

Fala galera do 🌎 dos 🎲🎲🎲! Hoje vamos falar de web scraping e coleta de dados automatizada com Python da série de automatização de tarefas com Python aqui no blog Dados ao Cubo. A coleta de dados é uma parte essencial em muitos projetos, seja para análise de mercado, pesquisa acadêmica ou tomada de decisões estratégicas. No entanto, coletar manualmente dados de páginas web pode ser uma tarefa demorada e suscetível a erros. Sendo assim, neste case, exploraremos como Python pode ser utilizado para automatizar a coleta de dados em páginas web por meio do web scraping, tornando o processo mais eficiente e eficaz.
Problema e Coleta de Dados Automatizada
Suponha que você precisa coletar informações de publicações recentes em determinado blog. Acessar cada página, copiar e colar os dados manualmente pode ser trabalhoso e impraticável, especialmente quando há centenas de blogs a serem analisados. Então, imagina verificar as novas publicações do Dados ao Cubo todo dia ao logo de 6 meses.

Solução para Web Scraping e Coleta de Dados Automatizada
Para tal problema, usando a biblioteca BeautifulSoup em conjunto com a biblioteca Requests, Python oferece uma solução poderosa para web scraping. Assim, com algumas linhas de código, é possível automatizar a coleta de dados das páginas web de interesse e armazená-los de forma estruturada. Tornando o processo simples e prático!
Biblioteca BeautifulSoup Python
A Biblioteca BeautifulSoup em Python é uma ferramenta de análise HTML e XML, projetada para extrair informações de páginas web de forma simples e eficiente. Com sua sintaxe amigável e flexível, a BeautifulSoup permite localizar e capturar dados específicos em páginas HTML, tornando as tarefas de web scraping e análise de dados web mais acessíveis. Seja para coletar informações de sites, realizar análises ou alimentar bancos de dados, a BeautifulSoup é uma escolha bem interessante para quem busca automatizar a extração de dados web com precisão e facilidade.
Biblioteca Requests Python
A Biblioteca Requests em Python é uma ferramenta para realizar requisições HTTP. Projetada para facilitar a interação com APIs web e páginas da internet, a Requests permite que os desenvolvedores enviem solicitações para servidores, obtenham dados de respostas e manipulem as informações retornadas de maneira intuitiva. Com uma sintaxe clara e amigável, a biblioteca é amplamente utilizada para acessar recursos da web, realizar downloads de arquivos, enviar formulários e muito mais. Seja para desenvolvedores experientes ou iniciantes, a Requests é uma ótima escolha para quem busca realizar operações HTTP com facilidade e confiabilidade em projetos Python.
Web Scraping e Coleta de Dados ao Cubo
Então chegou a hora da prática e fazer web scraping e coleta de dados automatizada com Python. Confere o passo a passo na sequência com códigos e comentários.
Passo 1: Instalando as Bibliotecas Necessárias
Primeiramente, começamos instalando as bibliotecas necessárias para web scraping.
!pip install beautifulsoup4 !pip install requests
Passo 2: Importando as Bibliotecas Necessárias
Em seguida, importamos as bibliotecas BeautifulSoup e Requests instaladas no passo anterior.
import requests from bs4 import BeautifulSoup import csv
Passo 3: Obtendo o Conteúdo da Página
Para coletar dados de uma página web, precisamos obter o conteúdo HTML da página. Usando a biblioteca Requests, fazemos uma requisição HTTP à página desejada.
url = "https://www.dadosaocubo.com/"
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
print("Erro ao acessar a página.")
exit()E então, temos na variável html_content o conteúdo da página web dadosaocubo.com que foi acessada.
html_content
Na imagem abaixo é possível ver o conteúdo armazenado na variável.
Portanto temos um código HTML conforme imagem a seguir. Agora é só fazer a coleta do que você precisa na página.
Passo 4: Extraindo os Dados com BeautifulSoup
Agora que temos o conteúdo HTML da página, podemos usar a biblioteca BeautifulSoup para extrair os dados específicos que desejamos coletar. Vamos supor que queremos coletar o título e o link de cada publicação.
soup = BeautifulSoup(html_content, "html.parser")
posts = soup.find_all("div", class_="feat-item")
for post in posts:
name = post.find("h2", class_="entry-title").text.strip()
link = post.find("a")['href']
print("Post:", name)
print("Link:", link)
print("-" * len("Link"+link))Confere o resultado da coleta na imagem abaixo. Se necessário, ainda podemos armazenar esses dados em algum local.
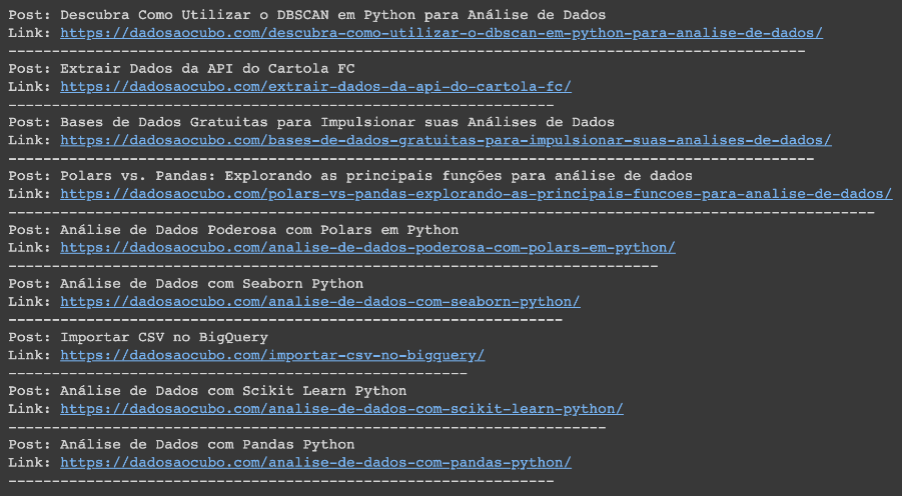
Passo 5: Armazenando os Dados
Por fim, você pode armazenar os dados coletados em um arquivo CSV, Excel ou banco de dados para futuras análises. Confere o código Python abaixo.
with open("dados_coletados.csv", "w", newline="", encoding="utf-8") as csvfile:
fieldnames = ["Post", "Link"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for post in posts:
name = post.find("h2", class_="entry-title").text.strip()
link = post.find("a")['href']
writer.writerow({"Post": name, "Link": link})Dessa forma, temos os dados armazenados em um arquivo csv como apresentado na imagem a seguir.

