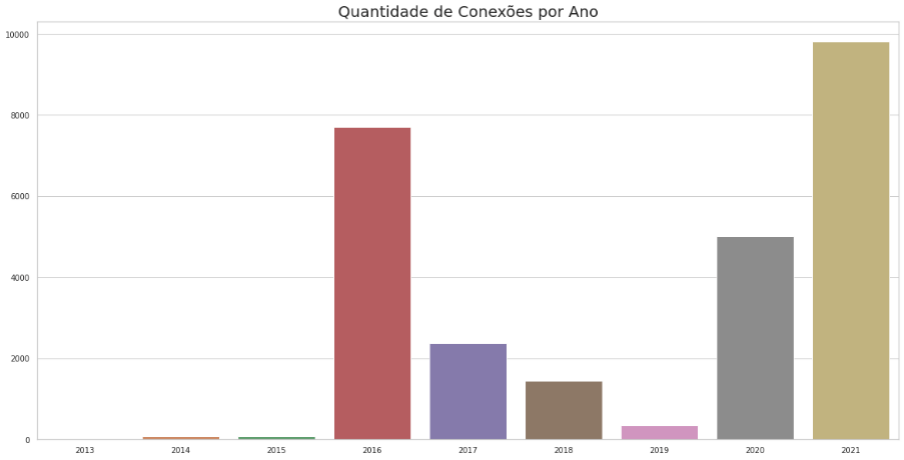
E como foram as conexões por ano? Qual ano fizemos mais ou menos conexões? Essas perguntas vamos responder com gráfico abaixo das evoluções de conexões ao longo dos anos. Também com a função barplot do pacote seaborn.
# Gráfico quantidade de conexões por ano
x = df['Connected Year'].value_counts().index
y = df['Connected Year'].value_counts().values
sns.barplot(x=x, y=y)
plt.title('Quantidade de Conexões por Ano')
plt.show()Aqui podemos observar um decréscimo nos anos de 16 a 19 e a evolução nos anos de 19 a 21. A ausência no primeiro período e a presença no LinkedIn no segundo período podem explicar esses números. Estar presente e interagindo na rede nos faz aumentar o número de conexões de uma forma natural.
Nuvem de Palavras dos Dados do Linkedin
E para concluir a nossa exploração de dados do LinkedIn, um gráfico que particularmente eu gosto bastante, a nuvem de palavras. Aqui vamos utilizar a função WordCloud do pacote wordcloud. Após juntar todos os cargos na variável todos_itens, separando por espaço, plotamos uma nuvem de palavras com os cargos das conexões.
# Gráfico nuvem de palavras com cargos das conexões todos_itens = ' '.join(s for s in df['Position'].values) stop_words = ['sem', 'cargo', 'de', 'da', 'do', 'and', 'e', 'in'] # criar uma wordcloud wc = WordCloud(stopwords=stop_words, background_color="black", width=1600, height=800) wordcloud = wc.generate(todos_itens) # plotar wordcloud fig, ax = plt.subplots(figsize=(15,9)) ax.imshow(wordcloud, interpolation='bilinear') ax.set_axis_off()
Com essa visualização, conseguimos observar os cargos mais presentes nas conexões de uma forma bem interessante, se compararmos com top 10 cargos das conexões é possível notar que faz total sentido. E você prefere o top 10 cargos ou uma nuvem de palavras?

Muito bom em?! Agora faz a mesma análise com os seus dados.
Dados do Linkedin ao Cubo
E assim finalizamos a análise dos dados do LinkedIn. No GitHub do Dados ao Cubo você encontra o notebook completo com essas e outras análises.
Espero que vocês tenham curtido essa análise, compartilhem com a sua rede e não esqueçam de mandar aquele feedback do que você achou do conteúdo. Um abraço e até a próxima.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Análise Exploratória com ML.Net e Jupyter Notebook no Ubuntu
- Análise Exploratória de Dados com Python Parte I
- Análise Exploratória de Dados com Python Parte II
- Google Analytics e o Dados ao Cubo
- Análise de Dados para Detecção de Fraude
- Consultar Dados com Streamlit e o PostgreSQL
- Visualização de Dados com Altair Python
- Pipeline de Dados Airbyte com GA4 e Snowflake
Então, finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
