

Fala galera do mundo dos dados, hoje é dia de trabalhar com data sources no Spark. Continuidade da série Fluxo de Dados com Spark! Agora que já temos o ambiente Spark configurado podemos avançar com os estudos. Os Spark será como nosso motor, ele servirá para processar grandes volumes de dados. Para isso precisamos pegar dados em algum lugar para levar eles após o processamento para outro lugar. Nesta jornada de hoje faremos a primeira etapa que é trabalhar com as origens dos dados.
Dessa forma, iremos apresentar como trabalhar com alguns data sources. Para começar as nossas origens de dados serão arquivos csv, json e um banco de dados relacional. Sem mais delongas vamos à prática com Dados ao Cubo.
Data Sources para Spark
Primeiramente, vamos conhecer as nossas origens de dados.
- Arquivo CSV
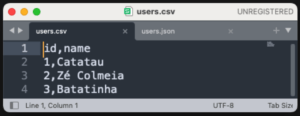
- Arquivo JSON
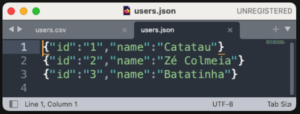
- Banco de dados PostgreSQL
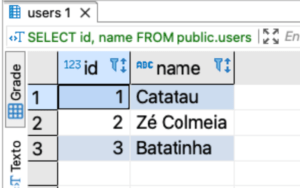
Observe que os dados são os mesmos independente da fonte. O importante neste caso é saber como fazer a leitura de cada um dos data sources.
Arquivo CSV com Spark
Para a leitura do arquivo csv com Spark, criaremos um arquivo Python de nome spark_datasource_csv.py, conforme a imagem abaixo.
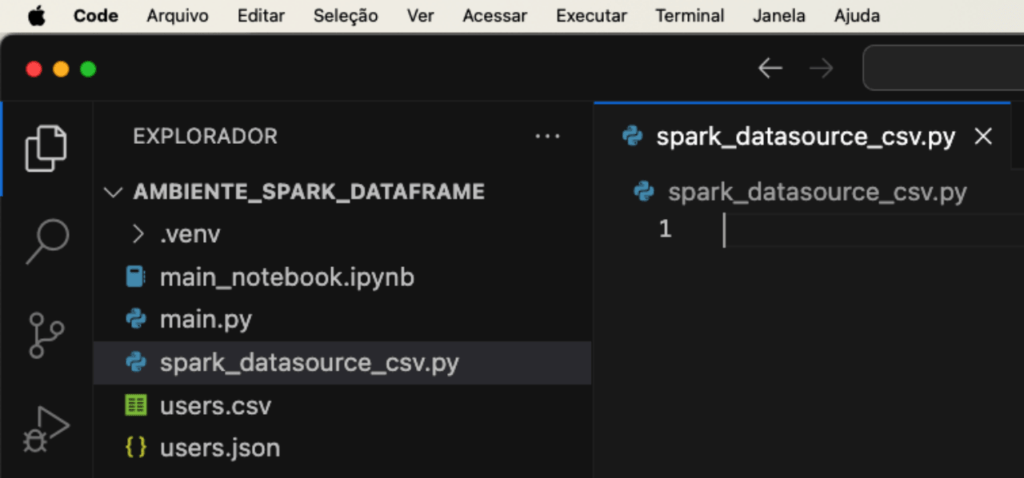
Com o arquivo criado criaremos um código utilizando o PySpark, para fazer os seguintes passos.