Web Scraping e Coleta de Dados com Python ao Cubo
Neste case, vimos como Python pode ser usado para automatizar a coleta de dados em páginas web por meio do web scraping. Ao usar as bibliotecas BeautifulSoup e Requests, pudemos extrair informações de páginas de um site de forma rápida e eficiente. A automação da coleta de dados economiza tempo e esforço, permitindo que você concentre seus esforços em análises e tomada de decisões estratégicas. A capacidade de Python de lidar com web scraping torna-o uma ferramenta valiosa para diversos projetos e análises de dados. Não perca as novidades do Dados ao Cubo! Então, fica ligado com a nossa Newsletter. Um abraço e até a próxima!!!
Conteúdos ao Cubo
Então, se você curtiu o conteúdo, aqui no Dados ao Cubo tem muito mais. Então, deixo algumas sugestões de conteúdos que você pode encontrar. Sempre falando sobre o mundo dos dados!
- Time de Dados na Prática
- Etapas para Análise de Dados
- Tipos de Análise de Dados
- Dicas para Visualização de Dados
- Análise de Dados com Airbyte e Metabase
- Importar CSV no PostgreSQL com o DBeaver
- Deploy do Metabase com Docker
Para finalizar, se torne também Parceiro de Publicação Dados ao Cubo. Escreva o próximo artigo e compartilhe conhecimento para toda a comunidade de dados.

Apaixonado por dados e tecnologia ❤️ , criando soluções com dados 📊 📈 , desde 2015, sempre buscando tornar os processos orientados! Com formação em Engenharia da Computação 💾 , MBA Gestão da Informação e Business Intelligence e Especialização em Data Science.
Também atuo como professor na área de dados. Nas horas vagas crio modelos de Machine Learning 🤖 com Python em desafios do Kaggle e escrevo no Dados ao Cubo sobre o mundo dos dados 🎲 !
Compartilhando conhecimentos sempre 🚀