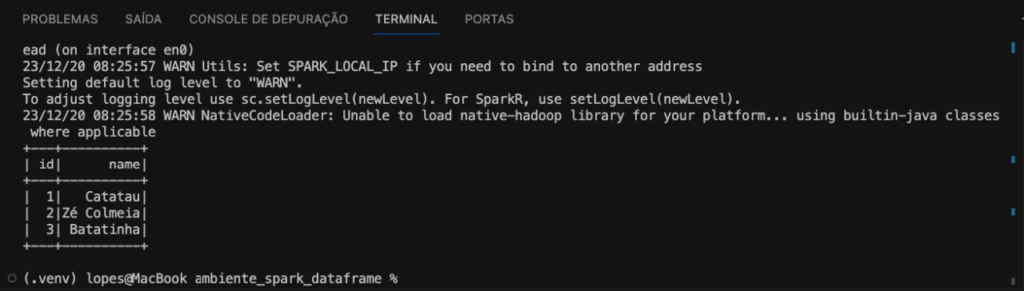
Primeiramente a criação da sessão Spark, a sessão é a base para trabalhar com o Spark e permite que você utilize suas funcionalidades. Em seguida a leitura do arquivo CSV para DataFrame, estamos utilizando a sessão spark para ler um arquivo CSV chamado users.csv e criar um DataFrame chamado df_csv. A opção header, True indica que a primeira linha do CSV contém os nomes das colunas. Finalizando com a exibição do DataFrame, este comando simplesmente exibe o conteúdo do df_csv. É útil para verificar se a leitura do CSV foi feita corretamente.
from pyspark.sql import SparkSession if __name__ == __main__: spark = SparkSession.builder.getOrCreate() df_csv = spark.read.option(header,True).csv(users.csv) df_csv.show()
Então, no geral, este código cria uma sessão Spark, lê um arquivo CSV (users.csv) para um DataFrame e, em seguida, exibe o conteúdo desse DataFrame. Conforme a imagem abaixo.
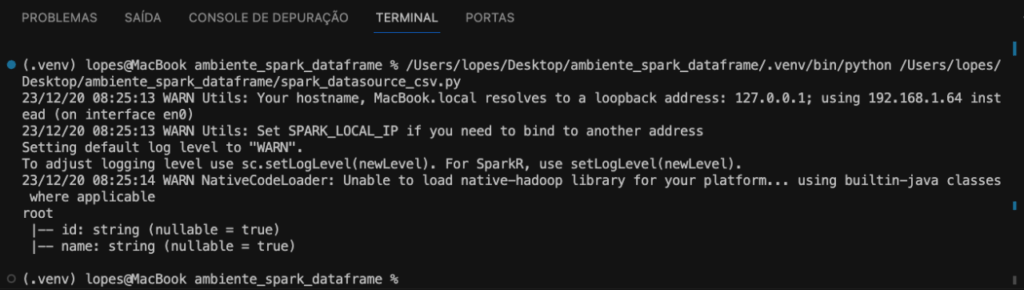
Podemos ainda, imprimir o esquema schema do DataFrame. O esquema descreve a estrutura dos dados no DataFrame, incluindo o nome das colunas e os tipos de dados associados a cada coluna. Para isso utilizamos a função printSchema, conforme código a seguir.
df_csv.printSchema()
Confere o resultado na imagem abaixo.
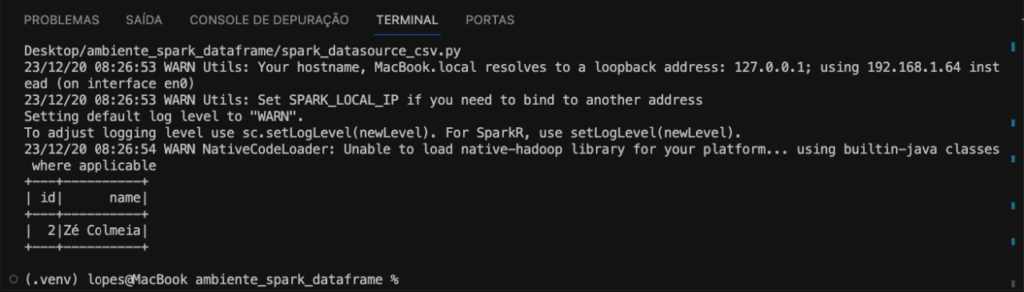
Ainda podemos exibir os dados do DataFrame filtrados. Selecionando apenas algumas linhas através da função de filtro filter. No código fazemos a exibição das linhas que terminam com ia.
df_csv.filter(name like "%ia").show()
E então temos o resultado na imagem a seguir.
Assim fechamos a leitura dos dados de um arquivo csv, vamos conferir agora o arquivo json.
Arquivo JSON com Spark
Agora a leitura do arquivo json com Spark, também criaremos um arquivo Python com nome spark_datasource_json.py, conforme a imagem a seguir.
Arquivo criado faremos um código utilizando o PySpark, para fazer os seguintes passos.
Para começar temos a criação da sessão Spark, lembrando que sessão é a base para trabalhar com o Spark. Na sequência a leitura do arquivo JSON para DataFrame, vamos ler um arquivo JSON chamado users.json e criar um DataFrame chamado df_json. E então a exibição do DataFrame, o comando show simplesmente exibe o conteúdo do df_json. Podemos verificar se a leitura do JSON foi feita corretamente.
from pyspark.sql import SparkSession if __name__ == __main__: spark = SparkSession.builder.getOrCreate() df_json = spark.read.json(users.json) df_json.show()
Então, no geral, este código cria uma sessão Spark, lê um arquivo JSON para um DataFrame e, em seguida, exibe o conteúdo desse DataFrame. Conforme a imagem a seguir.
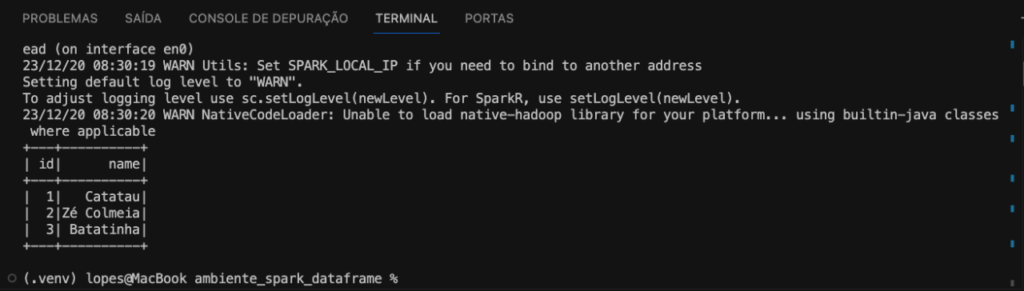
Também podemos imprimir o esquema schema do DataFrame, utilizamos a função printSchema, conforme código a seguir.
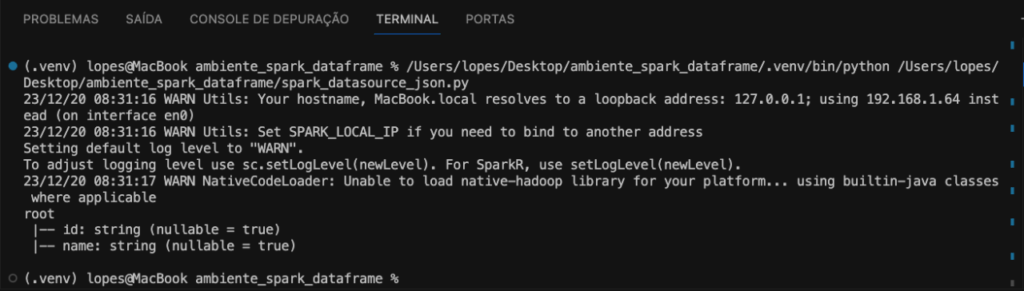
df_json.printSchema()
E então, teremos a imagem abaixo como resultado.
Em seguida faremos a seleção apenas algumas linhas através da função filter. No código abaixo fazemos a exibição das linhas que terminam com ia.
df_json.filter(name like "%ia").show()
A imagem abaixo será exibida.
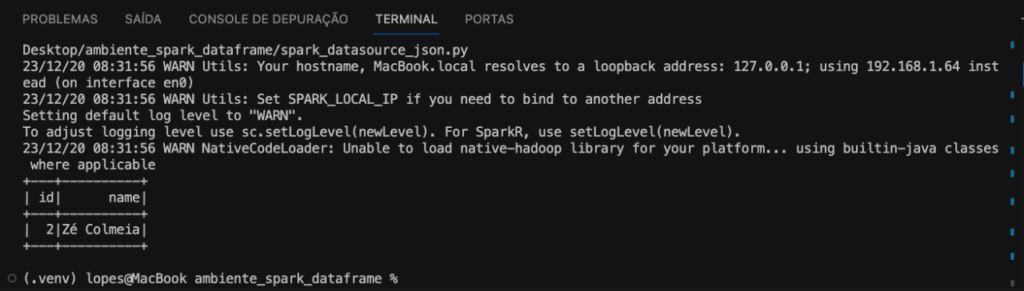
Dessa forma, fechamos a leitura dos dados de um arquivo json, para completar a missão com os data sources agora com um banco de dados como origem.
Banco de Dados PostgreSQL com Spark
Completando as origens, a leitura do banco de dados PostgreSQL com Spark, criaremos outro arquivo Python de nome spark_datasource_jdbc.py, conforme a imagem abaixo.
Com o arquivo criado faremos um código Python com os passos.
Começando com a criação da sessão Spark com configuração adicional para JDBC, estamos criando uma sessão Spark com uma configuração adicional (spark.jars.packages, org.postgresql:postgresql:42.6.0). Essa configuração permite que o Spark use o driver JDBC do PostgreSQL. Em seguida a leitura de dados do PostgreSQL para DataFrame, estamos lendo dados de um banco de dados PostgreSQL. O método jdbc especifica a URL do banco de dados, a tabela desejada public.users, e as propriedades necessárias para a conexão, como usuário e senha. Finalizando com a exibição do DataFrame, este comando exibe o conteúdo do df_jdbc, mostrando os dados que foram lidos do banco de dados PostgreSQL.
from pyspark.sql import SparkSession
if __name__ == __main__:
spark = (SparkSession.builder.config(spark.jars.packages,org.postgresql:postgresql:42.6.0).getOrCreate())
df_jdbc = spark.read \
.jdbc(url="jdbc:postgresql://localhost:5432/postgres",
table="public.users",
properties={"user": "postgres",
"password": "postgres",
driver:org.postgresql.Driver})
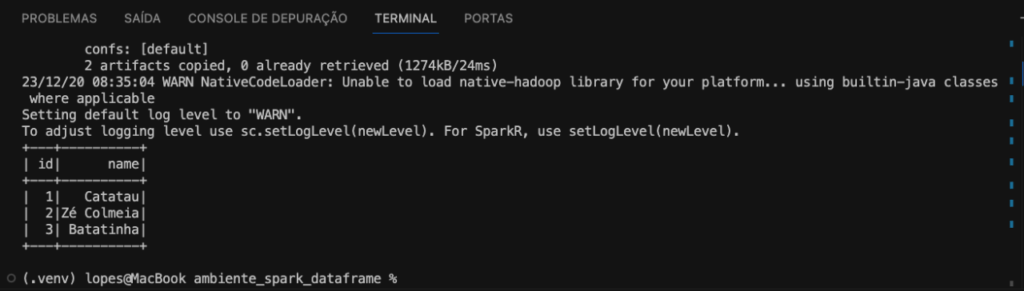
df_jdbc.show()Em resumo, esse código é usado para conectar o Spark a um banco de dados PostgreSQL, ler dados de uma tabela específica e exibir esses dados no formato de DataFrame. Essa é uma maneira de integrar o Spark com bancos de dados usando JDBC. Como resultado temos a imagem abaixo.
Para conferir o esquema schema do DataFrame, utilizamos a função printSchema, conforme código a seguir.
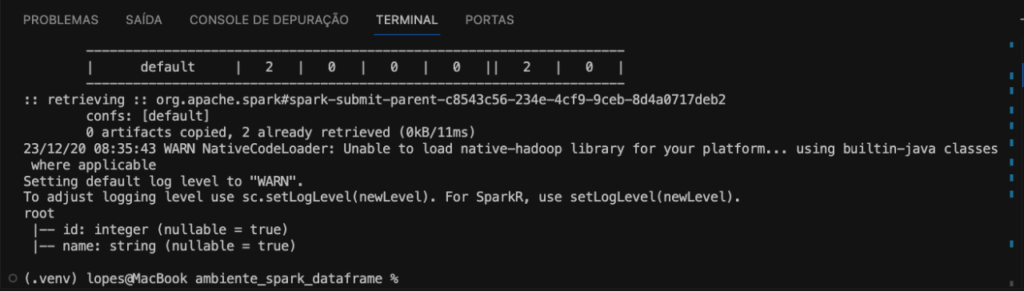
df_jdbc.printSchema()
Na imagem abaixo o schema do DataFrame.
Também faremos a seleção apenas algumas linhas através da função filter. No código abaixo fazemos a exibição das linhas que terminam com ia.
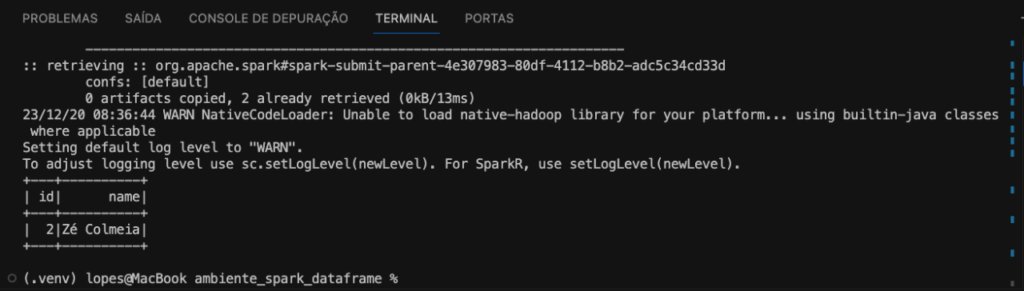
df_jdbc.filter(name like "%ia").show()
Confere na imagem o resultado do DataFrame filtrado.
E então fechamos a leitura de dados de fontes diversas. E aí gostou? Quer mais? Confere todo esse passo a passo de como trabalhar com data sources no Spark em vídeo, no canal do Fluxo de Dados!
Trabalhando com Data Sources no Spark com o Fluxo de Dados
Esse conteúdo é uma parceria com o canal do Fluxo de Dados, lá você confere como trabalhar com data sources no Spark e muito mais.
E então finalizamos mais um post da série Fluxo de Dados com Spark . Fica ligado nos próximos conteúdos que vai ter toda a continuidade de como trabalhar com Spark. Ao final desta série, você estará pronto para embarcar em suas próprias jornadas analíticas usando PySpark. A capacidade de processar dados em escala e realizar análises complexas torna PySpark uma ferramenta valiosa para profissionais que buscam explorar o potencial máximo do big data.
Conteúdos ao Cubo
Por fim, deixo algumas sugestões de conteúdos que você pode encontrar no Dados ao Cubo, sempre falando sobre o mundo dos dados.
- Boas Práticas de Visualização de Dados Parte I
- Boas Práticas de Visualização de Dados Parte II
- Regressão com scikit-learn
- Engenharia de Atributos AKA Feature Engineering Parte I
- Engenharia de Atributos AKA Feature Engineering Parte II
- O Guia do XGBoost com Python
- Análise de Dados com Numpy Python
- Visualizar Dados do PostgreSQL no Metabase
Finalizo com um convite para você ser Parceiro de Publicação Dados ao Cubo e escrever o próximo artigo, compartilhando conhecimento para toda a comunidade de dados. Não esqueça de assinar a nossa Newsletter para ficar por dentro de todas as novidades.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
